







 本文通过实例比较了主成分分析(PCA)与增量主成分分析(IPCA)两种方法在处理大型数据集时的表现。IPCA能够有效降低内存消耗,特别适用于数据集过大无法一次性加载到内存的情况。
本文通过实例比较了主成分分析(PCA)与增量主成分分析(IPCA)两种方法在处理大型数据集时的表现。IPCA能够有效降低内存消耗,特别适用于数据集过大无法一次性加载到内存的情况。
当要分解的数据集太大而无法放入内存时,增量主成分分析(IPCA)通常用作主成分分析
(PCA)的替代。IPCA使用与输入数据样本数无关的内存量为输入数据建立低秩近似。它仍
然依赖于输入数据功能,但更改批量大小可以控制内存使用量。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA, IncrementalPCAiris = load_iris()
X = iris.data
y = iris.targetX.shape,y.shape((150, 4), (150,))
增量PCA,批量大小10
n_components = 2
ipca = IncrementalPCA(n_components=n_components, batch_size=10)
X_ipca = ipca.fit_transform(X)PCA
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)colors = ['navy', 'turquoise', 'darkorange']对比PCA(误差)
for X_transformed, title in [(X_ipca, "Incremental PCA"), (X_pca, "PCA")]:
plt.figure(figsize=(8, 8))
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(X_transformed[y == i, 0], X_transformed[y == i, 1],
color=color, lw=2, label=target_name)
if "Incremental" in title:
err = np.abs(np.abs(X_pca) - np.abs(X_ipca)).mean()
plt.title(title + " of iris dataset\nMean absolute unsigned error "
"%.6f" % err)
else:
plt.title(title + " of iris dataset")
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.axis([-4, 4, -1.5, 1.5])
plt.show()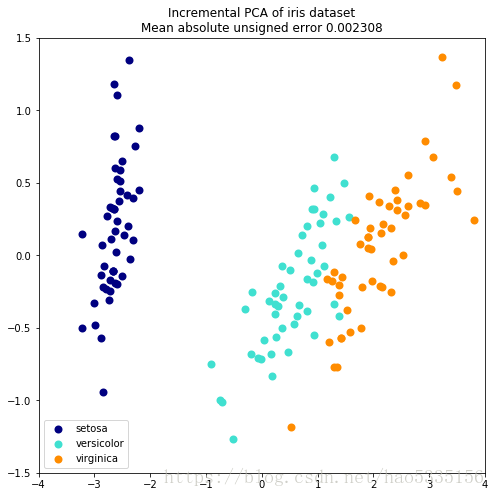
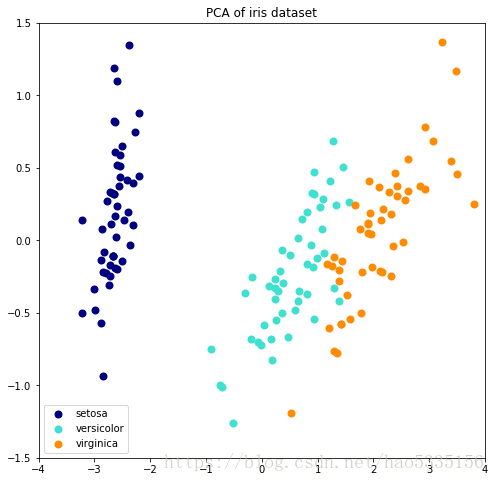

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









