







前言
ResNet(Residual Neural Network)由微软研究院的Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun四名华人提出,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,对应的论文《Deep Residual Learning for Image Recognition》更是 2016 CVPR 最佳论文,一直到今天,这几位都是华人界在计算机实现、自动驾驶等领域大名鼎鼎的人物,Resnet也已经代替VGG成为一般计算机视觉领域问题中的基础特征提取网络。Res 也是 Residual 的缩写,它的用意在于基于残差学习,让神经网络能够越来越深,准确率越来越高。
论文地址:https://arxiv.org/pdf/1512.03385.pdf
Alexnet的出现带火了深度学习,其最重要的特点是通过数据驱动让模型自动学习特征,省去了人工寻找特征的步骤。此后,卷积神经网络便一发不可收拾,在后续的各类竞赛中卷积神经网络都大发异彩,除了更高的准确率之外,它们普遍的特征就是,网络的层级越来越深了,AlexNet 8层,VGG 19层,GoogLeNet 22层。虽然VGG验证了16层、19层的效果是最好的,但是GoogLeNet的出现又让人们产生了一个疑问:神经网络是不是越深越好呢?在早期,更深的CNN网络经常遇到的一个问题就是梯度消失,随着网络的加深,反向传播越来越困难,导致收敛也越来越难。然而,这个问题在很大程度上可以通过标准初始化、ReLu激活函数、辅助loss和中间归一化层(BN)来解决,这使得数十层的网络在反向传播过程中仍然能够收敛。
虽然更深的网络可以收敛,但是另外一个问题暴露出来了:随着网络深度的增加,精确度变得饱和,然后迅速退化。出乎意料的是,实验证明这种退化并不是由于过度拟合造成的,而且在适当深度的模型中增加更多的层会导致更高的训练误差。如图1,56层网络在训练和测试上的错误率都比20层的网络高。

Residual learning
上文介绍的退化问题就引出了一个问题,当网络更深时,准确率或许不再提高,但是不能比浅层网络更差?假设深层网络都是线性的,不学习任何东西,输出也应该和浅层网络的输出相同。退化问题说明,后面的网络修改了前面网络的输出,使得loss更大。既然新加的网络修改了前面网络的输出,考虑是否可以让输入直接映射到输出,而只让新的层学习输入与输出之间的差值呢?让我们考虑一种更浅的体系结构及其更深层次的架构,它增加了更多的层。 对于更深的模型,通过构建:恒等映射(identity mapping)来构建增加的层,其它层直接从浅层模型中复制而来。
ResNet论文通过引入深度残差学习框架( a deep residual learning framework )来解决退化问题,论文不再让每个层直接拟合所需的底层映射(desired underlying mapping),而是显式地让这些层拟合一个残差映射(residual mapping)。 对于之前的堆叠神经网络,假设前一层的输出是x,经过卷积计算后的下一层输出是y = H(x),即可以认为H是卷积计算。现在我们不再让该层网络直接去拟合输出y,我们让堆叠的非线性层(新的层)来拟合另一个映射,输出H(x)和输入x之间的差值:F(x) = H(x)−x。因此原来的映射转化为:y = H(x)=F(x)+x=H(x)-x+x,后面的x表示直接的identity mapping,而F(x) = H(x) - x则为新的有参网络层要学习的输入输出间残差。退化问题表明求解者很难用多个非线性层逼近恒等映射。利用残差学习重构,在极端情况下,如果恒等映射是最优的,则将残差映射为零,比用一堆非线性层直接拟合恒等映射更容易。

在反向传播过程中,residual模块会起到什么样的作用呢?
- 新的层从原来学习拟合新的值y转变为学习x和y之间的差值,更加容易学习。
- 因为前向过程中有恒等映射的支路存在,因此在反向传播过程中梯度的传导也多了更简便的路径,仅仅经过一个relu就可以把梯度传达给上一个模块。
- redidual模块中的学习参数对反向传导的损失值有更敏感的响应能力
根据GoogLeNet Inception V2中列出的四条准则的第三条:空间聚合可以在较低维度嵌入上完成,而不会在表示能力上造成过多损失,这里采用同样的方法,加入1*1的卷积核用来增加非线性和减小参数个数。如图3,左边就是基本的residual模块,右边是使用 1 x 1卷积的bottleneck residual模块。同时,使用1 x 1的卷积层还可以使得前后层的卷积核数目互不影响。

