









解读高赞LoRA文章,主要内容是LoRA的变种及其优化。

🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
扩散模型相关知识点参考:小白也能读懂的AIGC扩散(Diffusion)模型系列讲解
目录
【三】LoRA技术微调训练SD系列模型的Text Encoder
LoRA模型融合详解(Merge Block Weighted,MBW)
1. LoCon(Low-Rank Convolution)
2. LoHa(Low-Rank Hadamard Product)
4. 残差 LoRA(Residual LoRA)【缩放因子α】
5. LCM LoRA(Layer-wise Convolution and Multi-head LoRA)
5. Textual Inversion(embeddings模型)技术详解
摘录于:
https://zhuanlan.zhihu.com/p/639229126
LoRA(Low-Rank Adaptation)是与Stable Diffusion(简称SD)系列配合使用最多的模型,SD模型+LoRA模型的组合,大幅降低了AI绘画的成本,提高了AI绘画的多样性和灵活性。
论文地址:https://arxiv.org/pdf/2106.09685
LoRA模型核心基础知识
但是AI大模型参数量巨大,训练成本较高,当遇到一些细分任务时,对AI大模型进行全参微调训练的性价比不高,在这种情况下,本文的主角——LoRA(Low-Rank Adaptation)模型就出场了。
LoRA模型可以与所有AIGC核心领域结合使用,具有很强的“万金油”特性。
LoRA模型的核心原理
LoRA(Low-Rank Adaptation)本质上是对特征矩阵进行低秩分解的一种近似数值分解技术,可以大幅降低特征矩阵的参数量,但是会伴随着一定的有损压缩。从传统深度学习中,LoRA本质上是基于Stable Diffusion的一种轻量化技术。
在AI绘画领域,我们可以使用SD模型+LoRA模型的组合微调训练方式,只训练参数量很小的LoRA模型,就能在一些细分任务中取得不错的效果。
LoRA模型的训练逻辑是首先冻结SD模型的权重,然后在SD模型的U-Net结构中注入LoRA权重,主要作用于CrossAttention部分,并只对这部分的参数进行微调训练。

也就是说,对于SD模型权重![]() ,我们不再对其进行全参微调训练,我们对权重加入残差的形式,通过训练ΔW来完成优化过程:
,我们不再对其进行全参微调训练,我们对权重加入残差的形式,通过训练ΔW来完成优化过程:
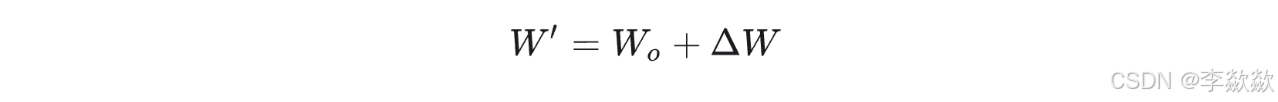
其中![]() ,d 就是 ΔW 这个参数矩阵的秩(Rank,lora_dim), ΔW 通过低秩分解由两个低秩矩阵 A和B 的乘积组成。一般来说,尽管SD模型的参数量很大,但每个细分任务对应的本征维度(Intrinsic Dimension)并不大,所以我们设置较小的d值就能获得一个参数量远小于SD模型的LoRA模型,并在一些细分任务中获得较好的效果。同时如果我们将d设置的越小,LoRA模型的参数量就越小,但是 |W′−AB| 的近似度就越差。
,d 就是 ΔW 这个参数矩阵的秩(Rank,lora_dim), ΔW 通过低秩分解由两个低秩矩阵 A和B 的乘积组成。一般来说,尽管SD模型的参数量很大,但每个细分任务对应的本征维度(Intrinsic Dimension)并不大,所以我们设置较小的d值就能获得一个参数量远小于SD模型的LoRA模型,并在一些细分任务中获得较好的效果。同时如果我们将d设置的越小,LoRA模型的参数量就越小,但是 |W′−AB| 的近似度就越差。
假设原来的ΔW是100*1024的参数矩阵,那么参数量为102400;
拆成了两个矩阵相乘,设置Rank=8,那么就是100*8+8*1024=8992。
整体参数量下降了约11.39倍。What amazing!非常简洁、高效的思想!

