







相关资料
因为自己学习过相关理论知识,但是从来没有用代码实现过,所以想开一个专题专门锻炼自己实践。
1. 语言:python
2. 代码参考: https://github.com/Hallao0/python-machine-learning-book
3. 书籍参考: machine learning book
配置环境
- 系统 windows 64-bits
- python 版本 3.6.0 64-bits
官网上下载的不知道为什么总是32位的,后来百度“python 64”才能找到64位的 - Anaconda3 4.4.0 64-bits
安装成功Anaconda以后,用管理员身份打开“Anaconda Prompt”. 然后依次
conda install packageNamePakages包括:
* Numpy
* SciPy
* scikit-learn
* matplotlib
* pandas
实现perceptron
原理
如果是线性可分的场景:
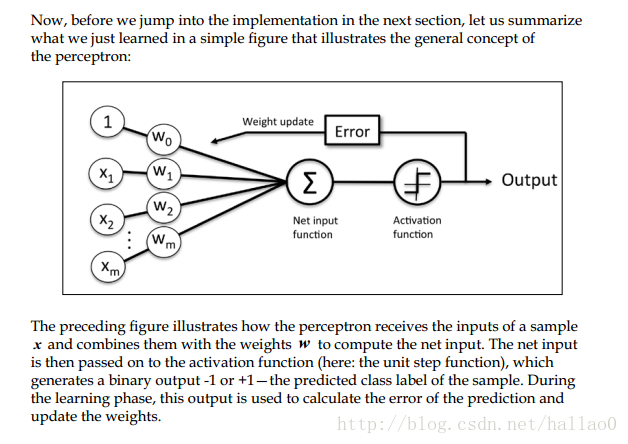
以预测的y与真实的y的差值 按照learning rate的倍速更新weights的值:
Δwj=η(y(i)−y^(i))X(i)j
对于每个training sample
X(i)
:
1. 计算预测值
y^
2. 更新weights
实现
输入:
* feature数据集: x
* classification 数据集 y
* learning rate eta
* 迭代次数 n_iter
输出 :
* 分类模型
* 预测
import numpy as np
