







文章首发于公众号【编程求职指南】
卷积神经网络( Convolutional Neural Network, CNN):
是一种常见的深度学习架构,受生物自然视觉认知机制(动物视觉皮层细胞负责检测光学信号)启发而来,是一种特殊的多层前馈神经网络。它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
一般神经网络VS卷积神经网络:
相同点:卷积神经网络也使用一种反向传播算法(BP)来进行训练
不同点:网络结构不同。卷积神经网络的网络连接具有局部连接、参数共享的特点。
局部连接:是相对于普通神经网络的全连接而言的,是指这一层的某个节点只与上一层的部分节点相连。
参数共享:是指一层中多个节点的连接共享相同的一组参数。
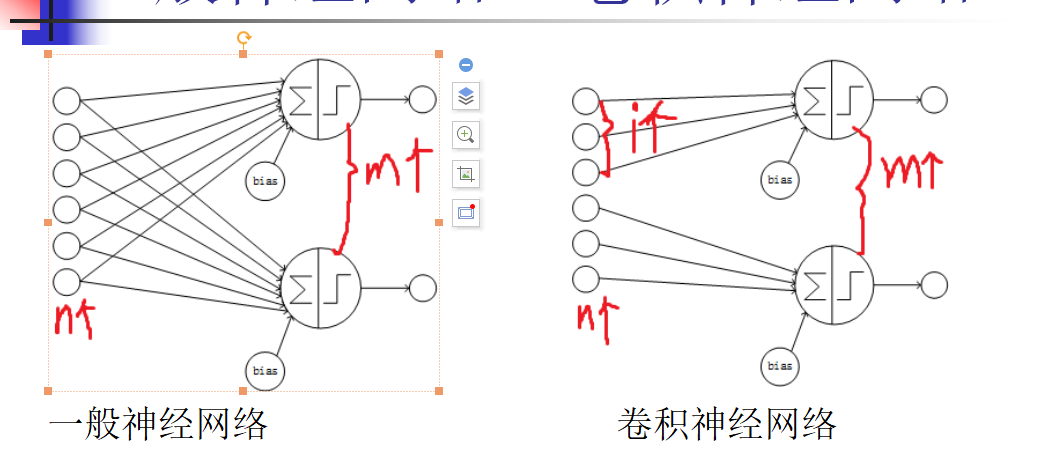
全连接:连接个数nm 局部连接:连接个数im
参数不共享:参数个数n*m+m 参数共享:参数个数i+1
卷积神经网络的主要组成:
卷积层(Convolutional layer),卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
池化层(Pooling),它实际上一种形式的向下采样。有多种不同形式的非线性池化函数,而其中最大池化(Max pooling)和平均采样是最为常见的
全连接层(Full connection), 与普通神经网络一样的连接方式,一般都在最后几层
pooling层的作用:
Pooling层相当于把一张分辨率较高的图片转化为分辨率较低的图片;
pooling层可进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
LeNet-5卷积神经网络模型
LeNet-5:是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示。
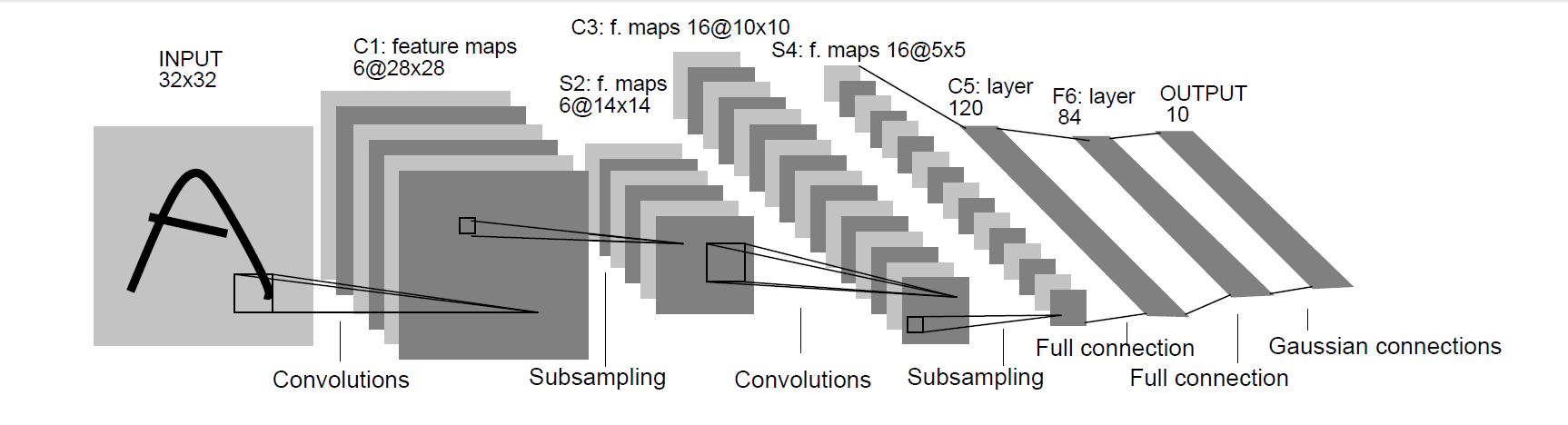
LeNet-5中主要有2个卷积层、2个下抽样层(池化层)、3个全连接层3种连接方式
卷积层
卷积层采用的都是5x5大小的卷积核/过滤器(kernel/filter),且卷积核每次滑动一个像素(stride=1),一个特征图谱使用同一个卷积核.
每个上层节点的值乘以连接上的参数,把这些乘积及一个偏置参数相加得到一个和,把该和输入激活函数,激活函数的输出即是下一层节点的值

