






**
1.背景
**
词是NLP的基础,在自然语言任务中,往往使用词向量表示作为机器学习、特别是深度学习的输入和表示空间。在NLP中,传统上词使用离散表示:one-hot表示,主要存在以下问题:
- 无法衡量词向量之间的关系,无法通过各种度量捕获文本的含义
- 词表维度随着语料库增长而膨胀
- 数据稀疏问题
而word2vec的提出,一定程度上解决了one-hot表示存在的一些问题
2.算法实现
word2vec主要有两种训练模式,skip-gram和cbow,其中cbow是根据上下文预测目标单词,而skip-gram是根据目标单词预测上下文。
2.1 cbow

cbow根据上下文预测目标单词,要极大化这个目标单词出现的概率。图中从左到右依次是上下文单词的one-hot向量,乘以初始词向量矩阵W,得到各自对应的词向量,再对这些词向量加和取平均,作为hidden vector,设为h,将h乘以辅助矩阵W’,得到一个维度为V的向量,对其进行softmax归一化,取概率最大的作为预测单词,与答案对比计算损失,然后更新W和W’两个参数矩阵,先根据loss对参数求梯度,再使用梯度下降法更新参数。
2.2 skip-gram
根据目标单词预测上下文,训练模式可参考cbow,反过来。
因为skip-gram根据目标单词预测上下文,进行预测的次数要多于cbow,训练时间也相应的要比cbow长一些。
一般情况下,如果语料库大的话,skip-gram效果要好于cbow。
3.训练过程优化
由于词向量学习最初的设计方案存在很大的效率问题,输出向量维度太大,而且前面还要有一个更大的参数矩阵W‘,难以进行训练优化,因此提出了层次softmax和负采样两种方式来代替原始的从projection layer到output layer的过程。
3.1层次softmax

首先根据词汇表单词出现次数建立一棵Huffman树。
如上图所示,从input layer到projection layer不变,我们要做的是将之前所有都要计算的从输出softmax层的概率变为一颗Huffman树,那么我们的softmax计算只需要沿着Huffman树进行就可以了。其中树的根节点即投影后的词向量,叶子节点对应之前softmax的输出神经元。在根节点处左右子树概率之和为1,在接下来的每个节点,对应两个子节点的概率值之和等于父节点本身的概率值,那么走到最后,所有叶子节点的概率值之和必定还是等于1。
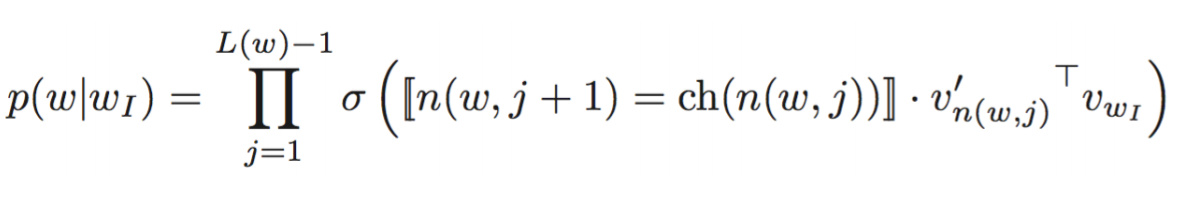
其中σ()为Sigmoid函数,n(w,j)为Huffman树内部w路径第j层的节点,ch(n(w,j))为n节点的孩子节点。
计算量降为树的深度log_2(V)
3.2负例采样
使用负例采样,只有一个正样本,负样本太多,对负样本进行采样,只采样一部分,可以建立一个长度为1的线段,假设为[0,1],划分为10^7等份,根据词出现频率,分配对应线段长度,进行负例采样。














 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