【A B 初始化】
上图是LoRA模型训练的示意图。通常来说,对于矩阵A,我们使用随机高斯分布初始化,并对矩阵B使用全0初始化,使得在训练初始状态下这两个矩阵相乘的结果为0。这样能够保证在训练初始阶段时,SD模型的权重完全生效。
虽然矩阵B使用全0初始化能够让SD模型的权重完全生效,但同时也带来了不对称问题(矩阵B全零,矩阵A非全零)。我们可以通过“补权重”法(训练前先在SD模型权重中减去矩阵AB的权重)来使矩阵AB都使用随机高斯分布初始化,在效果不变的情况下,增加了对称性:
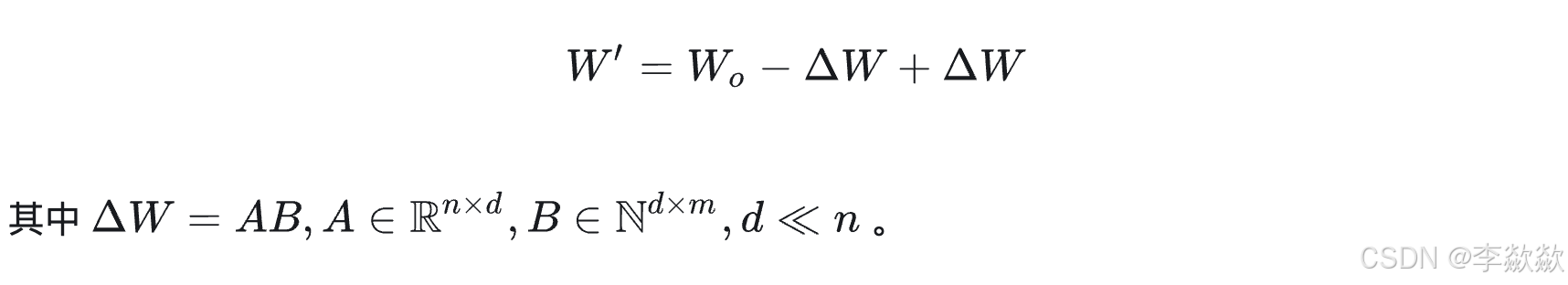
矩阵A,我们使用随机高斯分布初始化,并对矩阵B使用全0初始化,在训练初始阶段时,SD模型的权重完全生效。这会导致训练开始时矩阵 A 和 B 的更新不对称(即 A 和 B 的贡献不均衡)。为了解决这一问题,引入了 补权重法:
通过从
中移除初始化的 AB,保证了模型初始权重依然为
LoRA模型的优势
【1】微调训练阶段
- 参数量非常小:矩阵乘积AB与SD模型的参数有相同的维度,同时分解出来的两个低秩矩阵可以确保参数更新是在低秩情况下的,这样就显著减少训练的参数数量了。同时LoRA模型本身的参数量非常小,最小可至3M左右,这使得LoRA模型在开源社区非常方便传播,也进一步促进了AI绘画领域的爆发式繁荣。
- 显存占用小:训练LoRA模型所需的算力要求很低,我们可以在2080Ti级别的算力设备上进行LoRA模型的训练。因为使用LoRA技术大幅降低了SD系列模型训练时的显存占用,整个训练过程中不需要更新SD模型的权重,所以SD模型对应的优化器参数不需要存储。
- 计算量:训练过程中的整体计算量没有明显变化,因为LoRA模型是在SD模型的全参梯度基础上增加了“残差”梯度,整体上计算量会比SD模型的全参微调略大。
- 训练数据量小:LoRA模型能在小数据集上进行训练(1张以上即可,理论上1张图片也能训练)。
- 训练速度快:在其他超参数一致的情况下,与SD系列模型全参训练相比,LoRA模型训练速度更快。因为训练过程中只更新LoRA模型对应的参数,无需对SD模型权重进行更新;同时由于更新的参数量大幅减少,所以数据传输的通信时间也减少了。
- 站在“巨人”的肩膀上:LoRA模型能以SD模型原有的能力为基础,继续优化学习特定分布特征。
【2】前向推理阶段
- 参数量不变:在推理过程中,由于LoRA模型权重与SD模型权重进行了合并,同时SD模型的结构是不改变的,所以推理时的参数量是不变的。
- 显存占用:在推理过程中,由于LoRA模型权重与SD模型权重进行了合并,同时SD模型的结构是不改变的,所以推理时的显存占用和SD模型的显存占用一致。
- 推理耗时:在推理过程中,由于LoRA模型权重与SD模型权重进行了合并,同时SD模型的结构是不改变的,所以推理耗时没有增加。
- 生成效果:针对特定的人物和风格特征,使用LoRA模型+SD模型的生成效果会比只用SD模型微调训练后的生成效果要好。
- 高效切换:SD模型之间切换需要将所有模型参数加载到内存,从而造成严重的I/O瓶颈。通过对权重更新的有效参数化,不同LoRA模型之间的切换加载既高效又容易。
到这里,可能会有读者疑惑,LoRA模型在训练过程中只对很少的参数更新了权重,为什么能够表现出良好的性能呢?难道不应该更新更多参数的权重来学习更多知识吗?比如说SD模型直接微调训练?
大模型的性能与参数维度的关系 原因是像SD、LLM等大模型往往具有较低的内在维度,这意味着大模型的权重矩阵往往是低秩的。换句话说,并非大模型所有的参数都是必需的!我们可以将这些权重矩阵分解为低秩矩阵,并通过训练这部分权重来实现比较好的性能,换个更通俗地表达:“不是大模型全参微调训练不起,而是LoRA模型更有性价比!”
