






abstract
We describe latent Dirichlet allocation (LDA), a generative probabilistic model for collections of discrete data such as text corpora.
LDA is a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics.
Each topic is, in turn, modeled as an infinite mixture over an underlying set of topic probabilities.
In the context of text modeling, the topic probabilities provide an explicit representation of a document.
We present efficient approximate inference techniques based on variational methods and an EM algorithm for empirical Bayes parameter estimation.
We report results in document modeling, text classification, and collaborative filtering, comparing to a mixture of unigrams model and the probabilistic LSI model.
1. Introduction
2. Notation and terminology
entities:
- words
- documents
- corpora
| entity | meaning |
|---|---|
| word | the basic unit of discrete data, defined to be an item from a vocabulary indexed by {1,…,V}. |
| documents | a sequence of N words denoted by w =(w1,w2,…,wN), where wn is the nth word in the sequence. |
| corpora | a collection of M documents denoted by D ={w1,w2,…,wM} |
3. Latent Dirichlet allocation
3.1 LDA & exchangeability
3.2 A continuous mixture of unigrams
4.relationship with other latent variable models
4.1 unigram model
4.2 Mixture of unigram
4.3 Probabilistic latent semantic indexing
4.4 A geometric interpretation
5. Inference and Parameter Estimation
5.1 Inference(推理判断)
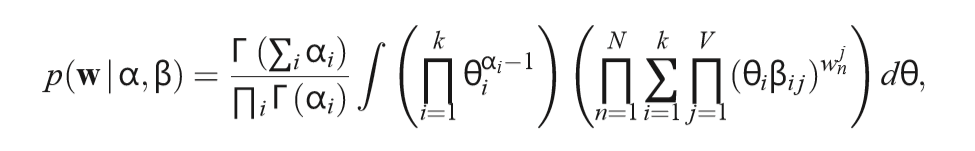
5.2 Variational inference


5.3 Parameter Estimation
5.4 smoothing
6 example

7 Applications and Empirical Results
- document modeling
- document classification
- collaborative filtering
7.1 Document modeling
A lower perplexity score indicates better generalization performance
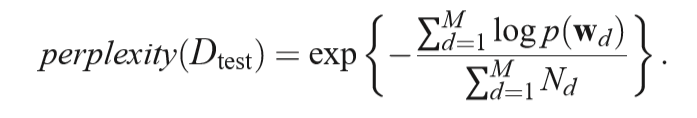
7.2 Document classification

there is little reduction in classification performance in using the LDA-based features; indeed, in almost all cases the performance is improved with the LDA features. Although these results need further substantiation, they suggest that the topic-based representation provided by LDA may be useful as a fast filtering algorithm for feature selection in text classification.
7.2 collaborative filtering
We train a model on a fully observed set of users. Then, for each unobserved user, we are shown all but one of the movies preferred by that user and are asked to predict what the held-out movie is.
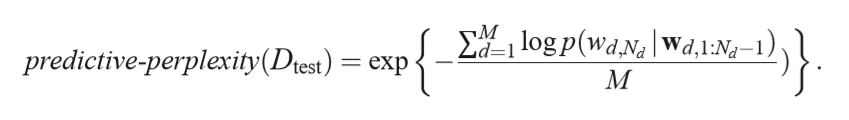
Under the mixture of unigrams model, the probability of a movie given a set of observed movies is obtained from the posterior distribution over topics:
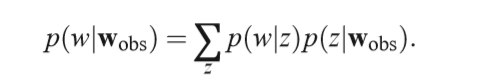
In the pLSI model, the probability of a held-out movie is given by the same equation except that p(z|wobs) is computed by folding in the previously seen movies.
Finally, in the LDA model, the probability of a held-out movie is given by integrating over the posterior Dirichlet:
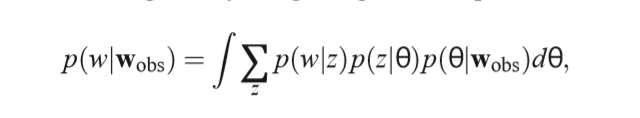
















 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









