







一. LeNet 神经网络介绍
LeNet 神经网络由深度学习三巨头之一的 Yan LeCun 提出,他同时也是卷积神经网络 (CNN,Convolutional Neural Networks)之父。LeNet 主要用来进行手写字符的识别与分类,并在美国的银行中投入了使用。LeNet 的实现确立了 CNN 的结构,现在神经网络中的许多内容在 LeNet 的网络结构中都能看到,例如卷积层,Pooling 层,ReLU 层。虽然 LeNet 早在 20 世纪 90 年代就已经提出了,但由于当时缺乏大规模的训练数据,计算机硬件的性能也较低,因此 LeNet 神经网络在处理复杂问题时效果并不理想。虽然 LeNet 网络结构比较简单,但是刚好适合神经网络的入门学习。
二. LeNet 神经网络结构
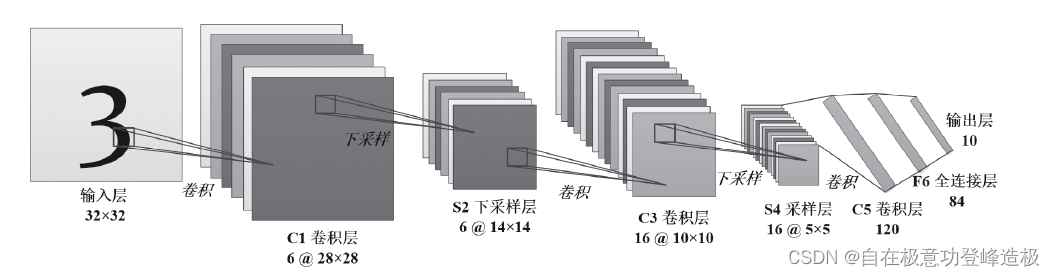
LeNet,特别是其标志性版本 LeNet-5,是由 Yann LeCun 等人在上世纪 90 年代初设计的一种开创性的卷积神经网络(CNN)。
LeNet-5 的架构包括一系列精心设计的层次:
- 首先是接受 32x32 灰度图像的输入层。
- 接着是包含六个 5x5 卷积核的 C1 层,用于提取基本图像特征。
- 随后是采用 2x2 最大池化的 S2 层,减少特征图的尺寸。
- 紧接着是 C3 层,利用 16 个 5x5 卷积核进一步精炼特征,并通过“权值共享”的方式减少参数。
- 之后是再次降低特征图尺寸的S4池化层。
- C5 层继续卷积处理而不改变特征图尺寸。
- 然后,C5 的输出被扁平化送入一个有 120 个神经元的全连接层 F6。
- 最后,通过另一个全连接层得出分类结果,其神经元数目等于分类任务中的类别数,比如在手写数字识别任务中,就是十个神经元,对应 0 至 9 的数字。
- 输出层通常还包含一个 softmax 函数,用于生成各分类的概率分布。
三. LeNet 模型亮点
LeNet 模型,尤其是 LeNet-5,是卷积神经网络(Convolutional Neural Networks, CNNs)早期的一个重要里程碑,由 Yann LeCun 等人在 1998 年设计。LeNet 模型的亮点和贡献如下:
-
卷积神经网络的先驱:
LeNet 是最早的 CNN 模型之一,它定义了现代 CNN 的基本结构,包括卷积层、池化层和全连接层,这些成为了后续所有 CNN 架构的基础。 -
层级特征提取:
LeNet 展示了如何通过层次结构从原始图像中提取特征。卷积层负责捕捉图像中的局部特征,如边缘和纹理,而池化层则用于降低空间维度,减少计算量,同时保持特征信息的关键部分。 -
手写数字识别:
LeNet 最初是为了识别手写数字而设计的,尤其在邮政编码识别系统中得到了广泛应用。它在 MNIST 数据集上表现出色,这为后续的手写字符识别技术奠定了基础。 -
Sigmoid 激活函数的使用:
LeNet 使用 Sigmoid 函数作为激活函数,虽然现在已经被 ReLU 等其他激活函数所取代,但在当时,Sigmoid 函数是神经网络中常见的非线性变换。 -
平均池化与最大池化:
原始的 LeNet 模型使用了 2x2 的平均池化进行下采样,但后来的研究发现最大池化(Max Pooling)在很多情况下能提供更好的性能。最大池化能够更有效地保留图像中最具代表性的特征。 -
可解释性:
相对于后来的深度学习模型,LeNet 的结构相对简单,这使得它的内部工作原理相对容易理解和解释。这对于模型的调试和改进非常重要。 -
参数共享和稀疏交互:
LeNet 利用了卷积层的参数共享特性,这减少了模型的参数数量,使得模型能够在有限的计算资源下训练。同时,卷积层的稀疏交互模式也减少了过拟合的风险。 -
训练效率:
LeNet 展示了如何在当时的硬件条件下高效地训练深度模型。虽然现代 GPU 和深度学习框架已经极大地加速了训练过程,但 LeNet 的设计原则依然适用。 -
启发了后续研究:
LeNet 不仅在当时取得了很好的性能,而且其设计理念和架构启发了后续许多 CNN的发展,包括 AlexNet、VGGNet、ResNet 等更为复杂的模型。
总之,LeNet 在深度学习的历史中占有重要地位,它不仅是一个功能强大的手写数字识别工具,也是现代深度学习技术的基石之一。
四. LeNet 代码实现
开发环境配置说明:本项目使用 Python 3.6.13 和 PyTorch 1.10.2 构建,适用于 CPU 环境。
- model.py:定义 LeNet 网络模型
- train.py:加载数据集并训练,计算 loss 和 accuracy,保存训练好的网络参数
- predict.py:用自己的数据集进行分类测试
- model.py
import torch.nn as nn
import torch.nn.functional as F
# Pytorch Tensor的通道顺序 [batch, channel, height, width]
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__() # super()用于继承基类的方法
self.conv1 = nn.Conv2d(3, 16, 5) # in_channels, out_channels, kernel_size
self.pool1 = nn.MaxPool2d(2, 2) # kernel_size, stride
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # 转化为一维向量 output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = F.relu(self.fc3(x)) # output(10)
return x
- train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optmi
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
"""
1.训练数据集下载
"""
# transform 数据预处理方法
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#---------------------------------------------------------------
# ToTensor() 将“PIL图像”或“numpy.ndarray”转换为张量
# Normalize() 用平均值和标准偏差归一化张量图像
# Normalize() 参数形式 (mean[1],...,mean[n]), (std[1],..,std[n])
#---------------------------------------------------------------
# CIFAR10数据集 50000张训练图片
# 采用 torchvision 中的 datasets 包下载数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
#---------------------------------------------------------------
# root='./data' 表示下载到当前目录的data文件下
# train=True 表示下载训练数据
# download=True 表示执行下载操作
# transform 对图像进行预处理的参数,用于指定对应的数据预处理方法
#---------------------------------------------------------------
"""
2.数据集划分批次
"""
trainloader = DataLoader(trainset, batch_size=36,
shuffle=True, num_workers=0)
