







一、前言
在前一篇文章《决策树原理和实践》中,我们介绍了决策树的相关原理和使用API,决策树在建模过程中需要剪枝等操作,而如果数据预处理不当或者剪枝不合理,又会造成过拟合等结果,或者建立的模型只在某个方面表现比较好。此时,我们会考虑建立单棵树模型可能会存在走上“歧途”的现象,那么是不是可以通过建立多棵树模型一起来判断结果呢?答案当然是可以的,具体怎么建立呢?如果使用相同的数据集和算法,那么建立的模型结果大概率也是相同的,就失去了意义。接下来的几篇文章我们将介绍集成学习算法(Ensemble learning)中的Bagging、Boosting、Stacking模型,并以其中几个典型的算法,如随机森林、GBDT进行实践说明。在继续下面的内容之前,建议首先要熟悉决策树的原理,因为很多经典的主流算法,如随机森林、GBDT、LightGBM、Xgboost等都和决策树息息相关。
二、集成学习
集成学习方法的目标是把构建的多个基估计器的预测结果结合起来,从而获得比单个估计器更好的泛化能力/鲁棒性,潜在的思想是即便某一个基学习器得到了错误的预测,其他的基学习器也可以将错误纠正回来。这里就涉及到两个问题:①怎么训练单个学习器,包括训练集的选取、特征的选取以及学习目标;②对于多个学习器的预测结果,该怎么汇总。鉴于这两个问题,集成学习算法主要分为三类:
- Bagging(bootstrap aggregating):Bagging的思想比较简单,从原始样本集中使用Bootstraping的方法有放回的抽取n个训练样本(可能出现有些样本被多次抽到,而有些样本可能一次都没有被抽中),共进行k轮抽取,得到k个训练集,就是建立k个基学习器,最终结果由大家投票/平均值决定,如随机森林算法。当然,这里的基学习器并不局限于决策树,也可以是感知机等。此外,可以发现Bagging算法的多个基学习器训练过程时可以并行进行的。
- Boosting:Boosting是一种可将弱学习器提升为强学习器的算法。其工作机制为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使得先前的基学习器识别错误的训练样本在后面的基学习器中得到更多的关注(调高权重),然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到实现指定的值,或整个集成结果达到退出条件,然后将这些学习器进行加权组合得到最终结果。较具代表性的算法是:GBDT和AdaBoost等。
- Stacking:Stacking模型的重点放在了组合多个基学习器的结果上。首先训练多个不同的模型,然后把之前训练的各个模型的输出作为输入来训练一个新的模型,并得到一个最终的输出。Bagging算法可以认为是一种简化版的Stacking算法。在实际中,我们通常使用logistic回归作为组合模型。
从偏差-方差的角度来说,Boosting主要关注减小偏差(不断拟合偏差值),而Bagging主要关注降低方差(多个基学习器的平均值),也就说明Boosting在弱学习器上表现更好,而降低方差可以减小过拟合的风险,所以Bagging通常在强分类和复杂模型上表现得很好。举个例子:Bagging在不减枝决策树、神经网络等易受样本扰动的学习器上效果更为明显,Boosting则在剪枝决策树上更好。可以这么理解:Bagging结果因为是由所有人投票决定,所以就要求大多数人都要选择正确(每个人都要强),而Boosting是后面的人不断学习前面的人错误的地方,如果前面的人很强,则会导致后面的人没有可学习的东西(在后一篇文章中,介绍完Boosting后,会再比较两者的区别)。下面是一段摘自知乎的关于Bagging和Boosting区别的答案,很生动了:
bagging就是大家都是学渣,每道题都由随机选出的一群学渣投票决定,这样需要的学渣比较多,而且每个学渣还都得很努力学习变强。boosting也是一群学渣,但每个人虽然总分菜,却是因为偏科导致的,每个学渣都贡献自己最擅长的那个题目。这样boosting需要的每个学渣都毫不费力,但是整体上更强了。xgb的学渣还通过预习,让自己偏科的科目学得更省力。所以整体上xgb看起来是非常省力的一群学渣组成,但是拿到的分数却很高。
一般情况下,集成学习的模型效果要好于单模型效果,但这并不是绝对的,尤其是当样本集和所有特征都具有很强的代表性的时候。此外,集成学习的基分类器的数量对结果影响很大,但是目前很少有相关的研究。实践表明,基分类器的数量在增长到一定程度之后带来的提升很小,甚至会出现过拟合现象,因为随着基分类器数量的增加,基分类器之间的差异性就原来越小。最近也有一些研究认为存在一个合适的基学习器数量使得模型取得最优的效果。他们的理论显示使用和分类标签一样多的集成数量会有最优的准确率[3]。
本文我们只介绍Bagging算法,并详细介绍主流的Bagging算法随机森林原理和实践过程,Boosting和Stacking算法将在后面两篇文章中详细介绍。Bagging的原理图如下:
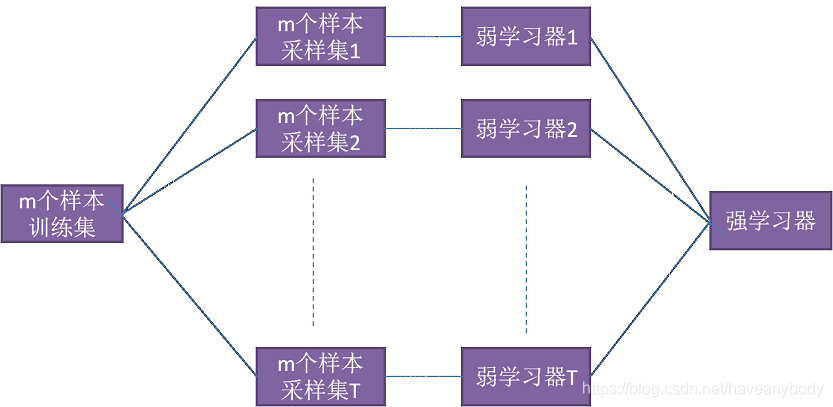
三、随机森林
随机森林(Random Forest,简称RF),是Bagging的一个特化进阶版,所谓的特化是因为随机森林的基学习器都是决策树,所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择,这也是随机森林名称的由来原因,其基本思想没有脱离Bagging的范畴。随机森林是集成学习中可以和梯度提升树GBDT并驾齐驱的算法,尤其是它可以并行训练,在如今大数据大样本的的时代很有优势。
3.1 算法原理
前面已经提到,随机森林中的随机一词不仅仅是对数据集进行有放回的随机采样,而且也会对特征进行随机选择。对于一个含有m个样本的样本集,进行m次又放回的随机采样,则某个样本每次被选中的概率是,不被采集到的概率为
。如果m次采样都没有被采集中的概率是
。当
,
。也就是说,在Bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样到,每个基学习器只使用了63.2%的数据,对于这部分大约36.8%没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, 简称OOB),这些数据没有参与训练集模型的拟合,可以用来检测模型的泛化能力,因此在随机森林中我们可以不设置专门的测试集数据,当然如果模型在oob上的效果就很差,也就没必要在测试集上去测试效果了。RF使用了CART决策树作为基学习器,对于含有n个原始特征的数据集,每个基学习器随机选择d个特征进行训练学习。可知,d越大(越接近n),则基学习器和决策树模型就没有太大区别,即模型的泛化能力就越差;d越小(越接近0),则得到的RF模型越可能出现欠拟合现象。因此,在RF中,有两个重要参数:树的个数 n_estimators 和每个基学习器随机选择的特征数d,一般情况下,推荐尝试设置
或者
。
如果是分类问题,RF的结果由所有基学习器(决策树)的概率结果投票决定,这里需要注意,在新版本的sklearn中,组合策略已不是直接投票决定,而是每个基学习器的类别概率相加决定;如果是回归问题,RF的结果则为所有基学习器的预测结果平均值。可以看出,RF有如下优势:
- 能够处理很高维、大量的数据集,并且不用做特征选择;
- 在训练完成后,可以给出哪些特征比较重要;
- 容易做成并行化方法,速度快,尤其是对于大数据集;
- 可以进行可视化展示,便于分析;
- 对于缺省值问题也能够获得很好得结果,因为随机采样过程可能会不采样确实值记录和特征;
- 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
RF当然也存在缺点:
- 在某些噪音比较大的样本集上,RF模型容易陷入过拟合,因为噪音数据很可能会被多次采样,且被多棵树放大。当然这也是一种相对的情况,相比于Boosting算法,Bagging对噪声点更加不敏感
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。这主要是由于决策树的自身特性带来的,因为取值划分比较多的特征会多次参与决策(分裂)过程
- 由于随机过程的存在,决策树的建模结果具有随机性,同样的参数(不设置随机种子)可能会建立效果不同的模型,为调参带来困难
3.2 算法实践
3.2.1 分类API类
随机森林在sklearn中的分类类定义如下(基于scikit-learn 0.23.2),对于和决策树参数意义相同的参数,这里不再解释,详情可查阅《决策树原理和实践》,里面对所有参数都做了详尽解释:
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, ##树的数量
*,
criterion='gini', ##gini系数或者信息增值率"entropy"
max_depth=None, ##同决策树,默认不限制树深度
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', ##构建单棵树的特征数,默认是全部特征数的平方根,其他参数解释同决策树
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, ##是否使用bootstrap采样(有放回),默认为真,否则使用整个数据集来构建每棵树
oob_score=False, ##是否使用袋外样本(oob)来评估模型泛化精度
n_jobs=None, ##并行的job数,fit、predict、decision_path、apply过程都可并行化,默认是1,-1表示使用所有CPU核。因为进程间通信的原因,该参数和效率并不是正线性相关的
random_state=None, ##控制随机采样样本和特征的随机数种子