LoRA模型的三大特性(易用性、泛化性、还原度)
每个LoRA模型都具有三种核心特性:
- 易用性:在我们加载LoRA模型的权重后,我们需要用多少提示词(Prompt)来使其完全生效。易用性越高,所需的提示词就越少,我们训练的LoRA模型才能在社区更受欢迎,使用量才能快速提升。
- 泛化性:LoRA模型准确还原其训练素材中主要特征的同时,能否与其他LoRA模型和SD模型兼容生效。高泛化性意味着LoRA模型在多种不同的应用场景下都能保持良好的效果。
- 还原度:在LoRA模型完全生效后,生成的图片与训练素材之间的相似度。高还原性保证了生成图片忠于训练素材,细节和质量上的表现准确无误。

这三个核心特性共同定义了LoRA模型的性能和应用范围,但由于资源和技术限制,通常很难同时优化三个特性。我们在选择LoRA模型时,需要根据具体需求考虑哪两个特性最为关键。
【一】易用性
人物/角色LoRA模型的易用性体现在能用特殊标签快速响应数据集中的人物特征。可以设置一个特殊标签(Trigger Words)来唯一指定人物的主要特征。
风格/抽象概念LoRA模型的易用性体现在直接的对生成图像的整个风格渲染。要学习的是数据集的整体风格特征,就不需要设置特殊标签。
一般来说,当我们使用人物/角色LoRA模型时,可以设置一个特殊标签(Trigger Words)来唯一指定人物的主要特征,比如说黑魔导女孩LoRA中可以设置“dark magician girl”作为特殊标签,这时候我们在使用时,不管是与哪种SD模型结合,在输入“dark magician girl”提示词后都能生成不同风格的黑魔导女孩图片。
当我们使用风格/抽象概念LoRA模型时,与人物LoRA正好相反,我们不需要一个特别固化的人物特征,而是需要一个全图像级别的风格渲染,所以风格LoRA要学习的是数据集的整体风格特征,就不需要设置特殊标签。
【二】泛化性
AI模型的泛化性是指模型对未见过的新数据做出准确预测的能力,即模型的“举一反三”能力。
使用正则化进行提高:
- 在训练前:设置正则化数据集,使用某些提示词,先在SD底模型上生成一定量的图像,作为正则化集进行先验约束。【类似DreamBooth的类别约束】
- 在训练前:训练数据集进行精细化标签,也能提升LoRA模型的泛化性。将图像的全部特征都集中在一个触发词上是一种过拟合的表现。
- 在训练中:可以使用梯度截断、Dropout、Normalize、L1和L2等正则化技术在训练过程中不断将想要偏离的梯度进行纠偏,防止LoRA模型跑飞。
一个具有良好泛化性能的模型能够从训练数据中学习到足够的、普遍适用的规律,而不是仅仅记住训练集中的特定案例。
那么,我们该如何优化LoRA模型的泛化性能呢?
当前的AI绘画开源社区中,所有的热门SD系列模型都是从Stable Diffusion 1.x-2.x以及Stable Diffusion XL官方模型上微调而成,同时这些微调训练后的模型还会进行模型融合(Checkpoint Merger)或者进一步微调训练获得新的模型。这就导致了目前的很多开源SD系列模型过拟合在了一个风格或者概念上。
所以最好的解决方法是我们直接使用泛化性能最强的官方Stable Diffusion 1.x-2.x以及Stable Diffusion XL模型作为底模型,以此来训练LoRA模型,从而获得泛化性能较强的LoRA模型。
除此之外,我们还可以用正则化技术来降低LoRA模型的过拟合程度,增强LoRA模型的泛化性能。在AI绘画的生成式大模型中,一般有两种正则化方式:
- 在训练前:设置正则化数据集,正则化数据集会预先将一个概念给锚定下来,使得LoRA模型在训练过程中不会偏离预先设定的概念分布,防止模型过拟合训练数据,提高模型的泛化能力。比如我们想要训练一个美女/帅哥LoRA,那么我们可以使用“1girl”或者“1boy”这个提示词,先在SD底模型上生成一定量的图像,作为正则化集进行先验约束。在本文后面提到的DreamBooth LoRA模型中,就用到了正则化数据集。
- 在训练中:可以使用梯度截断、Dropout、Normalize、L1和L2正则化等技术在训练过程中不断将想要偏离的梯度进行纠偏,防止LoRA模型跑飞。
与此同时,我们对LoRA的训练数据集进行精细化的标签,也能提升LoRA模型的泛化性。目前AI绘画的开源社区中有一个典型的误区,就是大家总认为训练集中的标签越多会导致LoRA的效果越差。大家觉得效果差的原因是无法用一个触发词获得想要的效果,但其实将图像的全部特征都集中在一个触发词上是一种过拟合的表现。丰富的标签能够降低LoRA模型训练过程中对底模型对应概念的污染,拆解训练集中的各个概念到不同的标签中,避免了训练集特征过度集中在某个提示词中导致的LoRA模型生成图像出现姿势呆板、表情僵硬、着装单一、和其他LoRA模型一起使用时出现大量的非正常色块甚至是噪点的情况。
【三】还原度
还原度是指LoRA生成的图像特征和数据集特征的相似度,是一个比较灵活的特征。
- 训练的是人物LoRA模型时,通过特定的触发词即可生成高还原度的图像。
- 训练的是风格LoRA模型时,我们通过丰富的触发词即可生成高还原度的图像。
LoRA模型的高阶用法
除了上面我们已经讲到的SD模型+LoRA模型的基础使用形式,LoRA模型还有三种高阶用法:
- 可以调整LoRA模型使用时的权重。
- 使用多个LoRA模型同时作用于一个SD模型。
- 使用LoRA技术微调训练SD系列模型的Text Encoder。
这三种用法在diffusers中很常用,还有一些在固定位置起作用的方法,具体可以参考:https://huggingface.co/docs/diffusers/main/en/tutorials/using_peft_for_inference
【一】调整LoRA模型使用时的权重
首先,我们可以调整LoRA模型的权重:
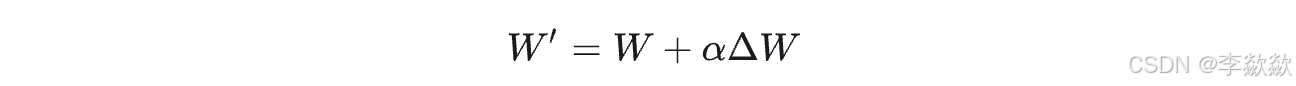
其中 α 代表了LoRA模型的权重。
- 当我们将α设置为0时,与只使用SD模型的效果完全相同;
- 将α设置为1时,与使用 W′ = W + ΔW 的效果相同。
- 如果出现LoRA模型的效果过于强的情况,我们可以将α设置为较低的值(比如0.2-0.3)。
- 如果使用LoRA的效果不太明显,那我们可以将α设置为略高于1的值(比如1.2-1.5)。
【二】多个LoRA模型同时作用
除了调整单个LoRA的权重,我们还可以使用多个LoRA模型同时作用于一个SD模型,并配置他们的各自权重,我们拿两个LoRA模型举例:
【三】LoRA技术微调训练SD系列模型的Text Encoder
我们知道SD系列模型中的Text Encoder部分也包含了大量的Attention结构,所以可以使用LoRA微调SD模型的Text Encoder,获得Text Encoder LoRA模型。
整个训练流程和SD U-Net LoRA模型一致;在前向推理阶段,将Text Encoder LoRA模型权重合并到SD系列模型的Text Encoder中。
下图是用LoRA技术同时微调训练U-Net和Text Encoder时的训练参数对比图:
LoRA技术同时微调训练U-Net和Text Encoder时的训练参数对比图 在使用时,我们可以更加灵活地在SD模型中加载LoRA模型权重:
- SD模型+ U-Net LoRA模型 + Text Encoder LoRA模型
- SD模型+ U-Net LoRA模型
- SD模型+ Text Encoder LoRA模型
三种不同的使用方式,生成图片的效果也会不同,下图是不同LoRA模型的不同权重组合在生成人像的效果:
不同LoRA模型的不同权重组合生成人像的效果
DreamBooth LoRA模型
DreamBooth LoRA和LoRA Finetune训练方式的区别如下:
| 区别项 | DreamBooth LoRA 训练方式 | 直接 LoRA 微调训练方式 |
|---|---|---|
| 训练数据设置 | 使用目标对象数据集和正则化数据集相结合,确保特定对象与同类别的通用特征平衡,防止模型过拟合 | 仅使用目标对象的特定数据集,不引入正则化数据集,模型专注于学习目标对象的特征 |
| 训练目标 | 关注特定对象的适应性与类别特征的平衡。生成特定对象时,同时保留类别特征的多样性,避免过拟合,平衡特定对象的细节和类别的通用特征 | 让模型尽快适应特定任务,专注于生成符合特定需求的图像,模型对目标对象特征进行全面调整 |
| 过拟合控制 | 通过引入正则化数据集,防止过拟合,适合小样本数据场景,让模型在学习特定对象的同时保持对类别的泛化能力 | 缺少正则化数据控制过拟合,模型可能过度拟合特定对象特征,特别在数据不足时,容易导致生成结果缺乏多样性 |
| 适用场景 | 适用于生成特定对象(如特定人物或宠物)且需要类别多样性的场景,适合高保真、需要小样本微调的特定对象生成任务 | 适用于快速适应特定任务的场景,适合数据充足的特定图像生成需求,尤其适合无类别多样性要求的特定任务 |
DreamBooth介绍:SD模型微调之DreamBooth-CSDN博客
目前diffusers库已经支持DreamBooth_LoRA的训练:diffusers/dreambooth
【详细的DreamBooth_LoRA方法可参考diffusers官方的文档diffusers/training/dreambooth】
LoRA模型融合详解(Merge Block Weighted,MBW)
目前LoRA模型的主流融合方式一共有以下几种:
- LoRA+LoRA
- LoRA+LoRA分层融合
- SD模型与SD模型差分获得LoRA模型
- SD模型与LoRA模型融合
- SD模型与LoRA模型分层融合
当我们进行MBW模型融合时,通常可以将SD模型的U-Net进行分层,并对每一层进行特定的权重设置,如下图所示:

同时在AI绘画的开源社区中,大家总结了一些LoRA模型分层融合的经验。
主流LoRA变体模型汇总详解
【GPT总结Start】
| LoRA 变种 | 主要目标 | 实现方法 | 适用场景与优点 |
|---|---|---|---|
| LoCon | 将 LoRA 扩展到卷积层 | 在卷积层引入低秩矩阵,用于卷积核的权重调整 | 提高视觉任务中细节生成的灵活性,适用于图像生成中的细节优化 |
| LoHa | 通过 Hadamard 乘积降低计算复杂度 | 使用 Hadamard 乘积代替标准矩阵乘法,降低矩阵生成的计算量 | 进一步减少内存和计算开销,适合资源受限的设备或大规模模型微调 |