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
#X:50x2, shape是(50L,2L),shape[1]=2
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
#zip:将第i个X与第i个y合并成第i个tuple
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
#where(condition,(yes)A,(no)B)
return np.where(self.net_input(X) >= 0.0, 1, -1)测试
读数据
>>> import pandas as pd
>>> df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
>>> df.tail()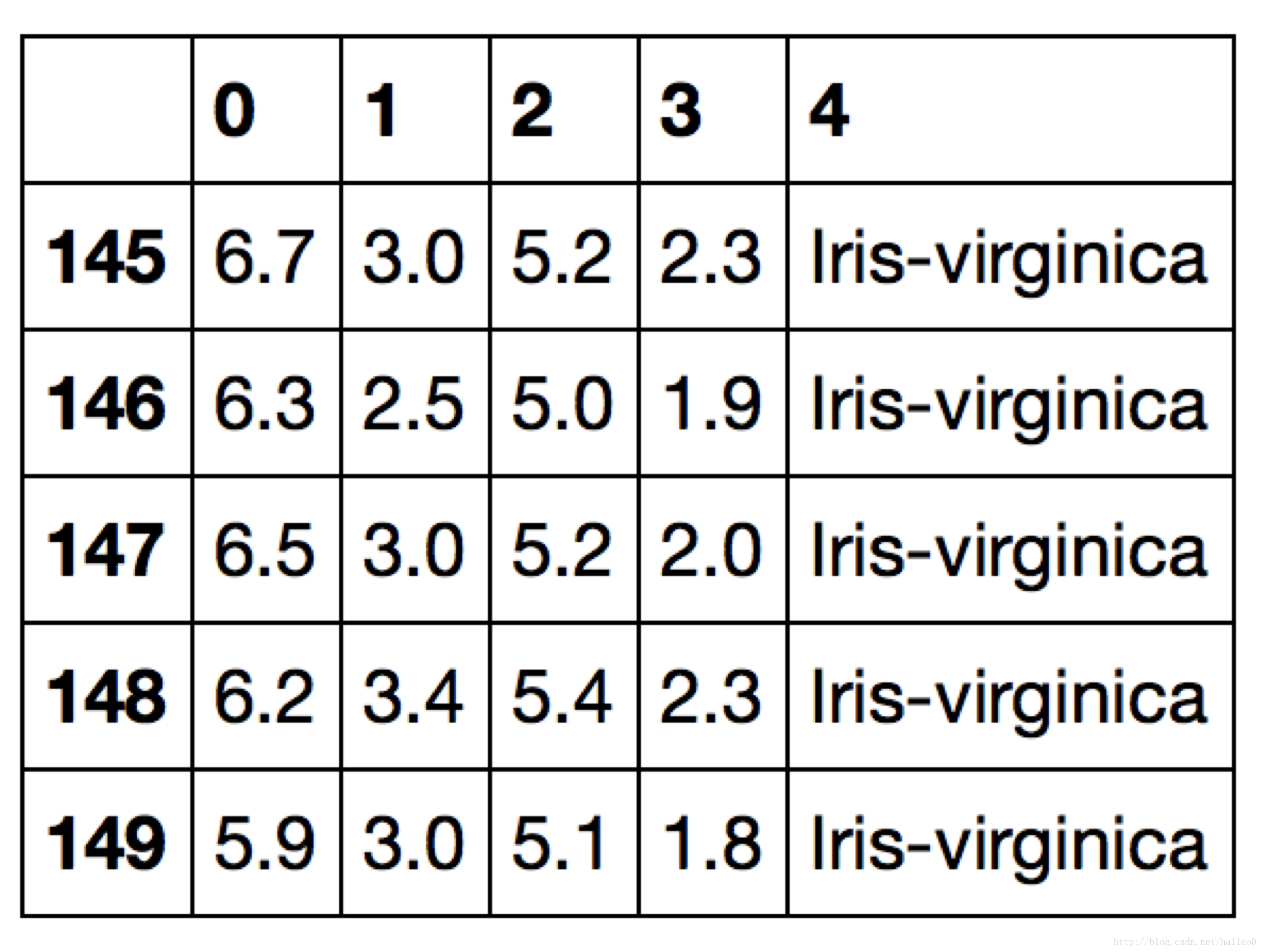
这是一个花的数据集,前四列为花的特征,第五列为花名(种类一共有两种:versicolor和setosa)我们取第一列和第三列为x,第五列为y
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> y = df.iloc[0:100, 4].values
>>>> y = np.where(y == 'Iris-setosa', -1, 1)
>>> X = df.iloc[0:100, [0, 2]].values
>>> plt.scatter(X[:50, 0], X[:50, 1],
... color='red', marker='o', label='setosa')
