







写在文章的前面
关于HashMap,你应该知道的十一点知识:
- HashMap的父亲是谁?孩子是谁?兄弟有哪些?
- HashMap与HashTable的区别?
- 数据结构中数组与链表各自的优势、劣势
- HashMap的数据结构
- equals 与 hashCode 的关系
- HashMap如何完成存值、取值?
- 桶的概念
- Hashmap中解决碰撞的办法
- HashMap初建的大小、什么是负载因子
- 当键的hashcode相同,如何获取值对象
- HashMap多线程的条件竞争
一、HashMap
1.1、HashMap与HashTable的区别?
记得之前去一家公司面试,问到了HashMap里是如何存放键值对的,我并不知道,然后面试官很有耐心的和我讲里面的一些细节。感恩。
还有一个经常被问到的问题是:HashMap与HashTable有什么区别?答案很轻易找到。HashMap 是Hashtable 的轻量级实现(非线程安全的实现),他们都完成了Map 接口,主要区别在于:
- hashMap去掉了HashTable 的contains方法,但是加上了containsValue()和 containsKey()方法。
- hashTable同步的,而HashMap是非同步的,效率上逼hashTable要高。
- hashMap允许空键值,而hashTable不允许。
HashMap是最常用的集合类框架之一,它实现了Map接口,所以存储的元素也是键值对映射的结构,并允许使用null值和null键,其内元素是无序的,如果要保证有序,可以使用LinkedHashMap。HashMap是线程不安全的,下篇文章会讨论。
1.2、官方介绍HashMap的定义:
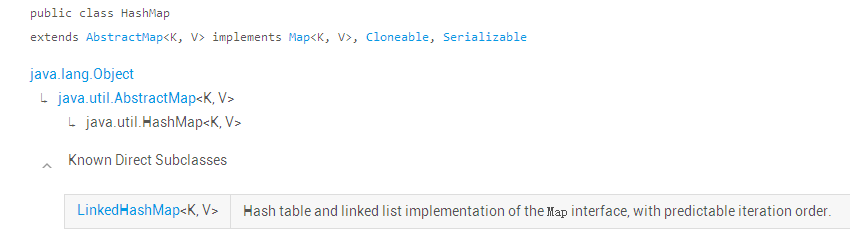
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (**The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.)** This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.HashMap的类结构如下:
与HashMap相关的其他类:
1.3、HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
1.3.1、数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
1.3.2、链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
1.3.3、哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
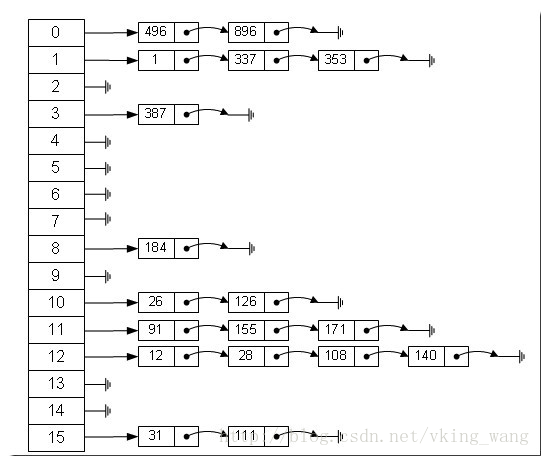
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
rivate static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
//Entry包含了getKey,getValue,hashCode,next方法;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}二、HashMap如何保证key的唯一性?