| Q-LoRA | 通过量化技术降低显存需求 | 对低秩矩阵 AAA 和 BBB 进行 4-bit 或 8-bit 量化处理 | 显著减少显存需求,适合在大模型(如 LLaMA)上实现内存高效微调 |
| 残差 LoRA | 使用残差连接方式增强微调效果 | 将 LoRA 增量矩阵通过缩放因子加入原始权重,实现保守的增强调整 | 保持模型的原始能力,同时提供稳定的微调效果,适用于需要保持原始生成能力的场景 |
| LCM LoRA | 在潜在空间中实现一致性调整,以保持生成模型的稳定性 | 基于 Latent Consistency Models,在潜在空间中对特征进行一致性正则化,以减少分布偏移 | 保证生成模型在处理不同输入时的稳定性,避免生成不一致性,适合应用于需要高一致性的生成任务,如图像超分辨率、图像到图像生成等 |
1. LoCon(Low-Rank Convolution)
- 核心目标:LoCon 将低秩适应扩展到卷积层,而不仅限于线性层。
- 原理:LoRA 原本专注于线性层的低秩适应(在 Attention 模块中的 Query、Key 和 Value 变换),而 LoCon 则将这一机制应用于卷积层。这是因为视觉任务中卷积层占据了大量参数和计算资源。通过引入低秩卷积矩阵,可以有效减少卷积层的参数量并适应新的任务。
- 实现方式:
- 在卷积操作中增加低秩矩阵(通常是两个小矩阵),使得卷积核的调整与原始卷积核保持独立。
- 比如,对于卷积核权重矩阵
,我们可以将其分解为
,其中
和
是低秩矩阵。
- 优点:能够控制视觉任务的细节特征,适合图像生成中对纹理、细节的增强需求。
2. LoHa(Low-Rank Hadamard Product)
- 核心目标:进一步降低计算复杂度,在 LoRA 的低秩矩阵中引入 Hadamard(阿达玛尔德) 乘积来生成低秩变化。
- 原理:LoHa 使用 Hadamard 乘积(元素逐项相乘) 替代矩阵乘法,将 LoRA 的低秩矩阵生成过程进一步简化。相比传统的矩阵乘法,Hadamard 乘积的计算复杂度较低,且能在训练时减少内存占用。
- 实现方式:
- 在 LoRA 的公式中,将增量矩阵定义为
,其中
表示 Hadamard 乘积。
- 这样一来,矩阵的生成不需要进行完整的矩阵乘法,而是直接对对应元素相乘,从而减少计算量。
- 在 LoRA 的公式中,将增量矩阵定义为
- 优点:减少内存和计算量,适合资源受限的设备部署。
Hadamard 乘积公式:
矩阵乘法公式:
- 矩阵乘法(Dot Product):标准的矩阵乘法要求前一个矩阵的列数等于后一个矩阵的行数,并且结果的每个元素是行向量和列向量对应元素的加权和,计算量相对较高。
- Hadamard 乘积:Hadamard 乘积则要求两个矩阵大小相同,计算量较低,因为每个元素之间是直接逐项相乘,不需要加权和运算。它的复杂度与矩阵的维数成线性关系。
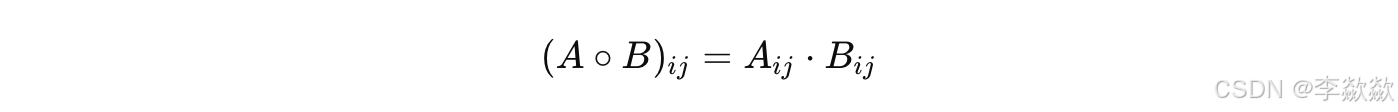
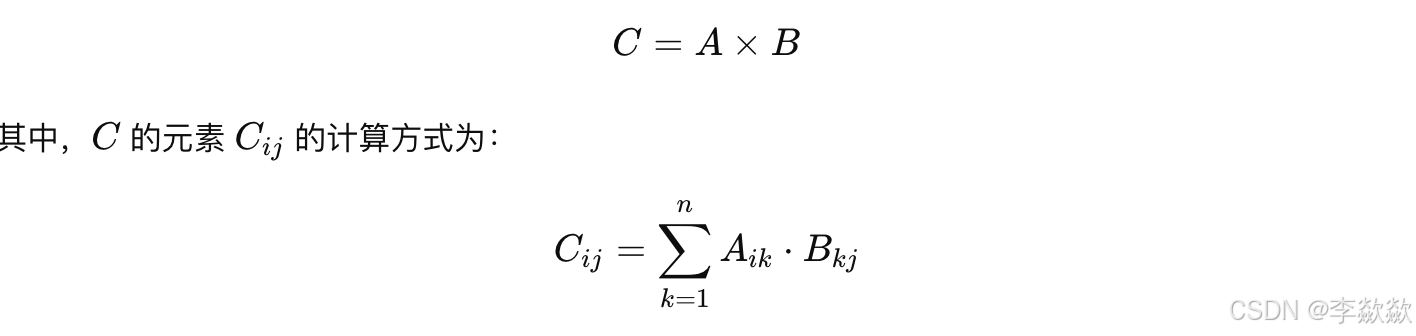
3. Q-LoRA(Quantized LoRA)
- 核心目标:通过量化技术减少 LoRA 的显存和内存需求。
- 原理:在 Q-LoRA 中,对低秩矩阵 A 和 B 进行量化处理(如 4-bit 或 8-bit 量化),这意味着矩阵的元素不再是浮点数,而是量化为较小的整数范围,极大减少了模型在内存和显存上的占用。
- 实现方式:
- 量化操作会将矩阵 A 和 B 进行预处理,将浮点数转化为低精度的整数形式,同时保持低秩矩阵的核心计算方式不变。
- 如使用 4-bit 量化,矩阵元素将转化为 16 个离散值,减少显存的需求。
- 优点:能够显著降低显存消耗,适合大规模模型在有限显存设备上的部署,如对内存需求较大的大语言模型的微调。
- 应用案例:Q-LoRA 已在大模型(如 LLaMA)上实现,能够在不影响模型生成质量的前提下大幅减少资源占用。
量化的基本原理
在深度学习模型中,权重和激活通常以 32 位浮点数(FP32)存储和计算。量化的核心思想是将高精度的浮点数表示转换为低精度整数表示(如 8 位整数 INT8 或 4 位整数 INT4),以此减少内存使用并加快计算速度。
量化公式如下:
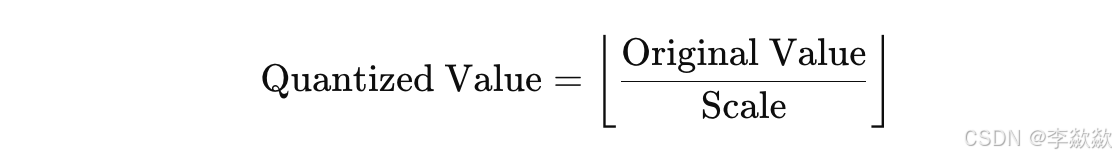
其中,Scale 是一个缩放因子,用于将浮点数映射到整数空间。
更多量化知识参考:万字长文解读深度学习——训练(DeepSpeed、Accelerate)、优化(蒸馏、剪枝、量化)、部署细节_accelerate deepspeed-CSDN博客
4. 残差 LoRA(Residual LoRA)【缩放因子α】
- 核心目标:通过残差连接方式让 LoRA 增强模型的表达能力,并降低 LoRA 产生的潜在误差。
- 原理:在残差 LoRA 中,低秩矩阵 A 和 B 的生成结果被加入到原始权重上,但不是简单的直接相加,而是通过残差连接来处理。这种方式确保了 LoRA 的低秩调整不会改变原始特征太多,但仍然增强了模型的微调效果。