LeNet-5的下采样层(pooling层)
下抽样层采用的是2x2的输入域,即上一层的4个节点作为下一层1个节点的输入,且输入域不重叠,即每次滑动2个像素,下抽样节点的结构如下:

每个下抽样节点的4个输入节点求和后取平均(平均池化),均值乘以一个参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。
卷积后输出层矩阵宽度的计算:
Outlength=
(inlength-fileterlength+2*padding)/stridelength+1
Outlength:输出层矩阵的宽度
Inlength:输入层矩阵的宽度
Padding:补0的圈数(非必要)
Stridelength:步长,即过滤器每隔几步计算一次结果
LeNet-5第一层:卷积层C1
C1层是卷积层,形成6个特征图谱。卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。卷积区域每次滑动一个像素,这样卷积层形成的每个特征图谱大小是(32-5)/1+1=28x28。C1层共有26x6=156个训练参数,有(5x5+1)x28x28x6=122304个连接。C1层的连接结构如下所示。

LeNet-5第二层:池化层S2
S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息)。C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14((28-2)/2+1)的图。每个特征图谱使用一个下抽样核。5x14x14x6=5880个连接。S2层的网络连接结构如下右图

LeNet-5第三层:卷积层C3
C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。C3层有16个10x10(14-5+1)的图,每个图与S2层的连接的方式如下表 所示。C3与S2中前3个图相连的卷积结构见下图.这种不对称的组合连接的方式有利于提取多种组合特征。该层有(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个训练参数,共有1516x10x10=151600个连接。

LeNet-5第四层:池化层S4
S4是一个下采样层。C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。5x5x5x16=2000个连接。连接的方式与S2层类似,如下所示。

LeNet-5第五层:全连接层C5
C5层是一个全连接层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下所示。

LeNet-5第六层:全连接层F6
F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,该层的训练参数和连接数都是(120 + 1)x84=10164.

LeNet-5第七层:全连接层Output
Output层也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:

yi的值由i的比特图编码(即参数Wij)确定。yi越接近于0,则标明输入越接近于i的比特图编码,表示当前网络输入的识别结果是字符i。该层有84x10=840个设定的参数和连接。连接的方式如上图.
以上是LeNet-5的卷积神经网络的完整结构,共约有60,840个训练参数,340,908个连接。一个数字识别的效果如图所示

LeNet-5的训练算法
训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段:
第一阶段,向前传播阶段:
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的实际输出Op。
在此阶段,信息从输入层经过逐级的变换,传送到输出 层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二阶段,向后传播阶段
a)算实际输出Op与相应的理想输出Yp的差;
b)按极小化误差的方法反向传播调整权矩阵。
卷积神经网络的优点
卷积网络较一般神经网络在图像处理方面有 如下优点
a)输入图像和网络的拓扑结构能很好的吻
合;
b)特征提取和模式分类同时进行,并同时在
训练中产生;
c)权重共享可以减少网络的训练参数,使神
经网络结构变得更简单,适应性更强。
总结
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式。
通过对LeNet-5的网络结构的分析,可以直观地了解一个卷积神经网络的构建方法,可以为分析、构建更复杂、更多层的卷积神经网络做准备。
LaNet-5的局限性
CNN能够得出原始图像的有效表征,这使得CNN能够直接从原始像素中,经过极少的预处理,识别视觉上面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5 对于复杂问题的处理结果并不理想。
2006年起,人们设计了很多方法,想要克服难以训练深度CNN的困难。其中,最著名的是 Krizhevsky et al.提出了一个经典的CNN 结构,并在图像识别任务上取得了重大突破。其方法的整体框架叫做 AlexNet,与 LeNet-5 类似,但要更加深一些。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