verbose=0, ##控制训练和预测时的冗余度,不造什么意思
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None ##当bootstrap=True时,随机抽取的样本数,默认None有放回抽取X.shape[0]个样本,若是整型,则表示抽样max_samples个样本,若是小数,则抽取 max_samples * X.shape[0]个样本,0.22版本加入的新参数
)3.2.2 分类实践
关于RF的分类实践和调参,可以参考资料[4]中的案例,主要通过网格搜索的方法进行调参,至于建模方法,sklearn中的API大多类似,通过fit方法训练模型,predict方法预测结果,这里不再过多介绍。另外,关于RF的建模流程,个人经验认为在特征处理完毕后,可以先使用决策树调参建模和RF不剪枝(只调整n_estimators参数)建模作为两个基准,然后再调整其他参数(前面的决策树模型参数也可以作为调参参考),模型效果和前面两个模型效果作比较选择。下面介绍两个很有意思的例子:第一个,比较不同参数下的oob错误率:
import matplotlib.pyplot as plt
from collections import OrderedDict
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
print(__doc__)
RANDOM_STATE = 123
# Generate a binary classification dataset.
X, y = make_classification(n_samples=500, n_features=25,
n_clusters_per_class=1, n_informative=15,
random_state=RANDOM_STATE)
# NOTE: Setting the `warm_start` construction parameter to `True` disables
# support for parallelized ensembles but is necessary for tracking the OOB
# error trajectory during training.
ensemble_clfs = [
("RandomForestClassifier, max_features='sqrt'",
RandomForestClassifier(warm_start=True, oob_score=True,
max_features="sqrt",
random_state=RANDOM_STATE)),
("RandomForestClassifier, max_features='log2'",
RandomForestClassifier(warm_start=True, max_features='log2',
oob_score=True,
random_state=RANDOM_STATE)),
("RandomForestClassifier, max_features=None",
RandomForestClassifier(warm_start=True, max_features=None,
oob_score=True,
random_state=RANDOM_STATE))
]
# Map a classifier name to a list of (<n_estimators>, <error rate>) pairs.
error_rate = OrderedDict((label, []) for label, _ in ensemble_clfs)
# Map a classifier name to a list of (<n_estimators>, <error rate>) pairs.
error_rate = OrderedDict((label, []) for label, _ in ensemble_clfs)
# Range of `n_estimators` values to explore.
min_estimators = 15
max_estimators = 175
for label, clf in ensemble_clfs:
for i in range(min_estimators, max_estimators + 1):
clf.set_params(n_estimators=i)
clf.fit(X, y)
# Record the OOB error for each `n_estimators=i` setting.
oob_error = 1 - clf.oob_score_
error_rate[label].append((i, oob_error))
