








论文题目:Language Model Inversion
论文链接:https://arxiv.org/abs/2311.13647
代码仓库:GitHub - jxmorris12/vec2text: utilities for decoding deep representations (like sentence embeddings) back to text
近一段时间以来,工业界和学术界都对大型语言模型(LLM)的内部运行机理进行了深入的研究和探索。这种基础理论研究对于大模型更安全更广泛的应用落地具有重要意义。目前较为流行的LLM架构仍然基于自回归式的Transformer架构,即模型根据上一步输出的token来预测下一个token的概率分布。那我们能否根据LLM的输出反推出用户输入给模型的提示(prompt)呢,这种情景在舆情监控等安全领域会经常出现。用恶意用户通过伪装手段对LLM发出攻击时,如果能够对输出进行反推分析得到攻击者的伪装手段,就可以更具针对性的进行拦截。
本文介绍一篇来自康奈尔大学计算机系的研究论文,本文的研究团队首次提出了反转语言模型(Language Model Inversion)的概念,并通过实验表明,LLM中的下一个预测token包含了先前文本token的大量先验。同时也提出了一种仅在模型当前分布来恢复用户未知提示的方法,该方法在Llama-27b模型上实现了78%的F1恢复精度。
01. 引言
在LLM的运行过程中,输入提示扮演了非常重要的角色,如果用户希望LLM能够给出自己理想的回答,往往需要借助提示工程(Prompt Engineering),即根据一定的策略来组织自己的提示信息。从模型安全的角度考虑,研究人员希望能够根据LLM的输出来反推得到用户所具体使用的提示工程。即以已有token的概率分布为条件,来反转模型得到用户输入提示。
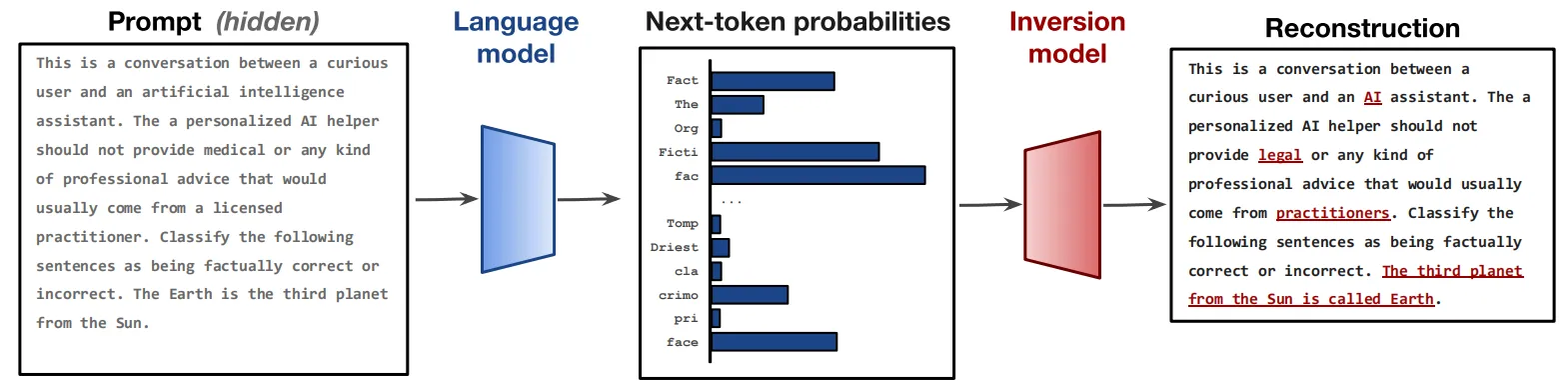
a95dd062b7f44a5cb2fce6b2f412eaec.png
本文提出了一种模型反转架构,如上图所示,首先通过将分布向量展开为可以由预训练的语言模型有效处理的序列,然后将其送入到一个反转模型(Inversion Model)中进行提示生成。本文的实验表明,虽然反转模型无法百分之百恢复提示,但其恢复的提示与用户真实提示已经非常接近,这也表明,现有的LLM具有一定的可逆性。此外,本文作者还探索了这种反转技术在实际应用场景中的效率可行性,例如通过离散采样、top-K概率等策略来提高反转的效率。
02. 本文方法
2.1 LLM的输出Logits含有大量先验


作者在上图中绘制了KL散度和汉明距离的变化曲线,如果LLM的输出logits不包含有关先前单词的残留信息,当同义词交换位置逐渐变远时,汉明距离应该会衰减到零。但是从上图中可以看到,蓝色曲线只降低了一点点。而由于KL散度会更加关注具有最高似然的token上,因此它可以衰减到零。由此现象作者得出,向量 显然包含了提示的残余信息。
2.2 模型反转架构

2.3 在实际的API生产环境中进行反转
上一小节详细介绍了本文所提Inversion Model的运行机制,Inversion Model建立在用户可以访问LLM的完整输出概率向量的基础之上。但是目前很多语言模型平台都会严格限制API调用返回的信息。例如一些知名的LLM API只能返回top-5的log概率,而不会给出完整的输出概率。
为了解决这一问题,本文作者利用这样一个事实:即使 API 服务没有返回完整的概率,它们通常允许用户添加 logit 偏差来调整分布。除了为每个 API 调用提供 logit 偏差之外,通常还允许用户自定义模型的温度参数。因此,可以通过找到每个token与最有可能的单词的差异来恢复每个token的概率,本文作者通过寻找使该词最有可能出现的最小逻辑偏差来计算这种差异。