#---------------------------------------------------------------
# trainset 训练集
# batch_size=36 划分批次是36,表示每一次随机选取36张图片进行训练
# shuffle=True 表示batch里的数据是否是随机提取出来的
# num_workers=0 载入数据的线程数
#---------------------------------------------------------------
"""
3.测试数据集下载
"""
# CIFAR10数据集 10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = DataLoader(testset, batch_size=10000,
shuffle=True, num_workers=0)
# 将测试集testloader转换为可迭代的迭代器
test_data_iter = iter(testloader)
# 通过next方法可以获取一批数据,包括图像及其对应的标签值
test_image, test_label = next(test_data_iter)
# 导入标签
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
"""
3.扩展:展示图片
"""
# def imshow(img):
# img = img / 2 + 0.5 # 反标准化
# npimg = img.numpy() # 转化为np格式
# # 将Tensor转换为原来载入时的shape
# # 将 [channel, height, width] 转为 [height, width, channel]
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
# # 打印标签
# print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# # 展示图片
# imshow(torchvision.utils.make_grid(test_image))
"""
4.模型训练
"""
net = LeNet() # 实例化模型
loss_function = nn.CrossEntropyLoss() # 定义损失函数
optimizer = optmi.Adam(net.parameters(), lr=0.001) # 定义优化器
#---------------------------------------------------------------
# net.parameters() 表示网络中所有需要训练的参数
# lr 表示学习率参数
#---------------------------------------------------------------
for epoch in range(5): # 定义迭代轮数
running_loss = 0.0 # 用来累加训练中的损失
# 通过循环来遍历训练集
for step, data in enumerate(trainloader, start=0):
# 获取数据的图像和标签
inputs, labels = data
# 将历史损失梯度清零
optimizer.zero_grad()
# 参数更新
outputs = net(inputs) # 获得网络输出
loss = loss_function(outputs, labels) # 计算loss
loss.backward() # 误差反向传播
optimizer.step() # 更新参数
# 打印统计信息
running_loss += loss.item()
# 每隔500步打印信息
if step % 500 == 499:
# 测试过程中不计算损失梯度
with torch.no_grad():
# 将图像输入网络,得到输出
outputs = net(test_image)
# 寻找输出中最大值对应的index(索引)
predict_y = torch.max(outputs, dim=1)[1]
# 计算准确率
accuracy = (predict_y == test_label).sum().item() / test_label.size(0)
print('[%d, %5d] train_loss:%.3f test_accuracy:%.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
# 训练损失累加值清零
running_loss = 0.0
print("Finished Training")
"""
5.模型保存
"""
# 设置存储路径
save_path = './Lenet.pth'
# 保存模型
torch.save(net.state_dict(), save_path)
#---------------------------------------------------------------
# net.state_dict() 表示网络中所有的模型权重
# save_path 保存路径
#---------------------------------------------------------------
- predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
# transform 数据预处理
transform = transforms.Compose(
[transforms.Resize((32, 32)), # 缩放图像以适应网络
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入标签
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
# 实例化模型
net = LeNet()
# 载入权重文件
net.load_state_dict(torch.load('Lenet.pth'))
# 载入测试图像
im = Image.open('plane.jpg')
# 若要将图像放入网络,需要将其转换为Tensor格式 [N, C, H, W]
im = transform(im) # [C, H, W]
# 增加一个batch维度
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
# 不进行损失梯度的计算
with torch.no_grad():
# 将图像输入网络,得到输出
outputs = net(im)
# 寻找输出中最大值对应的index(索引)
predict = torch.max(outputs, dim=1)[1].data.numpy()
# 将index(索引)传入到classes
print(classes[int(predict)])
'''
扩展: 通过softmax函数对输出进行处理
'''
# 不进行损失梯度的计算
# with torch.no_grad():
# # 将图像输入网络,得到输出
# outputs = net(im)
# # 通过softmax函数获得预测的概率
# predict = torch.softmax(outputs, dim=1)
# print(predict)
# 输出如下
# tensor([[9.9681e-01, 2.7001e-04, 2.7001e-04, 2.7001e-04, 2.7001e-04, 2.7001e-04,
# 2.7001e-04, 2.7001e-04, 1.0270e-03, 2.7001e-04]])















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