- 实现方式:
- 对于原始权重 ,将 LoRA 增量变换后的矩阵输出 A⋅B 乘上一个缩放因子α(用于调节低秩变化的影响力。通常小于 1 的权重系数)后再加入原始权重,表示为:
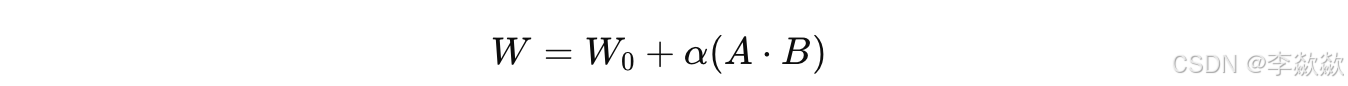
- 对于原始权重 ,将 LoRA 增量变换后的矩阵输出 A⋅B 乘上一个缩放因子α(用于调节低秩变化的影响力。通常小于 1 的权重系数)后再加入原始权重,表示为:
- 优点:保留了模型的原始能力,并在微调任务中提供稳定的提升。残差 LoRA 特别适合在要求原始模型生成能力不受干扰的应用场景中使用。
5. LCM LoRA(Layer-wise Convolution and Multi-head LoRA)
- 核心目标:通过在潜在空间中引入一致性约束,使模型在生成过程中保持更高的稳定性和一致性,从而提升模型对不同输入条件的鲁棒性。
- 原理:在潜在空间中加入一致性正则化项,迫使模型在处理不同的输入条件时,保持生成的潜在特征分布一致。通过这种正则化约束,可以避免模型在生成任务中的分布漂移问题,有助于生成稳定且符合预期的输出。
- 实现方式:
- 潜在一致性正则化:在训练或微调过程中,模型在潜在空间中生成一组特征表示,这些特征被强制在不同输入条件下保持一致。具体而言,通过潜在空间中的一致性损失,约束模型的潜在表示,使其在不同的生成步中趋向于同一分布。
- 低秩矩阵的 LoRA 微调:采用 LoRA 技术对模型的权重进行低秩分解,并在微调过程中只更新低秩矩阵。这种方法既保持了模型的生成能力,又在低参数更新的情况下实现了潜在空间一致性调整。
- 损失函数调整:在损失函数中加入一致性项,通常是基于潜在空间特征的均方误差(MSE)或其他一致性度量,以最小化模型在不同生成条件下的潜在特征差异。

- 优点:
- 生成一致性强:通过一致性正则化,有效减少生成图像或文本在不同输入条件下的分布漂移,使生成内容在结构和风格上更稳定。
- 抗噪性提升:对于噪声较大的输入或具有较大变动的条件输入,LCM LoRA 能够更好地处理,从而提高模型的鲁棒性。
- 高效微调:结合 LoRA 的低秩适应技术,减少了显存和计算资源的需求,保持了原始模型的性能,并在微调中实现了更高效的生成一致性。
- 适用场景:
- 图像超分辨率:LCM LoRA 在超分任务中保持一致性,能够在不同分辨率下生成更精确的细节。
- 图像到图像生成:特别适用于图像到图像转换任务(如风格迁移),确保生成的图像保持一致的风格和细节。
- 文本到图像生成的稳定性提升:在条件变化较大的文本到图像任务中,LCM LoRA 能够帮助模型生成符合描述的稳定结果,适合用于需要连贯一致的生成场景,如连续帧生成或特定风格主题的图像生成。
【GPT总结End】
1. LoCon核心基础知识
LoCon(LoRA for Convolution Network)模型是基于LoRA模型的一个扩展版本,除了对Attention模块进行优化外,还能够对SD系列模型的卷积层进行优化训练,理论上能够实现更细粒度的生成内容控制。
下图中红色框部分代表LoCon模型在LoRA模型基础上额外增加的训练部分:

LoRA模型对卷积层是使用1x1卷积进行降维,而LoCon模型将1x1卷积切换成正常尺寸的卷积进行降维,降维到预设的Rank(lora_dim)。
我们先来回顾一下传统深度学习领域中卷积的计算过程:
卷积计算过程的完整图示 LoCon在实验中得出可以比LoRA模型在训练中更快地拟合(例如,LoCon模型在训练600步可以达到LoRA模型训练800步的生成性能)。这表明LoCon模型可能在训练角色或特定特征上更为高效。另外,将LoCon模型应用于人物角色的风格化上也表现不错。
LoCon推荐训练参数设置:dim <= 64,alpha = 1 (或者更小,比如说0.3)
下面我们看看LoCon模型和LoRA模型在处理卷积层的具体区别:
LoRA模型处理卷积层的代码:
if org_module.__class__.__name__ == 'Conv2d': in_dim = org_module.in_channels out_dim = org_module.out_channels self.lora_down = torch.nn.Conv2d(in_dim, lora_dim, (1, 1), bias=False) self.lora_up = torch.nn.Conv2d(lora_dim, out_dim, (1, 1), bias=False) else: in_dim = org_module.in_features out_dim = org_module.out_features self.lora_down = torch.nn.Linear(in_dim, lora_dim, bias=False) self.lora_up = torch.nn.Linear(lora_dim, out_dim, bias=False)LoCon模型处理卷积层的代码:
if org_module.__class__.__name__ == 'Conv2d': # For general LoCon in_dim = org_module.in_channels k_size = org_module.kernel_size stride = org_module.stride padding = org_module.padding out_dim = org_module.out_channels self.lora_down = nn.Conv2d(in_dim, lora_dim, k_size, stride, padding, bias=False) self.lora_up = nn.Conv2d(lora_dim, out_dim, (1, 1), bias=False) else: in_dim = org_module.in_features out_dim = org_module.out_features self.lora_down = nn.Linear(in_dim, lora_dim, bias=False) self.lora_up = nn.Linear(lora_dim, out_dim, bias=False)
2. LoHa核心基础知识
上面讲到的LoCon主要是对LoRA进行应用层面的改造(将LoRA的应用扩展到SD系列模型的卷积层),接下来我们要讲的LoHa模型主要是针对LoRA的低秩矩阵分解层面进行优化。
LoHa (LoRA with Hadamard Product)是在LoRA的基础上,使用了哈达玛积(Hadamard Product)代替原生LoRA中的矩阵点乘,将秩的维度从2R扩展到 ,让LoHa理论上在相同的参数配置下能学习到更多的分布信息。

左图是原生LoRA模型示意图,右图是LoHa模型示意图
读者朋友可能对哈达玛积不太熟悉,那么我们来了解一下什么是哈达玛积:哈达玛积(Hadamard Product),又称逐元素乘积(element-wise product),是线性代数中的一种矩阵运算。它与标准矩阵乘法不同,哈达玛积是对两个相同大小的矩阵的对应元素进行乘积运算。
秩的维度小于2R从上面的公式中可以看到,哈达玛积通过对两个矩阵的逐元素乘积,能够有效地对矩阵进行特征组合、权重计算和信息传播,增强AI模型的表达能力和计算效率。
可以看到比起原生LoRA的秩的维度小于2R,LoHa将秩的维度扩展到R2,解决了原生LoRA受到低秩的限制。这个思路不仅仅能够用在AI绘画领域,在AIGC其他领域中都可以借鉴与迁移。
LoHa训练经验分享:
- LoHa推荐训练参数设置:dim <= 32,alpha = 1 (or lower)
- LoHa不适合训练特征不太明确的画风,同时也比较难收敛,LoHa通常需要比LoRA和LoCon更多的训练步数才能达到较好的效果。
3. 残差LoRA模型
残差LoRA模型一般用于优化生成图像的质量,比如美颜美白、细节增幅、质感加强等。
一般来说,使用残差LoRA模型时不需要提示词,对生成图像的构图几乎没有影响,可以说是一种“万金油”的LoRA模型系列。
4. LCM LORA模型深入浅出完整解析
【一】LCM LoRA模型基础原理详解
在讲LCM_LoRA之前,先简单介绍一下LCM模型。
LCM模型的全称是Latent Consistency Models(潜在一致性模型),由清华大学交叉信息研究院发布。在这个模型发布之前,Stable Diffusion等潜在扩散模型(LDM)由于迭代采样过程计算量大,生成速度非常缓慢。而LCM 模型通过将原始LDM模型进行蒸馏训练,最后得到一个只用少数的几步推理就能生成高分辨率图像的模型。一般来说,LCM模型能将主流文生图模型的效率提高5-10倍,所以能呈现出实时的效果。
这时候,LCM_LoRA模型登场了。LCM_LoRA模型的核心思想是只对LoRA层参数进行训练,而不用对完整SD模型进行训练。在前向推理时,可将训练好的LCM_LoRA模型用于任何一个微调后的SD模型,无需再对SD模型重新进行蒸馏训练。
通过使用LCM_LoRA模型,可以将SD模型的推理步数减少到仅2至8步,而不是常规的25至50步。在使用LCM_LoRA模型的情况下,SDXL模型在3090显卡上运行只需要大约1秒钟。除了文生图任务外,LCM_LoRA模型还支持图生图任务、图像重绘(inpainting)以及其他SD模型与LoRA模型结合使用的任务场景。
目前大家可以直接体验LCM_LoRA的效果:LCM Painter
【二】LCM LoRA模型加速带来的AIGC新可能性
LCM_LoRA模型的加速能力为Stable Diffusion和Stable Diffusion XL在AIGC领域中的新应用和新工作流打开了大门:
- 普及速度更快:推理速度变快后,AI绘画工具可以被更多人使用,破圈速度更上一层楼。
- 迭代更快:在同样的时间内生成更多的图像或进行更多的尝试对于AIGC从业者来说非常有价值。
- 更易部署:可以在各种不同的硬件上进行生产化部署,包括 CPU。
- 更便宜:图像生成服务会更便宜。
LCM_LoRA模型让AI绘画的整体速度快了一个数量级,我们再也无需等待结果,这带来了颠覆性的体验。如果使用 4090,我们几乎可以得到实时响应 (不到 1 秒)。有了它,SDXL也可以用于需要实时响应的任务场合。
【三】LCM LoRA的训练过程