当x与y通道数目不同时,作者尝试了两种identity mapping的方式(注意:residual学习的是残差,所以输出y = F(x)+x,两个支路求和,并不是Inception中的concat操作)。一种简单的做法是将x相对y缺失的通道直接补零从而使其能够对齐,另一种则是通过使用1x1的卷积来改变通道数从而使得最终输入与输出的通道达到一致。
实验
论文首先评估了18层和34层的简单网络,如图4,共使用了三种网络进行实验。其一为VGG19网络,另外则是顺着VGG网络思维继续加深其层次而形成的一种VGG朴素网络,它共有34个含参层。最后则是与上述34层朴素网络相对应的Resnet网络,它主要由上节中所介绍的残差单元来构成。
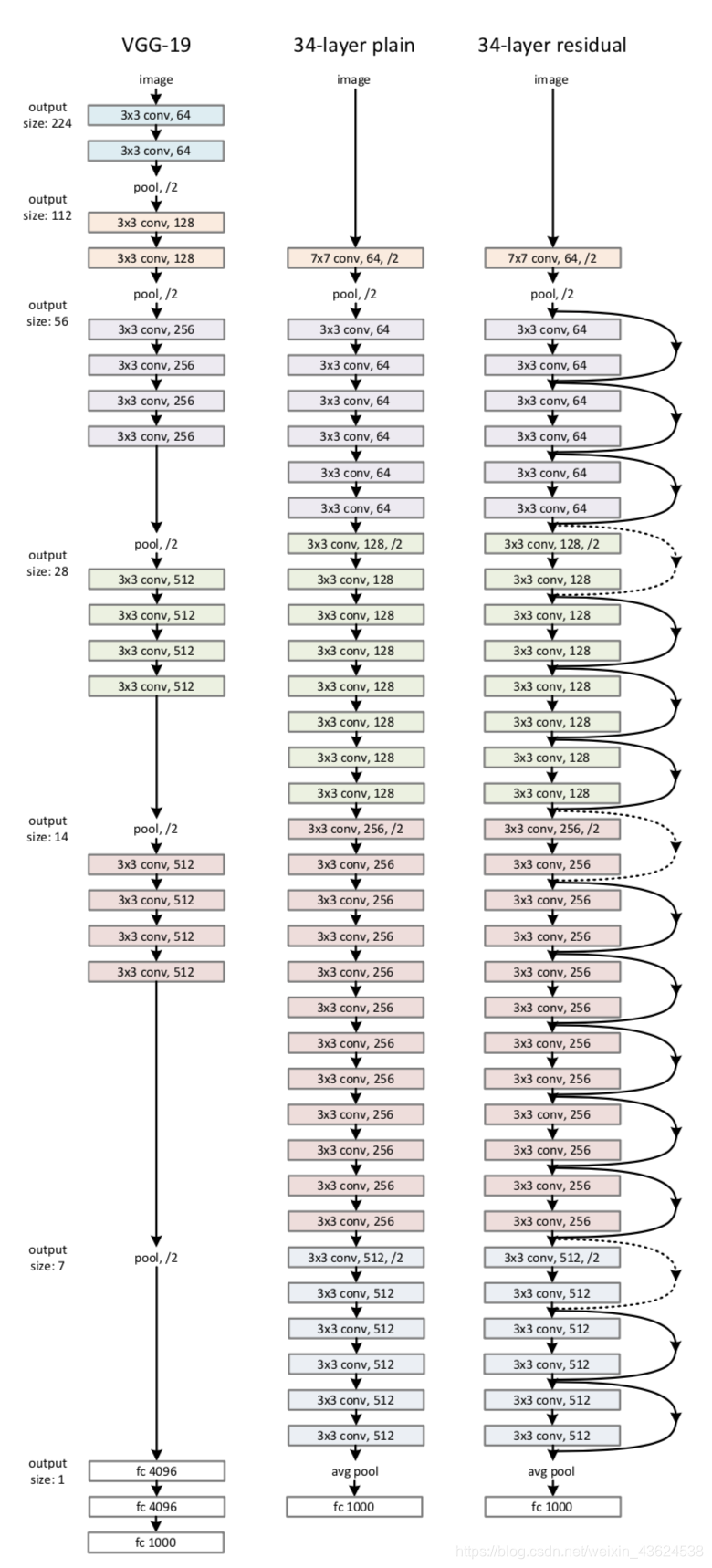

从图5可以发现,对于plain网络,深度增加到34层时,精度反而更低了,而残差网络能够在深度增加的情况下维持强劲的准确率增长,有效地避免了VGG网络中层数增加到一定程度,模型准确度不升反降的问题。论文还注意到,18层普通/残差网具有大致相等的精确率(表2),但18层ResNet的收敛速度更快。

参考资料:
https://blog.csdn.net/weixin_43624538/article/details/85049699
https://blog.csdn.net/briblue/article/details/83544381














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