# Generate the "OOB error rate" vs. "n_estimators" plot.
for label, clf_err in error_rate.items():
xs, ys = zip(*clf_err)
plt.plot(xs, ys, label=label)
plt.xlim(min_estimators, max_estimators)
plt.xlabel("n_estimators")
plt.ylabel("OOB error rate")
plt.legend(loc="upper right")
plt.show()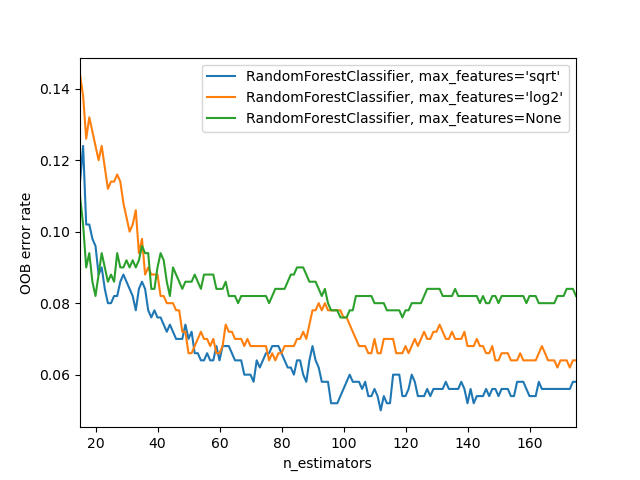
这里解释一下关于oob错误率的计算问题,前面提到每个样本大约有1/3的概率不被采样到,在构建完毕决策树后,不被采样到样本使用大约1/3该样本没有参与训练的树模型得到预测结果,然后这1/3的树模型得到的预测结果投票作为该样本的最终识别结果,最后计算所有判断错误的样本占总样本的比例就是oob错误率,详细解释,可参考资料[7]。
第二个,通过随机森林/GBDT等集成算法做特征转换(类似于降维操作):
import numpy as np
np.random.seed(10)
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import (RandomTreesEmbedding, RandomForestClassifier,
GradientBoostingClassifier)
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.pipeline import make_pipeline
n_estimator = 10
X, y = make_classification(n_samples=80000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# It is important to train the ensemble of trees on a different subset
# of the training data than the linear regression model to avoid
# overfitting, in particular if the total number of leaves is
# similar to the number of training samples
X_train, X_train_lr, y_train, y_train_lr = train_test_split(
X_train, y_train, test_size=0.5)
# Unsupervised transformation based on totally random trees
rt = RandomTreesEmbedding(max_depth=3, n_estimators=n_estimator,
random_state=0)
rt_lm = LogisticRegression(max_iter=1000)
pipeline = make_pipeline(rt, rt_lm)
pipeline.fit(X_train, y_train)
y_pred_rt = pipeline.predict_proba(X_test)[:, 1]
fpr_rt_lm, tpr_rt_lm, _ = roc_curve(y_test, y_pred_rt)
# Supervised transformation based on random forests
rf = RandomForestClassifier(max_depth=3, n_estimators=n_estimator)
rf_enc = OneHotEncoder()
rf_lm = LogisticRegression(max_iter=1000)
rf.fit(X_train, y_train)
rf_enc.fit(rf.apply(X_train))
rf_lm.fit(rf_enc.transform(rf.apply(X_train_lr)), y_train_lr)
y_pred_rf_lm = rf_lm.predict_proba(rf_enc.transform(rf.apply(X_test)))[:, 1]
fpr_rf_lm, tpr_rf_lm, _ = roc_curve(y_test, y_pred_rf_lm)
# Supervised transformation based on gradient boosted trees
grd = GradientBoostingClassifier(n_estimators=n_estimator)
grd_enc = OneHotEncoder()
grd_lm = LogisticRegression(max_iter=1000)
grd.fit(X_train, y_train)
grd_enc.fit(grd.apply(X_train)[:, :, 0])
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
y_pred_grd_lm = grd_lm.predict_proba(
grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