LCM_LoRA模型是如何训练得到的呢?
我们需要给Stable Diffusion模型外接一个LoRA模型,然后只用LCM的蒸馏损失优化LoRA模型的权重,再经过蒸馏训练后就得到了LCM_LoRA模型。
【四】使用LCM LoRA进行AI绘画
在最新版的diffusers中,我们能够非常方便地使用LCM_LoRA:
from diffusers import DiffusionPipeline, LCMScheduler import torch model_id = "/本地路径/stable-diffusion-xl-base-1.0" lcm_lora_id = "/本地路径/lcm-lora-sdxl" pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16") pipe.load_lora_weights(lcm_lora_id) pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config) pipe.to(device="cuda", dtype=torch.float16) prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux" images = pipe( prompt=prompt, num_inference_steps=4, guidance_scale=1, ).images[0]上述代码所做的事情主要是:
- 加载SDXL 1.0模型。
- 加载LCM_LoRA模型。
- 将调度器改为 LCMScheduler,这是 LCM 模型使用的调度器。
- 使用SDXL+LCM_LoRA快速生成图像。
由于LCM_LoRA模型在训练过程中已经把Guidance Scale集成进去,所以在使用LCM_LoRA模型时一般是不需要再做CFG设置的。但是如果Negative Prompt对结果非常重要,那么也可以设置Guidance Scale为一个很小的值(0-1.5)。
与此同时,LCM_LoRA模型可以和AI绘画开源社区里的各种LoRA模型组合,共同作用,得到既能加速,风格又多变的LCM模型。
下面的代码展示了将LCM_LoRA与常规的SDXL LoRA结合起来使用,使其也能够进行4步推理生成图像:
from diffusers import DiffusionPipeline, LCMScheduler import torch model_id = "/本丢路径/stable-diffusion-xl-base-1.0" lcm_lora_id = "/本地路径/lcm-lora-sdxl" pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16") pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config) pipe.load_lora_weights(lcm_lora_id) pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy") pipe.set_adapters(["lora", "toy"], adapter_weights=[1.0, 0.8]) pipe.to(device="cuda", dtype=torch.float16) prompt = "a toy_face man" negative_prompt = "blurry, low quality, render, 3D, oversaturated" images = pipe( prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=4, guidance_scale=0.5, ).images[0] images下面的表格列出了SDXL+LCM_LoRA和单独SDXL在不同硬件上的生成速度对比(batch size均为1):
可以看到,SDXL+LCM_LoRA的形式在整体生成速度上确实有较大提升,如果使用显存容量比较大的显卡(例如 A100),一次生成多张图像,那么性能会有更显著的提高。
5. Textual Inversion(embeddings模型)技术详解
之前讲到的都是基于Stable Diffusion网络结构的fine-tuning训练技术,接下来Rocky再向大家介绍一下基于prompt-tuning的训练技术——Textual Inversion技术,比起基于fine-tuning训练技术,基于prompt-tuning的训练技术更加轻量化(模型大小几kb-几mb左右),存储成本很低。
【这个微调手段本质上和lora没有关系,是一个全新的微调方式,放到后面的Textual inversion中专门讲解。参考:SD模型微调之Textual Inversion和Embedding fine-tuning】


















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









