







 本文探讨了预处理在机器学习管道中的重要性,特别是在逻辑回归中的应用。通过红酒质量数据集,作者展示了数据的中心化和缩放如何影响模型性能。虽然在k-NN中预处理显著提升模型精度,但在逻辑回归中,预处理并未带来明显提升,因为逻辑回归算法本身可以调整权重以应对不同尺度的特征。
本文探讨了预处理在机器学习管道中的重要性,特别是在逻辑回归中的应用。通过红酒质量数据集,作者展示了数据的中心化和缩放如何影响模型性能。虽然在k-NN中预处理显著提升模型精度,但在逻辑回归中,预处理并未带来明显提升,因为逻辑回归算法本身可以调整权重以应对不同尺度的特征。
原文链接:The importance of preprocessing in data science and the machine learning pipeline II: centering, scaling and logistic regression
作者:Hugo Bowne-Anderson
译者:刘翔宇 审校:赵屹华
责编:周建丁(zhoujd@csdn.net)
未经许可,谢绝转载!
在本系列的第一篇文章中,我探索了机器学习(ML)分类任务中预处理的角色,深入了解了K近邻算法(k-NN)和红酒质量数据集。你见识到了通过对数值数据进行中心化和缩放,提升了k-NN多项模型性能指标(例如精度)。你同样学习到预处理不会凭空产生,而且它的价值只能在具体的预测机器学习管道的情形下来评判。然而,我们只见识到了预处理在一个模型(k-NN)中的重要性。在上面这种情况下,我们的模型表现有显著提高,但总是这样吗?未必!在这篇文章中,我将讨论缩放和中心化数值数据在另一种基本模型中的作用,也就是逻辑回归。你可能需要回顾上一篇文章以及/或者本文底部的词汇列表。我们将再次使用红酒质量数据集。本文所有的样例代码都由Python编写。如果你不熟悉Python,你可以参考我们的DataCamp课程。我将使用pandas库来处理数据以及scikit-learn来进行机器学习。
首先我将简要介绍回归,它可以用来预测数值变量和类别的值。我将介绍线性回归,逻辑回归,然后用后者来预测红酒质量。然后你会看到中心化和缩放是否会对回归模型有所帮助。
Python回归简介
线性回归Python实现
如上所述,回归通常用一个数值型变量预测另一个数值型变量。例如,在下面的代码中我们在波士顿住房数据(scikit-learn内置数据集)上使用了线性回归:在这里,自变量(x轴)是房间的数目,因变量(y轴)是房屋价格。
这种回归是如何工作的?简单来说,它的原理如下:我们希望将模型y=ax+b拟合数据 (xi ,yi ),也就是说,使用现有的数据,我们希望找到一个a和b的最优解。在普通的最小二乘(OLS,迄今为止最常见)公式中,假设了误差会在因变量中产生。出于这个原因,a和b的最优解由最小化误差得到:
这种优化通常使用梯度下降算法来实现。下面我们在波士顿住房数据上使用简单的线性回归:
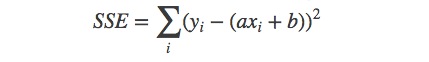
# Import necessary packages
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from sklearn import datasets
from sklearn import linear_model
import numpy as np
# Load data
boston = datasets.load_boston()
yb = boston.target.reshape(-1, 1)
Xb = boston['data'][:,5].reshape(-1, 1)
# Plot data
plt.scatter(Xb,yb)
plt.ylabel('value of house /1000 ($)')
plt.xlabel( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









