









一、非线性回归模型
#非线性回归模型
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-0.5,0.5,200) #生成200个从-0.5到0.5均匀分布的随机点
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis] #把一维的数据变成二维的,也就是200行一列
noise = np.random.normal(0,0.02,x_data.shape) #生成一些噪点,形状和x_data的一样
y_data = np.square(x_data)+noise #y=x^2+随机值
#定义两个占位符
x = tf.placeholder(tf.float32,[None,1]) #行不指定,列为一列
y = tf.placeholder(tf.float32,[None,1]) #行不指定,列为一列
#构造一个简单的神经网络
#中间层
Weights_L1 = tf.Variable(tf.random_normal([1,10])) #定义权重,值初始化为随机的一个数,形状为1行10列,输入层1个神经元,中间层10个神经元
biases_L1 = tf.Variable(tf.zeros([1,10])) #定义偏置,初始化为0,形状也为1行10列
Wx_plus_b_L1 = tf.matmul(x,Weights_L1) + biases_L1 #w*x+b
L1 = tf.nn.tanh(Wx_plus_b_L1) #激活函数
#输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2 = tf.matmul(L1,Weights_L2) + biases_L2 #这一层的输入是L1
prediction = tf.nn.tanh(Wx_plus_b_L2)
#代价函数
loss = tf.reduce_mean(tf.square(y-prediction)) #平方代价函数,计算误差的平方,再求它的平均值
#梯度下降法训练
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #梯度下降法最小化loss的值
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #变量初始化
for _ in range(2000): #迭代训练
sess.run(train_step,feed_dict={x:x_data,y:y_data}) #传入数据
#获得预测值
prediction_value = sess.run(prediction,feed_dict={x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data) #将x,y以散点图的方式画出来
plt.plot(x_data,prediction_value,'r-',lw=5) #红色实线画出预测曲线,线的宽度为5
plt.show() #显示这两个图像
输出结果:

散点就是x_data和y_data,红线就是我们的预测曲线,看起来还是挺符合的。
关于 plt.figure():

二、简单版MNIST手写数字识别
2.1基础知识介绍
MNIST数据集包含60,000个示例的训练集以及10,000个示例的测试集.。每一张图片包含28×28个像素,把这一个数组展开成一个向量,长度是28×28=784。因此在MNIST训练数据集中mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。图片里的某个像素的强度值介于0-1之间,黑为1,白为0。

MNIST数据集的标签是介于0-9的数字,我们要把标签转化为“one-hot vectors” 。一个onehot向量除了某一位数字是1以外,其余维度数字都是0,比如标签0将表示为([1,0,0,0,0,0,0,0,0,0]), 标签3将表示为([0,0,0,1,0,0,0,0,0,0]) ,即数字x就是第x个位置为1,其余否为0。(从0开始数)因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。

接下来就是搭建一个神经网络来识别手写数字。

我们知道MNIST的结果是0-9,我们的模型可能推测出一张图片是数字9的概率是80%,是数字8的概率是10%,然后其他数字的概率更小,总体概率加起来等于1。这是一个使用softmax回归模型的经典案例。 softmax模型可以用来给不同的对象分配概率。
softmax函数:
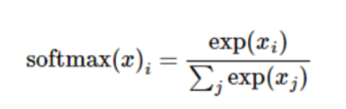
一个例子:

2.2 代码实现
# MNIST手写数字识别(简单版)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True) # 载入数据放在当前路径
sess = tf.InteractiveSession()
batch_size = 100 # 每个批次的大小
# n_batch = mnist.train.num_example # 一共有多少批次
n_batch = 5000
# 定义两个占位符
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
# 创建一个神经网络
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
# 二次代价函数
loss = tf.reduce_mean(tf.square(y-prediction))
# 梯度下降
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
tf.global_variables_initializer().run()
correct_prediction = tf.equal(tf.arg_max(y,1),tf.arg_max(prediction,1))
# equal()两个值相等返回true,否则false
# arg_max返回一维张量中最大值的位置,对于y,里面是1个1和9个0,最大的那个位置就是该数字,比如第2个位置是1,则第二个位置最大,则该数字就是2
# 对于prediction来说,返回最大的概率的那个位置,其实同样也就是预测的数字。如果这两个值相等说明预测正确了.
# 总体的结果存放在一个布尔型列表中
# 准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# cast :将布尔类型转换为float32类型,然后reduce_mean:求平均值.true转为1.0,false转为0.0
for epoch in range(20): #训练20次
for batch in range(n_batch): # 循环总共的批次
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 取出100张图片,数据保存在batch_xs,标签保存在batch_yx,下一次再取出100张图片。
train_step.run({x:batch_xs,y:batch_ys}) #将数据喂进去训练
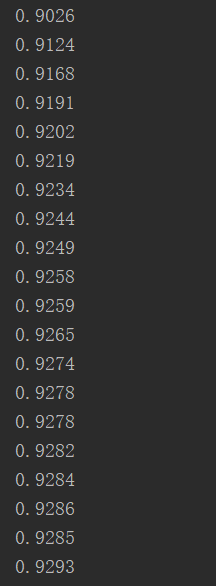
print(accuracy.eval({x: mnist.test.images, y: mnist.test.labels})) #输出正确率
数据集放在和程序一个目录下,如果目录下没有数据集,会自动下载。
输出结果:
关于accuracy.eval():
eval() 其实就是tf.Tensor的Session.run() 的另外一种写法。
with tf.Session() as sess:
print(accuracy.eval({x:mnist.test.images,y: mnist.test.labels}))
with tf.Session() as sess:
print(sess.run(accuracy, feed_dict{x:mnist.test.images,y: mnist.test.labels}))
这俩个代码段的作用是一样的。但是要注意的是,eval()只能用于tf.Tensor类对象,也就是有输出的Operation。对于没有输出的Operation, 可以用.run()或者Session.run()。Session.run()没有这个限制。
2.3 改进的方向
(1)每个批次的大小,改为50或者200
(2)多加几个隐藏层
(3)改下参数w和b的初始值,本文是0,或者改为随机值,1等
(4)改下神经元激活函数
(5)增加神经元数量
(6)改下代价函数,使用交叉熵
(7)改下梯度下降法的学习率
(8)改优化方法
(9)增加训练次数














 5067
5067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









