









一、保存自己搭建网络的模型
在前面简单的神经网络基础上填加了保存模型的代码。
代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次100张照片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 定义两个placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# 创建一个简单的神经网络,输入层784个神经元,输出层10个神经元
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x, W) + b)
# 二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# 使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
# 初始化变量
init = tf.global_variables_initializer()
# 结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1)) # argmax返回一维张量中最大的值所在的位置
# 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for epoch in range(11):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
# 保存模型
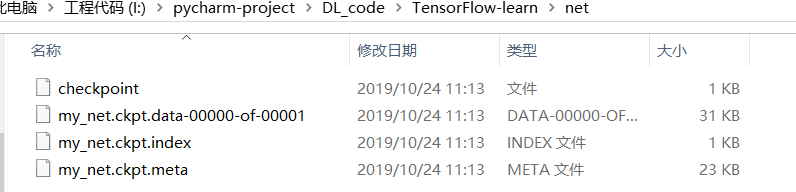
saver.save(sess, 'net/my_net.ckpt')
运行结束后,在主文件夹下会有一个net文件夹,里面存放的就是网络的参数。
二、导入保存的模型
前面都一样,在简单神经网络的基础上,后面加入导入模型的代码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 每个批次100张照片
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
# 定义两个placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# 创建一个简单的神经网络,输入层784个神经元,输出层10个神经元
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x, W) + b)
# 二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# 使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
# 初始化变量
init = tf.global_variables_initializer()
# 结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1)) # argmax返回一维张量中最大的值所在的位置
# 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
# 没有导入模型时的准确率
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}))
# 导入模型
saver.restore(sess,'net/my_net.ckpt')
# 导入模型后的准确率
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}))
运行结果如下:
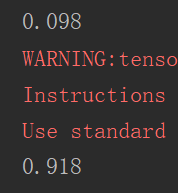
可以看到模型加入前后准确率有着巨大的差别。
三、下载GoogLeNet网络(inception-v3)并查看结构
代码如下:
import tensorflow as tf
import os
import tarfile
import requests
# inception模型下载地址(参数训练好的模型)
inception_pretrain_model_url = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz'
# 模型存放地址,如果该地址不存在就创建一个
inception_pretrain_model_dir = "inception_model"
if not os.path.exists(inception_pretrain_model_dir):
os.makedirs(inception_pretrain_model_dir)
# 获取文件名,以及文件路径
filename = inception_pretrain_model_url.split('/')[-1]
filepath = os.path.join(inception_pretrain_model_dir,filename)
# 下载模型
if not os.path.exists(filepath):
print("download:",filename)
r = requests.get(inception_pretrain_model_url,stream=True)
with open(filepath,'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print("finish:",filename)
# 解压文件
tarfile.open(filepath,'r:gz').extractall(inception_pretrain_model_dir)
# 模型结构存放文件
log_dir = 'inception_log'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# classify_image_graph_def.pb为Google训练好的模型
inception_graph_def_file = os.path.join(inception_pretrain_model_dir,'classify_image_graph_def.pb')
with tf.Session() as sess:
# 创建一个图来存放Google训练好的模型
with tf.gfile.FastGFile(inception_graph_def_file,'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def,name='')
# 保存图的结构
writer = tf.summary.FileWriter(log_dir,sess.graph)
writer.close()
需要用到requests库,需要提前安装好。
运行结束后,在主文件夹下多出两个文件夹:
在inception_model文件夹中是模型的压缩包以及解压后的一些文件:
classify_image_graph_def.pb就是inception-v3的模型。
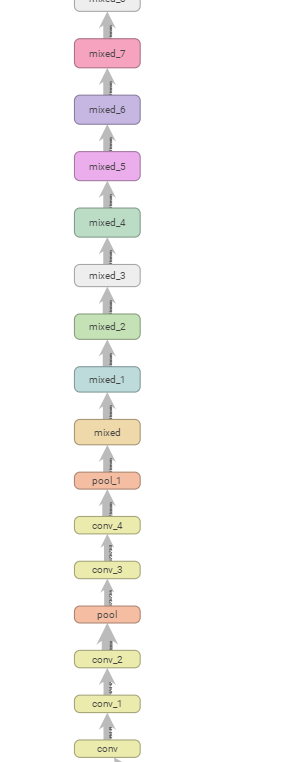
在inception_log文件夹中是inception-v3的网络结构:

我们可以通过命令行的方式使用tensorboard打开它:

四、使用inception-v3进行图像识别
代码如下:
import tensorflow as tf
import os
import numpy as np
import re
from PIL import Image
import matplotlib.pyplot as plt
class NodeLookup(object):
# 初始化两个路径
def __init__(self):
label_lookup_path = 'inception_model/imagenet_2012_challenge_label_map_proto.pbtxt'
uid_lookup_path = 'inception_model/imagenet_synset_to_human_label_map.txt'
self.node_lookup = self.load(label_lookup_path, uid_lookup_path)
def load(self, label_lookup_path, uid_lookup_path):
# 加载分类字符串n********对应分类名称的文件
proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines()
uid_to_human = {} # 建立一个字典
# 一行一行读取数据
for line in proto_as_ascii_lines :
# 去掉换行符(换行符没什么作用)
line=line.strip('\n')
# 按照'\t'分割,(**map.txt文件中编号和后面的描述之间相隔一个tab键的空格距离)
parsed_items = line.split('\t')
# 获取分类编号(第一列编号)
uid = parsed_items[0]
# 获取分类名称 (第二列描述)
human_string = parsed_items[1]
# 保存编号字符串n********与分类名称映射关系(键值对)
uid_to_human[uid] = human_string
# 加载分类字符串n********对应分类编号1-1000的文件
proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines()
node_id_to_uid = {} # 建立一个字典
for line in proto_as_ascii:
if line.startswith(' target_class:'):
# 获取分类编号1-1000
target_class = int(line.split(': ')[1]) # 冒号+空格进行切分,并保存分类编号
if line.startswith(' target_class_string:'):
# 获取编号字符串n********
target_class_string = line.split(': ')[1] # 冒号+空格进行切分,并保存类别编号字符串
# 保存分类编号1-1000与编号字符串n********映射关系
node_id_to_uid[target_class] = target_class_string[1:-2]
# target_class_string[1:-2]--》从第二个位置开始到倒数第二个位置结束,
# 也就是"n01443537"中的n01443537,即去掉了引号
# 建立分类编号1-1000对应分类名称的映射关系,也就是联立上面那两个字典
node_id_to_name = {} # 新字典
for key, val in node_id_to_uid.items(): # 获取第二个字典的键值对,再利用n********带入到第一个字典
# 获取分类名称
name = uid_to_human[val]
# 建立分类编号1-1000到分类名称的映射关系
node_id_to_name[key] = name
return node_id_to_name
# 传入分类编号1-1000,返回分类名称
def id_to_string(self, node_id):
if node_id not in self.node_lookup:
return ''
return self.node_lookup[node_id]
# 创建一个图来存放google训练好的模型
with tf.gfile.FastGFile('inception_model/classify_image_graph_def.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') # 给图起个名字
# 遍历目录
for root,dirs,files in os.walk('images/'):
# 遍历存放图片的文件夹images的图片,root是根目录,dir是子目录,files是图片文件
for file in files:
# 载入图片
image_data = tf.gfile.FastGFile(os.path.join(root,file), 'rb').read() # root是路径,file是图片的文件名
# 传入图片进行计算,图片格式是JPG,predictions是分类结果
predictions = sess.run(softmax_tensor,{'DecodeJpeg/contents:0': image_data})
predictions = np.squeeze(predictions) # 把二维的结果转为一维数据,存在一个列表里
# 打印图片路径及名称
image_path = os.path.join(root,file)
print(image_path)
# 显示图片
img=Image.open(image_path)
plt.imshow(img)
plt.axis('off')
plt.show()
# 排序,分类概率大的排在前面,取前五个
top_k = predictions.argsort()[-5:][::-1] # 本来argsort是从小到大,然后[::-1] 倒序,变为从大到小
node_lookup = NodeLookup()
for node_id in top_k:
# 获取分类名称
human_string = node_lookup.id_to_string(node_id)
# 获取该分类的置信度,置信度越高越确定属于这个分类
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score)) # 分类名称与置信度打印出来
print() # 换行
对于imagenet_2012_challenge_label_map_proto.pbtxt文件:

target_class后面的数字代表目标的分类(inception做的是1000个分类),target_class_string后面的字符串对应于文件imagenet_synset_to_human_label_map.txt里的内容:

左边是类别编号字符串,右边是对编号(分类)的描述。
先在主目下创建新文件夹images,然后下载几张图片放进去,用于识别。

运行结果:

总体的结果:
总共15张图片,预测正确的有11个(按照置信度最大的那个作为预测的类别),不太准确的有3个,预测错误的有一个。整体看来效果不错,而且运算速度较快。














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