# The gradient boosted model by itself
y_pred_grd = grd.predict_proba(X_test)[:, 1]
fpr_grd, tpr_grd, _ = roc_curve(y_test, y_pred_grd)
# The random forest model by itself
y_pred_rf = rf.predict_proba(X_test)[:, 1]
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_pred_rf)
plt.figure(1)
plt.xlim(0, 0.2)
plt.ylim(0.8, 1)
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr_rt_lm, tpr_rt_lm, label='RT + LR')
plt.plot(fpr_rf, tpr_rf, label='RF')
plt.plot(fpr_rf_lm, tpr_rf_lm, label='RF + LR')
plt.plot(fpr_grd, tpr_grd, label='GBT')
plt.plot(fpr_grd_lm, tpr_grd_lm, label='GBT + LR')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve (zoomed in at top left)')
plt.legend(loc='best')
plt.show()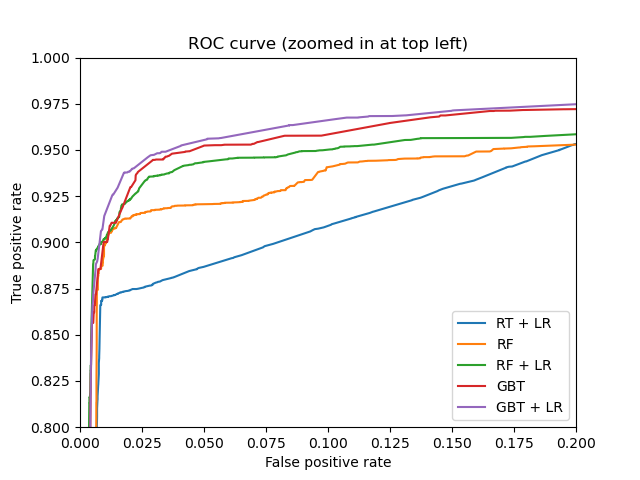
这里需要注意RF的apply方法,返回样本X在每棵树的叶子索引稀疏矩阵,然后就可以用线性模型了。这个思想和SVM里的核函数有点类似,也类似于降维后的onehot再升维操作,在每棵树划分到相同叶子的样本索引值也是相同的。然后通过onehot编码再输入到逻辑回归模型中学习。结果可以发现组合后的效果都比原始单个集成学习模型的效果好,是一种非常具有参考意义的建模思路。
3.2.3 回归API类
回归类参数和分类参数几乎一致,这里不再做过多介绍,具体参数信息和案例可以参考官网资料。另外,和决策树类似,在实际中使用RF做回归模型的概率并不高,因为决策树的回归预测结果往往是阶梯型的,且对于超出训练集的样本往往不能准确预测,即使和训练集满足同样的规律。
class sklearn.ensemble.RandomForestRegressor(n_estimators=100,
*,
criterion='mse',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
ccp_alpha=0.0,
max_samples=None)3.3 Extremely Randomized Trees
极端树(ExtraTrees)是RF的一个变种, 原理几乎和RF一模一样,但是比RF更加极端。ExtraTrees和RF的不同点主要在于:
- 对于每个决策树的训练集,RF采用的是随机采样bootstrap来选择采样集作为每个决策树的训练集,而extra trees一般不采用随机采样,即每个决策树都使用原始训练集,但是在sklearn库的APPI中ExtraTrees类也是有bootstrap参数的,只是不同于RF,默认是False。
- 在RF中或者说是决策树中,决策过程是先遍历每个特征的划分点,计算划分后的GINI系数或者均方差,然后选出最优的划分点。其次比较每个特征基于最优划分点的GINI系数选择当前树节点的决策特征。但是在ExtraTrees中则不同,选择一个特征的划分点时,不再是遍历所有候选划分点,而是随机选择一个划分点(对于离散值,则随机选择一个类别;对于连续值,则随机选择min-max之间的一个值),然后计算基于该划分点的GINI系数或者均方差。第二步就和RF一样了,比较不同特征划分点的GINI系数或者均方差来选择当前树节点的最优决策特征。
由于随机选择了特征值的划分点位,而不是最优点位,这样会导致生成的决策树的规模一般会大于RF所生成的决策树,因为不是最优点,需要进行更多次的划分才能达到和RF同样的效果。也就是说,模型的方差相对于RF进一步减少,但是偏差相对于RF进一步增大。ExtraTrees因为树规模更大,所以空间复杂度更大,但是因为是随机选择划分点,所以时间复杂度会更低。在某些时候,ExtraTrees的泛化能力比RF更好,因为划分点是随机选择的,降低了训练数据对模型的影响。
class sklearn.ensemble.ExtraTreesClassifier(n_estimators=100, *,
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=False, ##RF默认是True
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None)3.4 Totally Random Trees Embedding
Totally Random Trees Embedding(TRTE)是一种基于完全随机树的特征变换(嵌入)。它将低维的数据集映射到高维,从而让映射到高维的数据更好的运用于分类回归模型,如LR等。在SVM中运用了核方法来将低维的数据集映射到高维,此处TRTE提供了另外一种方法。这里需要注意TRTE+LR和3.2.2节第二个案例RF+OneHot+LR的区别,3.2.2节第二个案例中包括了两种方法的程序和效果对比。TRTE是一种非监督学习的数据转化方法,而RF+OneHot是有监督的。TRTE之所以说完全随机正是因为是无监督过程,所以在构造每个决策树的时候,特征选择和特征划分都是随机的(也可以和ExtraTrees的决策树构造过程一起比较下),实质上就是一种特征升维方法。API类定义如下,参数和RF一样:
class sklearn.ensemble.RandomTreesEmbedding(n_estimators=100, *, max_depth=5, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, sparse_output=True, n_jobs=None, random_state=None, verbose=0, warm_start=False)具体使用可以参考3.2.2节的第二个案例,这里再做一个简单的程序解析:
from sklearn.ensemble import RandomTreesEmbedding
from sklearn.preprocessing import OneHotEncoder
from sklearn import tree
X = [[0,0], [1,0], [0,1], [-1,0], [0,-1]]
random_trees = RandomTreesEmbedding(n_estimators=5, random_state=0, max_depth=1).fit(X)
X_sparse_embedding = random_trees.transform(X)
X_sparse_embedding.toarray()
##上述程序等价于下面程序
rf_enc = OneHotEncoder()
rf_enc.fit(random_trees.apply(X)).transform(random_trees.apply(X)).toarray()
##可以通过estimators_属性查看每个基学习器子树
print(random_trees.estimators_)
tree.plot_tree(random_trees.estimators_[0])
3.5 Isolation Forest
Isolation Forest(孤立森林)是一种异常点检测方法,它也使用了类似于RF的方法来检测异常点。大致原理是通过采样学习出T棵树,计算某个测试点在T棵树中的平均深度,然后计算异常概率,详细原理会在后续章节《异常检测》中和one-class svm等异常检测方法一起介绍。
四、 Bagging meta-estimator
上一章介绍了RF的相关知识,实际上RF只是Bagging算法的一个特例,sklearn中也已经封装好了方便调用的Bagging meta-estimator API供我们自己去封装基学习器(如KNN、SVM等)来构造集成算法,通过随机化操作来降低基学习器的方差。相关API如下:
class sklearn.ensemble.BaggingClassifier(base_estimator=None, ##基学习器,默认None是决策树
n_estimators=10, ##基学习器数量
*,
max_samples=1.0, ##基学习器采样的样本数,如果是整型,则表示采样数量,如果是小数,则表示采样比例,默认1.0是X.shape[0]
max_features=1.0, ##基学习器学习的特征数,如果是整型,则表示特征数,如果是小数,则表示采样特征比例,默认1.0是X.shape[1]
bootstrap=True, ##是否有放回采样
bootstrap_features=False, ##Whether features are drawn with replacement
oob_score=False,
warm_start=False,
n_jobs=None,
random_state=None,
verbose=0)例如,封装一个基于KNN和SVC的Bagging模型:
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
bagging = BaggingClassifier(KNeighborsClassifier(),max_samples=0.5, max_features=0.5)
clf = BaggingClassifier(SVC(),n_estimators=10, random_state=0)
clf.fit()
......
参考资料
[1] https://www.cnblogs.com/pinard/p/6131423.html
[2] https://www.cnblogs.com/pinard/p/6156009.html
[3] https://www.datalearner.com/blog/1051538295125157
[4] https://www.cnblogs.com/pinard/p/6160412.html
[5] https://www.zhihu.com/question/27068705
[6] https://www.zhihu.com/question/20448464
[7] https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm#ooberr

















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









