







原文:Predicting Loan Credit Risk using Apache Spark Machine Learning Random Forests
作者:Carol McDonald,MapR解决方案架构师
翻译:KK4SBB
责编:周建丁(zhoujd@csdn.net)
在本文中,我将向大家介绍如何使用Apache Spark的spark.ml库中的随机森林算法来对银行信用贷款的风险做分类预测。Spark的spark.ml库基于DataFrame,它提供了大量的接口,帮助用户创建和调优机器学习工作流。结合dataframe使用spark.ml,能够实现模型的智能优化,从而提升模型效果。
分类算法
分类算法是一类监督式机器学习算法,它根据已知标签的样本(如已经明确交易是否存在欺诈)来预测其它样本所属的类别(如是否属于欺诈性的交易)。分类问题需要一个已经标记过的数据集和预先设计好的特征,然后基于这些信息来学习给新样本打标签。所谓的特征即是一些“是与否”的问题。标签就是这些问题的答案。在下面这个例子里,如果某个动物的行走姿态、游泳姿势和叫声都像鸭子,那么就给它打上“鸭子”的标签。

我们来看一个银行信贷的信用风险例子:
- 我们需要预测什么?
- 某个人是否会按时还款
- 这就是标签:此人的信用度
- 你用来预测的“是与否”问题或者属性是什么?
- 申请人的基本信息和社会身份信息:职业,年龄,存款储蓄,婚姻状态等等……
- 这些就是特征,用来构建一个分类模型,你从中提取出对分类有帮助的特征信息。
决策树模型
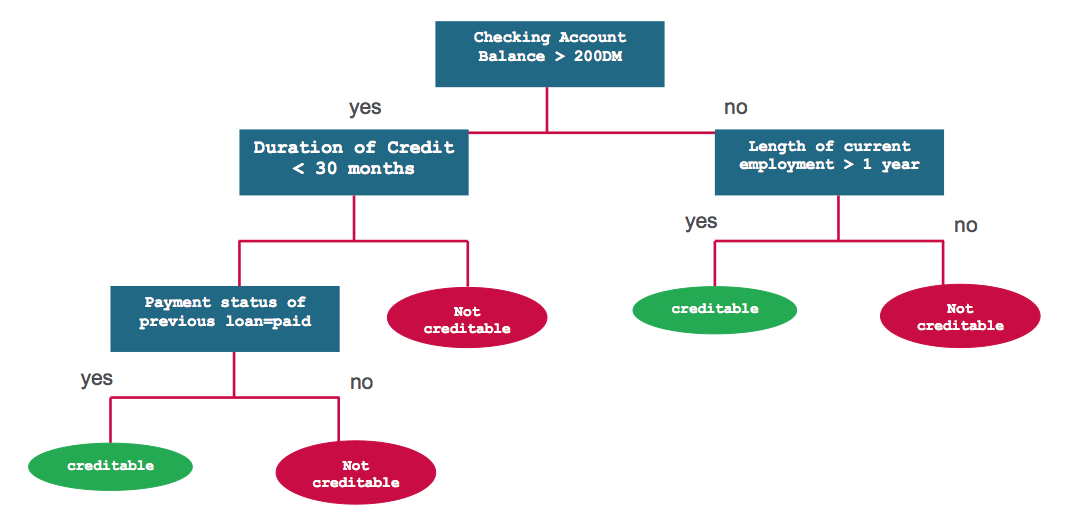
决策树是一种基于输入特征来预测类别或是标签的分类模型。决策树的工作原理是这样的,它在每个节点都需要计算特征在该节点的表达式值,然后基于运算结果选择一个分支通往下一个节点。下图展示了一种用来预测信用风险的决策树模型。每个决策问题就是模型的一个节点,“是”或者“否”的答案是通往子节点的分支。
- 问题1:账户余额是否大于200元?
- 否
- 问题2:当前就职时间是否超过1年?
- 否
- 不可信赖
随机森林模型
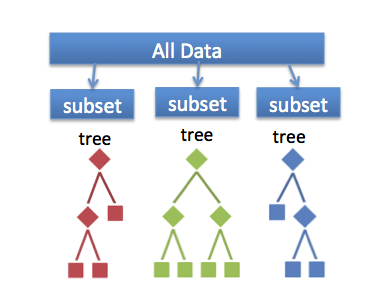
融合学习算法结合了多个机器学习的算法,从而得到了效果更好的模型。随机森林是分类和回归问题中一类常用的融合学习方法。此算法基于训练数据的不同子集构建多棵决策树,组合成一个新的模型。预测结果是所有决策树输出的组合,这样能够减少波动,并且提高预测的准确度。对于随机森林分类模型,每棵树的预测结果都视为一张投票。获得投票数最多的类别就是预测的类别。
基于Spark机器学习工具来分析信用风险问题
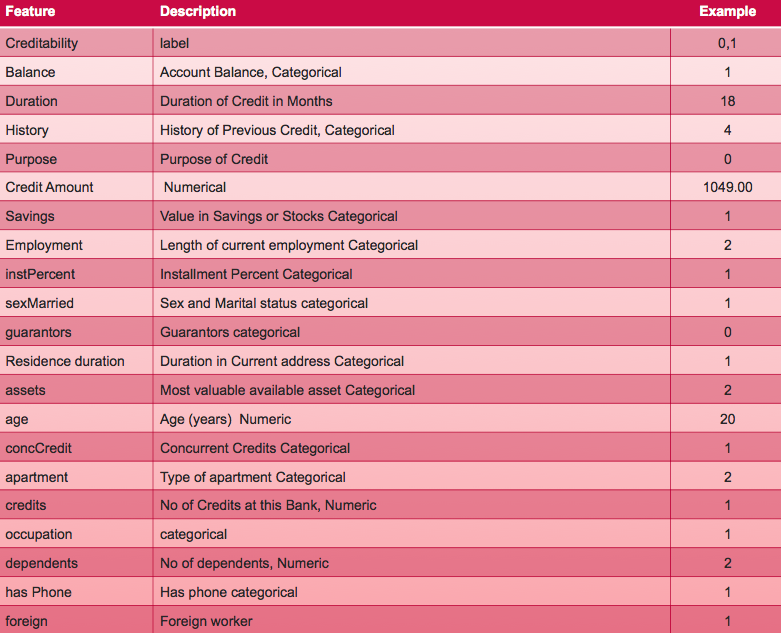
我们使用德国人信用度数据集,它按照一系列特征属性将人分为信用风险好和坏两类。我们可以获得每个银行贷款申请者的以下信息:
存放德国人信用数据的csv文件格式如下:
1,1,18,4,2,1049,1,2,4,2,1,4,2,21,3,1,1,3,1,1,1
1,1,9,4,0,2799,1,3,2,3,1,2,1,36,3,1,2,3,2,1,1
1,2,12,2,9,841,2,4,2,2,1,4,1,23,3,1,1,2,1,1,1
在这个背景下,我们会构建一个由决策树组成的随机森林模型来预测是否守信用的标签/类别,基于以下特征:
- 标签 -> 守信用或者不守信用(1或者0)
- 特征 -> {存款余额,信用历史,贷款目的等等}
软件
本教程将使用Spark 1.6.1
- 你可以从链接中下载代码和数据来运行示例:
https://github.com/caroljmcdonald/spark-ml-randomforest-creditrisk - 输入spark-shell命令后,本文的例子可以在spark-shell环境中交互式的运行。
- 你也可以把代码当做独立的应用来运行,操作步骤参考Getting Started with Spark on MapR Sandbox
按照教程指示,登录MapR沙箱,用户名为user01,密码为mapr。将样本数据文件复制到你的沙箱主目录下/user/user01 using scp。(注意,你可能需要先更新Spark的版本)打开spark shell:
$spark-shell --master local[1]
加载并解析csv数据文件
首先,我们需要引入机器学习相关的包。
import org.apache.spark.ml.classification.RandomForestClassifier
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.VectorAssembler
import sqlContext.implicits._
import sqlContext._
import org.apache.spark.ml.tuning.{ ParamGridBuilder, CrossValidator }
import org.apache.spark.ml.{ Pipeline, PipelineStage }
我们用一个Scala的case类来定义Credit的属性,对应于csv文件中的一行。
// define the Credit Schema
case class Credit(
creditability: Double,
balance: Double, duration: Double, history: Double, purpose: Double, amount: Double,
savings: Double, employment: Double, instPercent: Double, sexMarried: Double, guarantors: Double,
residenceDuration: Double, assets: Double, age: Double, concCredit: Double, apartment: Double,