2.1、hashCode与equals的区别
HashMap中我们最长用的就是put(K, V)和get(K)。我们都知道,HashMap的K值是唯一的,那如何保证唯一性呢?我们首先想到的是用equals比较,没错,这样可以实现,但随着内部元素的增多,put和get的效率将越来越低,这里的时间复杂度是O(n),假如有1000个元素,put时需要比较1000次。实际上,HashMap很少会用到equals方法,因为其内通过一个哈希表管理所有元素,哈希是通过hash单词音译过来的,也可以称为散列表,哈希算法可以快速的存取元素,当我们调用put存值时,HashMap首先会调用K的hashCode方法,获取哈希码,通过哈希码快速找到某个存放位置,这个位置可以被称之为bucketIndex,通过上面所述hashCode的协定可以知道,如果hashCode不同,equals一定为false,如果hashCode相同,equals不一定为true。所以理论上,hashCode可能存在冲突的情况,有个专业名词叫碰撞,当碰撞发生时,计算出的bucketIndex也是相同的,这时会取到bucketIndex位置已存储的元素,最终通过equals来比较,equals方法就是哈希码碰撞时才会执行的方法,所以前面说HashMap很少会用到equals。
HashMap通过hashCode和equals最终判断出K是否已存在,如果已存在,则使用新V值替换旧V值,并返回旧V值,如果不存在,则存放新的键值 对 <K, V>到bucketIndex位置。文字描述有些乱,通过下面的流程图来梳理一下整个put过程。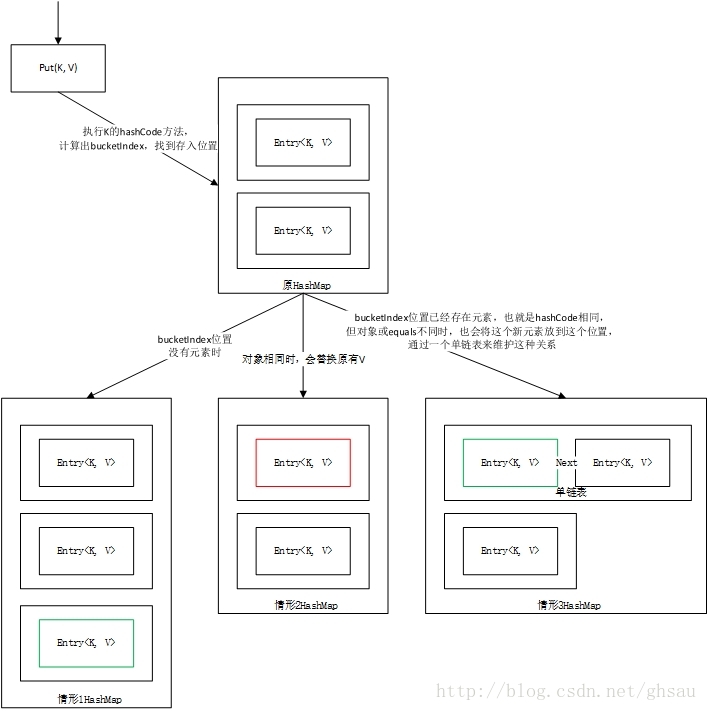
现在我们知道,执行put方法后,最终HashMap的存储结构会有这三种情况,情形3是最少发生的,哈希码发生碰撞属于小概率事件。到目前为止,我们了解了两件事:
- HashMap通过键的hashCode来快速的存取元素。
- 当不同的对象hashCode发生碰撞时,HashMap通过单链表来解决,将新元素加入链表表头,通过next指向原有的元素。单链表在Java中的实现就是对象的引用(复合)。
2.2、HashMap中put方法源码:
public V put(K key, V value) {
// 处理key为null,HashMap允许key和value为null
if (key == null)
return putForNullKey(value);
// 得到key的哈希码
int hash = hash(key);
// 通过哈希码计算出bucketIndex
int i = indexFor(hash, table.length);
// 取出bucketIndex位置上的元素,并循环单链表,判断key是否已存在
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 哈希码相同并且对象相同时
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 新值替换旧值,并返回旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// key不存在时,加入新元素
modCount++;
addEntry(hash, key, value, i);
return null;
} 我们了解了HashMap工作原理的一部分,那还有另一部分,如,加载因子及rehash,HashMap通常的使用规则,多线程并发时HashMap存在的问题等。
参考致谢【都是写得逻辑清晰的好文】:
(1)、http://blog.csdn.net/ghsau/article/details/16843543/
(2)、 java提高篇(二三)—–HashMap
(3)、HashMap实现原理分析
(4)、HashMap的设计原理和实现分析
(5)、HashMap的工作原理

















 7228
7228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









