







单变量线性回归
以房屋交易问题为例:
给定的数据集是这样的
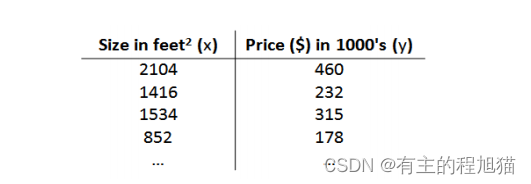
𝑚 代表训练集中实例的数量
𝑥 代表特征/输入变量
𝑦 代表目标变量/输出变量
(𝑥, 𝑦) 代表训练集中的实例
(𝑥(𝑖), 𝑦(𝑖)) 代表第𝑖 个观察实例
h代表学习算法的解决方案或者函数,也称为假设(hypothesis)
那么对于房屋的交易价格作为输出变量y,x代表输入变量
h函数有一种可能表达式:ℎ𝜃(𝑥) = 𝜃_0 + 𝜃_1𝑥,因为输入变量x只有一个,我们称之为单变量线性回归问题。
代价函数:
代价函数有助于我们把最可能的直线与我们的数据相拟合。
在参数选择中,即上述的𝜃_0 , 𝜃_1的选择决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际之间的差距(图中的蓝线)就是建模误差,我们在h函数的选择中,应该尽可能的让误差减小,以实现数据的最大拟合
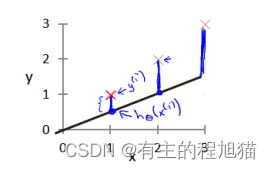
所以我们的目标就是选择能够使代价函数𝐽(𝜃_0, 𝜃_1)最小的参数 𝜃_0, 𝜃_1
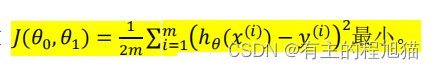
梯度下降算法
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数
𝐽(𝜃
0
, 𝜃
1
)
的最小值。
梯度下降背后的思想是:
开始时我们随机选择一个参数的组合
(𝜃_
0
, 𝜃_
1
, . . . . . . , 𝜃_
𝑛
)
,计算代 价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到达一个局部最小值
(local minimum
)
但是因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum
),选择不同的初始参数组合,可能会找到不同的局部最小值。
算法公式为:
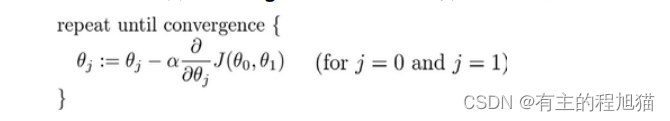
其中
𝑎
是学习率(
learning rate
),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
在梯度下降过程中,我们要更新𝜃_0, 𝜃_1,注意这里应该要同时更新,后续我们会讲到,应该使用一个和参数𝜃维数相同的一个向量temp来临时存储更新过程中的新参数𝜃,当全部参数𝜃更新完之后,再将生成的temp向量赋值在𝜃向量中。
如图:
ps:( 这里用了高数下的偏导数的知识)
梯度下降的直观理解:
梯度下降算法的描述如下:对𝜃赋值,使得𝐽(𝜃)按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值其中𝑎是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
关于偏导数这一块光凭文字略显苍白无力,这里附上老师的课件
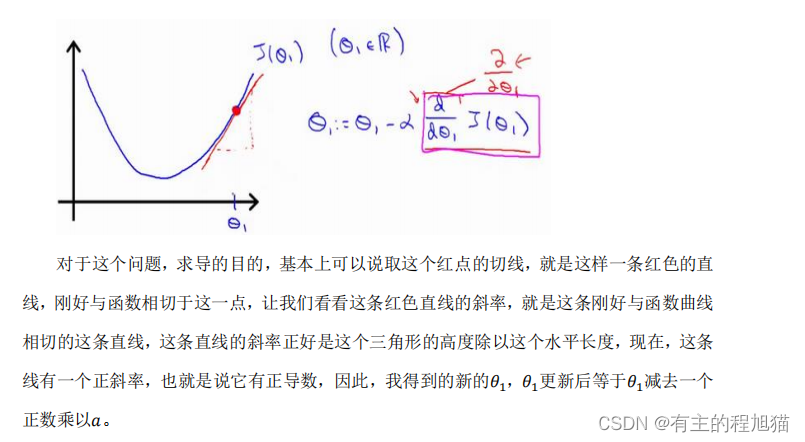 除此之外,对于α的取值也有一定讲究:
除此之外,对于α的取值也有一定讲究:
如果𝑎太小了,即我的学习速率太小,那么我们最终迭代的次数就会十分多,以此不断去接近我们的全局最低点
但如果α太大了,那么梯度下降法在迭代过程中可能会越过最低点,甚至无法收敛。















 2954
2954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









