






onnxruntime进行推理的步骤及经验
首先,进行推理时要打开模型获取信息。
- 输入名称和输出名称:
下载一个Netron软件,可以可视化模型,点击任意输入,然后右边会出来输入名称和类型:
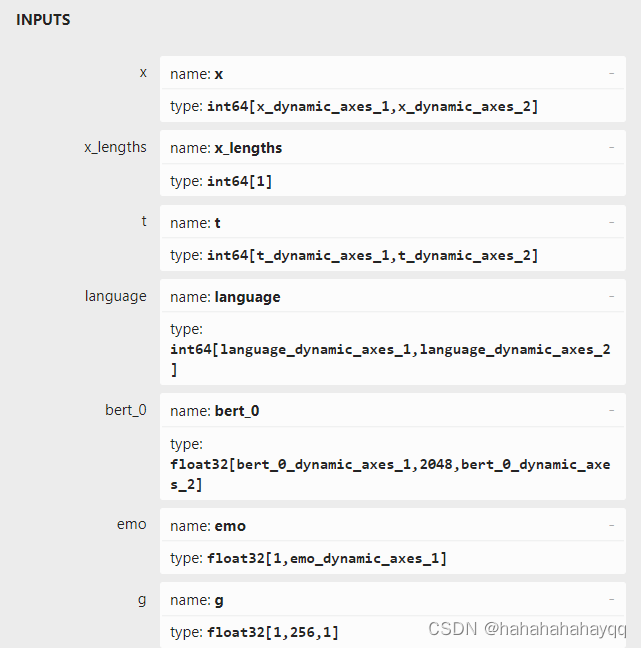
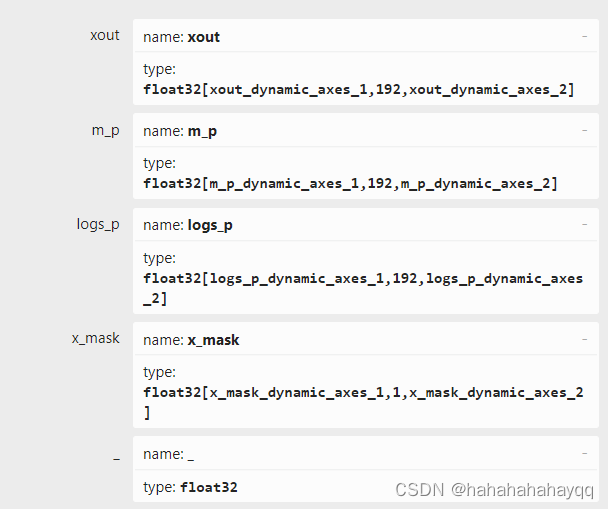
代码里要写对应,C++版本里面代码就是:
// 输入名称
std::vector<const char*> inputNames = { "x", "x_lengths", "t", "language", "bert_0", "emo", "g" };
// 输出名称
std::vector<const char*> outputNames = { "xout", "m_p", "logs_p", "x_mask","_"};
- 传进数据,要根据输入维度,输入数据的data和size数据,例如第一个输入是int64数据类型,构建的代码应该是:
std::vector<Value> inputTensors_enc_p;
inputTensors_enc_p.push_back(Ort::Value::CreateTensor<int64_t>(memory_info, x.data(), x.size(), XShape.data(), XShape.size()));
注意,如果输入是float64的,在C++里面要使用double类型代替Ort::Value::CreateTensor<int64_t>里面的int64_t,
Ort::Value::CreateTensor<double>
- 构建session
env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "test");
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
enc_p = Ort::Session(env, "your_path", session_options);
- 推理
auto enc_rtn = enc_p.Run(Ort::RunOptions{ nullptr }, inputNames.data(), inputTensors_enc_p.data(), inputTensors_enc_p.size(), outputNames.data(), outputNames.size());
- 想要获得输出,例如第一个,可以通过下面方式获得,要注意类型
const float* xout_f = enc_rtn[0].GetTensorData<float>();
//const float* encrawOutput2 = enc_rtn[1].GetTensorData<float>();
size_t xout_f_floatacounts = enc_rtn[0].GetTensorTypeAndShapeInfo().GetElementCount();
std::vector<float> xout(xout_f, xout_f + xout_f_floatacounts);
















 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