credits: Double, occupation: Double, dependents: Double, hasPhone: Double, foreign: Double
)下面的函数解析一行数据文件,将值存入Credit类中。类别的索引值减去了1,因此起始索引值为0.
// function to create a Credit class from an Array of Double
def parseCredit(line: Array[Double]): Credit = {
Credit(
line(0),
line(1) - 1, line(2), line(3), line(4) , line(5),
line(6) - 1, line(7) - 1, line(8), line(9) - 1, line(10) - 1,
line(11) - 1, line(12) - 1, line(13), line(14) - 1, line(15) - 1,
line(16) - 1, line(17) - 1, line(18) - 1, line(19) - 1, line(20) - 1
)
}
// function to transform an RDD of Strings into an RDD of Double
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
rdd.map(_.split(",")).map(_.map(_.toDouble))
}接下去,我们导入germancredit.csv文件中的数据,存为一个String类型的RDD。然后我们对RDD做map操作,将RDD中的每个字符串经过ParseRDDR函数的映射,转换为一个Double类型的数组。紧接着是另一个map操作,使用ParseCredit函数,将每个Double类型的RDD转换为Credit对象。toDF()函数将Array[[Credit]]类型的RDD转为一个Credit类的Dataframe。
// load the data into a RDD
val creditDF= parseRDD(sc.textFile("germancredit.csv")).map(parseCredit).toDF().cache()
creditDF.registerTempTable("credit")
DataFrame的printSchema()函数将各个字段含义以树状的形式打印到控制台输出。
// Return the schema of this DataFrame
creditDF.printSchema
root
|-- creditability: double (nullable = false)
|-- balance: double (nullable = false)
|-- duration: double (nullable = false)
|-- history: double (nullable = false)
|-- purpose: double (nullable = false)
|-- amount: double (nullable = false)
|-- savings: double (nullable = false)
|-- employment: double (nullable = false)
|-- instPercent: double (nullable = false)
|-- sexMarried: double (nullable = false)
|-- guarantors: double (nullable = false)
|-- residenceDuration: double (nullable = false)
|-- assets: double (nullable = false)
|-- age: double (nullable = false)
|-- concCredit: double (nullable = false)
|-- apartment: double (nullable = false)
|-- credits: double (nullable = false)
|-- occupation: double (nullable = false)
|-- dependents: double (nullable = false)
|-- hasPhone: double (nullable = false)
|-- foreign: double (nullable = false)
// Display the top 20 rows of DataFrame
creditDF.show
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+
|creditability|balance|duration|history|purpose|amount|savings|employment|instPercent|sexMarried|guarantors|residenceDuration|assets| age|concCredit|apartment|credits|occupation|dependents|hasPhone|foreign|
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+
| 1.0| 0.0| 18.0| 4.0| 2.0|1049.0| 0. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4775
4775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









