







1、基本知识
全概率公式:Bi是样本空间的划分,A代表一个事件

贝叶斯公式:
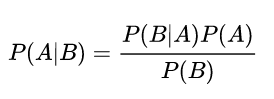
朴素贝叶斯分类:想象成一个由果索因的过程,一般日常生活中我们常常容易求得的是P( B | A)
而真正应用时,P( A | B)更具有现实意义,就比如A代表得肺癌,B代表长期吸烟,根据病人吸烟的概率去求得患癌症的概率时更有意义的。

所以在使用朴素贝叶斯进行分类时,B代表类别,就需要求出最大的 p(B | A)
综上:y为算法模型输出的预测值
2、朴素贝叶斯分类:
2.1算法步骤
1、设 x={a1,s2,....,am}为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合C={y1,y2,...,yn}
3、计算P{ y1|x },P{ y2|x },...,P{ yn|x }
4、如果
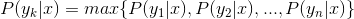
,则 yk为x的类别
2.2主要分类
高斯朴素贝叶斯:特征是连续变量,比如人的身高

多项式朴素贝叶斯:特征是离散变量
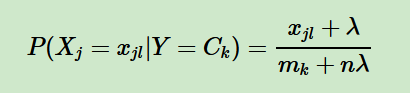
伯努利朴素贝叶斯:特征是布尔变量
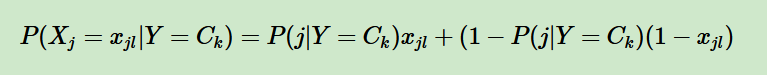
3、文档分类步骤
3.1 训练集->文本预处理(文本分词,去停用词)->特征提取->文本表示->分类器
在进行分档分词时调用工具包进行:英文NTLK包。中文jieba包(分词其实就是对文字进行切割,组成有用的词语,比如“老”和“师”只有组合在一起才有含义);jieba中主要有的三种模式:
精确模式:将句子最精确地分开,适合用于文本分析。
全模式:把所有可分地词都分出来,速度快,但不根据语义分词。
搜索引擎模式:在精确模式基础上,对长词再次进行切分。
常用方法:
jieba.cut(name,cut_all=true) name为待分词地文本,cut_all表示是否为全模式
jieba.cut_for_search(name) 搜索引擎模式下进行分词
jieba.load_userdict(dict) dict表示要添加地自定义字典名
jieba.analyse.extract_tags(sentence,topk) 提取关键字,sentence为待提取地文本,topk为提取地关键字数量。
去停用词:加载停用词表(停用词表示一些频繁出现但是意义不大的词语,比如“是” “的”);计算单词的权重,选出来的分词就可以视作特征,可调用sklearn来实现;
3.2应用朴素贝叶斯进行分类
在实际应用朴素贝叶斯分类器的时候,都是通过调用相关库来进行计算,而不是自己把整个算法编出来。导入语句:
from sklearn.naive_bayes import MultinomialNB
然后需要做预测和计算准确率。















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