>>> plt.scatter(X[50:100, 0], X[50:100, 1],
... color='blue', marker='x', label='versicolor')
>>> plt.xlabel('petal length')
>>> plt.ylabel('sepal length')
>>> plt.legend(loc='upper left')
>>> plt.show()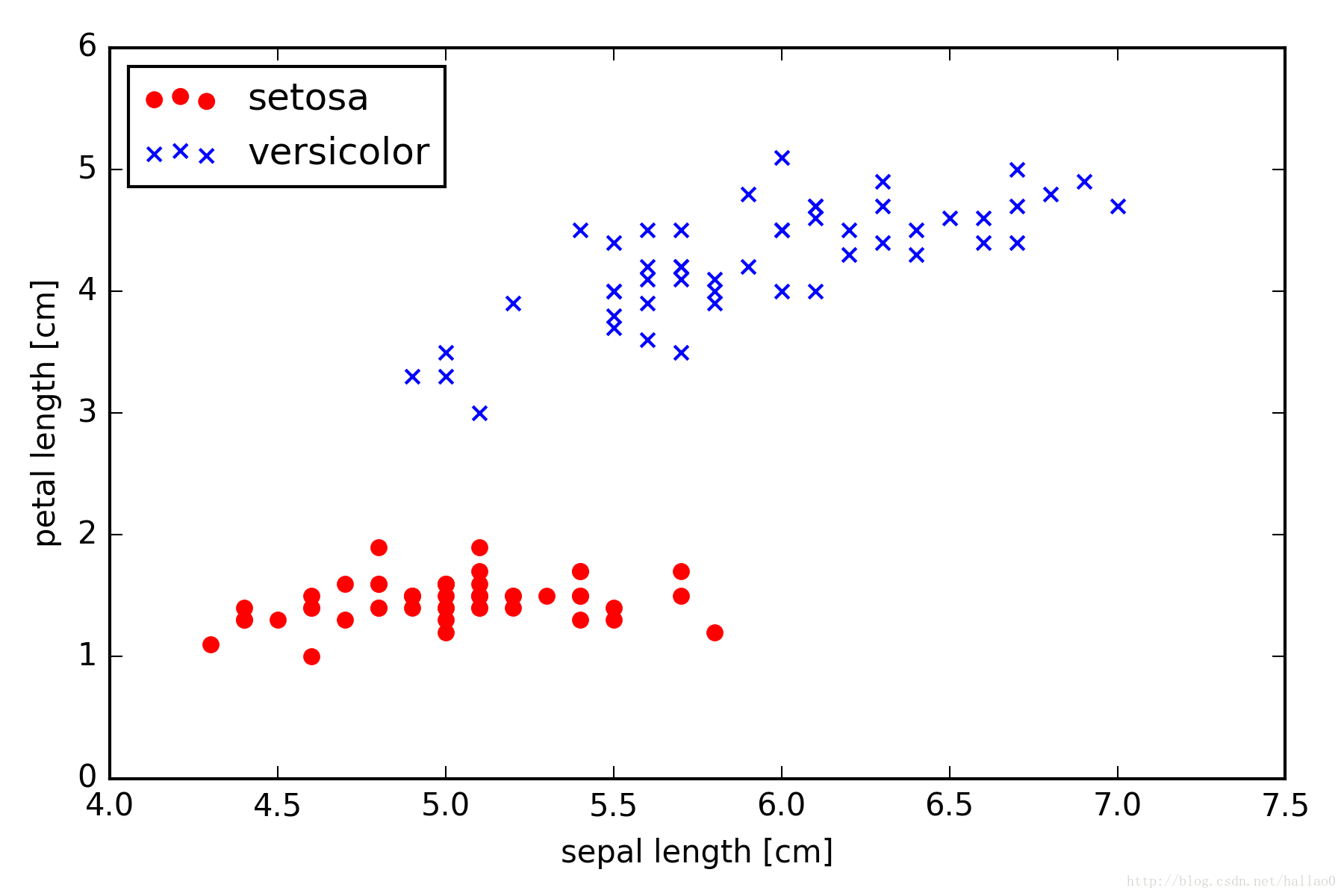
建模
先把Perceptron class 保存为Perceptron.py文件,然后在命令行里from Perceptron import Perceptron. 如果Perceptron.py里面有bug, 改完无法重新加载最新版本,所以最简单粗暴的办法就是讲最新修订版的另存为新的文件名再import一遍。
>>> ppn = Perceptron(eta=0.1, n_iter=10)
>>> ppn.fit(X, y)
>>> plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o')
>>> plt.xlabel('Epochs')
>>> plt.ylabel('Number of misclassifications')
>>> plt.show()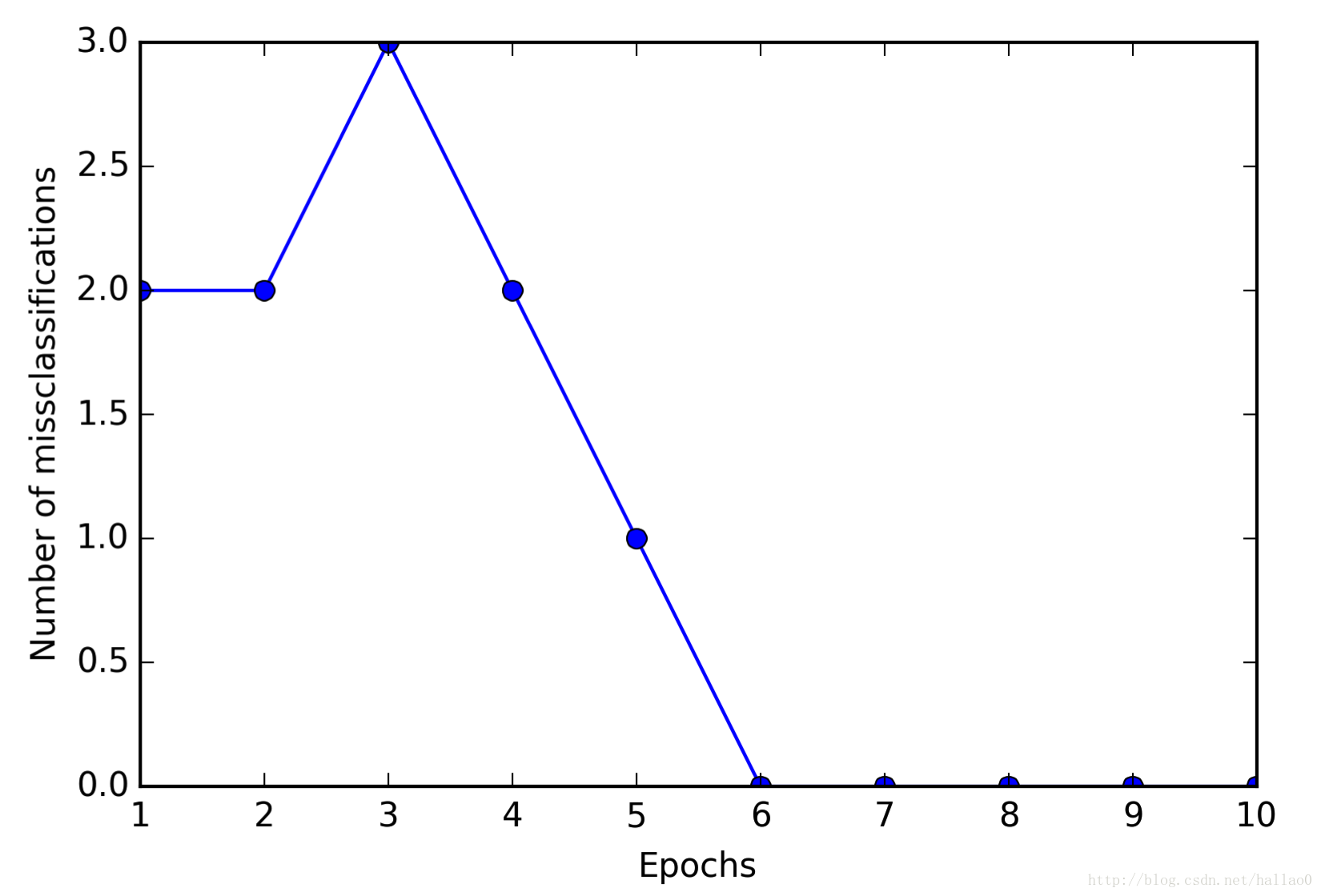















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