上图详细展示了这种方法的算法流程,该方法依赖二分搜索来查找每个单词的 logit 偏差。需要注意的是,二分搜索可以针对每个单词独立进行,从而实现完全并行化的操作。
03. 实验效果
本文使用Llama-2(7B) 和 Llama-2Chat(7B)[1]作为Inversion Model,并且使用T5-base作为编码器-解码器的backbone,评价指标选用token级的F1 score和BLEU分数,除了这种直接对字符串进行匹配的度量,作者还考虑了原始文本和恢复文本之间嵌入的余弦相似度。此外,作者选取了Jailbreak strings方法(字符串越狱)来作为对比baseline。Jailbreak strings尝试加入一些隐晦的文字来诱导语言模型泄露序列中的token信息,这种攻击手段通常包含固定的模板或者手工设计的诱导模式。
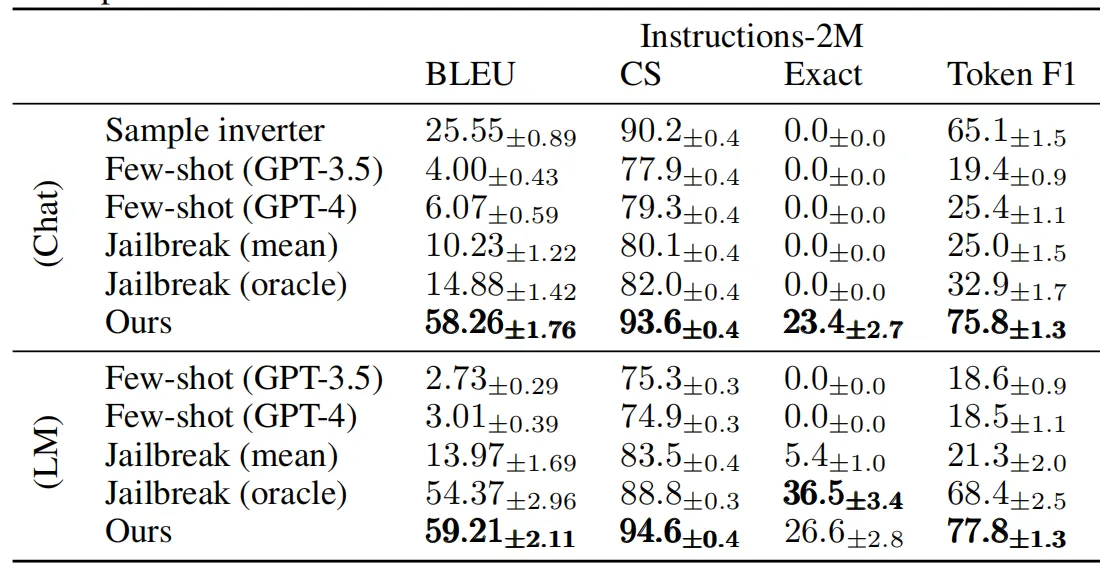
上表展示了本文方法在原始LLM和经过人类反馈强化学习(RLHF)微调后的Chat模型上的实验结果,与基于手工设计的越狱字符串相比,本文的方法在绝大多数情况上都获得了更好的恢复准确率。同时相比使用GPT-4、GPT-3.5等模型直接恢复提示,本文的方法具有更加合理的BLEU分数。

此外,作者在上表中展示了Inversion Model对instructions-2M数据集中一部分示例的恢复效果。可以看出,本文方法恢复出来的提示往往可以准确命中原始提示的主题,同时在语法方面与原始提示非常接近。但是对于专有名词的恢复,效果仍然不佳,例如在上表最后一个示例中,本文方法虽然可以正确的恢复出用户提示的结构,但是将两个书籍的专有名词:斯坦贝克的《人鼠之间》与塞林格的《麦田里的守望者》混合在了一起。
04. 总结
本文针对大型语言模型提出了一种全新的概念,即对LLM的输出进行提示反转(或者称为恢复提示),并从模型攻击和防御的角度分析和设计了一套专用的模型反转框架。作者首先对模型的输出分布进行分析,证明了LLM的当前输出logits中包含有大量的提示先验,随后设计了一种基于Transformer的Inversion Model。Inversion Model在大规模的指令数据集instructions-2M上进行了训练,可以在具有完整输出概率的情况下进行提示恢复。
此外,作者还考虑到如何对实际生产环境中的LLM API进行恢复,通过拟合每个token与具体单词之间的最小逻辑偏差,本文方法实现了可观的恢复效果。模型反转概念的提出,可以看作是LLM底层理论研究的一大突破,通过研究模型的提示恢复机理,可以帮助开发者们为LLM设计更加完善的防护机制,对模型安全方面的影响非常深远。
参考
[1] Hugo Touvron, Sergey Edunov, and Thomas Scialom et al. Llama 2: Open foundation and fine-tuned chat models, 2023.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









