






前言
本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。
代码及工具箱
本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码
正文
图片识别
在机器学习和神经网络的世界里,对于不想深入了解复杂原理的初学者来说,有一个非常适合入门的项目,那就是手写体数字识别。这个任务的目标很明确,就是教会计算机识别手写的数字。
手写体数字识别通常会用到一个叫做MNIST的数据集,它包含了许多28×28像素的手写数字图片。这些图片是灰度图,每个像素点的灰度值从0(黑色)到255(白色)不等,不同的灰度值组合起来就形成了我们看到的数字形状。
但是,手写数字并不像打印的字体那样规整,每次写同一个数字,都可能因为各种原因(比如手抖)而略有不同。这就给计算机识别带来了挑战,因为不能简单地根据像素值来判断数字。
为了解决这个问题,我们可以使用神经网络,它具有一定的容错能力。我们知道如何搭建神经网络,现在的问题是如何把图片数据输入到网络中。
神经网络需要的输入是多维向量,而图片是由像素点组成的二维数组。解决的办法是把图片的每一行像素值依次展开,形成一个一维数组。对于28×28像素的图片,这将形成一个784维的向量,或者说一个有784个元素的数组。我们只需要把MNIST数据集中的每张图片都转换成这样的784维数组,然后输入到神经网络中进行训练。
最初,人们使用深度全连接神经网络来处理这个问题,取得了不错的效果,但还有改进的空间。
训练集和测试集 vs 过拟合和欠拟合
在机器学习中,我们用训练集来训练模型,希望模型在这里表现得很好,意味着它学到了数据的规律。但我们更关心的是模型在新的数据上的表现,这就是测试集的作用。一个好的模型应该在测试集上也有高准确率,这表明它不仅能在训练数据上表现好,也能很好地应对它从未见过的新数据,也就是有好的泛化能力。
如果模型在训练集上表现差,那它基本上就是没用的,这种情况叫做欠拟合,可能是因为模型太简单了。
如果模型在训练集和测试集上都表现得很好,那说明模型泛化能力强。
但如果模型只在训练集上表现好,在测试集上表现差,那就是过拟合了。过拟合可能是因为模型太复杂,学到了训练数据中的噪声,而不是真正的规律。比如,如果我们用一个复杂的模型去拟合一个简单的问题,就像豆豆数据集的例子,模型在训练集上可能非常精确,但在测试集上就表现不佳。
这有点像学生平时做习题死记硬背,考试时却考不好,因为他们没有真正理解知识点。
要解决过拟合,我们可以调整模型结构,或者使用一些技术比如L2正则化、Dropout等。这些方法可以帮助模型更好地泛化。
最后,如果一个模型在训练集上表现差,但在测试集上表现好,这种情况几乎不会发生。
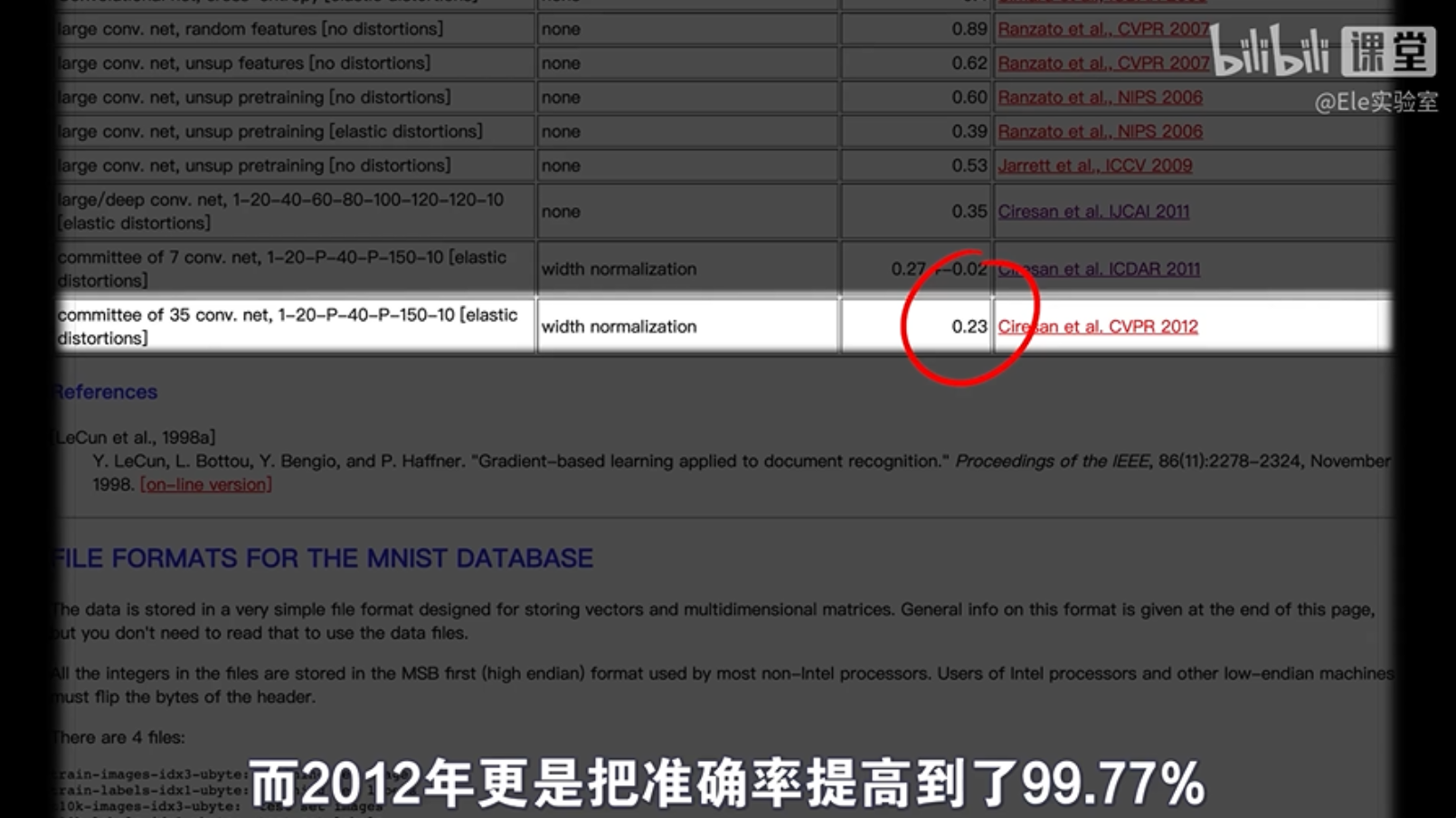
Lecun表格
MNIST数据集是一个包含手写数字的图片集合,它由6万张训练图片和1万张测试图片组成。长期以来,研究人员一直在用各种方法尝试识别这些手写数字。
尽管全连接神经网络在图像识别方面取得了不错的进展,但随着网络深度和神经元数量的增加,性能的提升变得越来越困难。Yann LeCun,一个深度学习领域的领军人物,制作了一个详细的表格,展示了不同机器学习方法在MNIST数据集上的表现,包括线性分类器、K最近邻(KNN)、提升方法、支持向量机(SVM),以及不同类型的神经网络。
评价模型好坏的标准是在测试集上的错误率。只有当模型在测试集上的错误率很低时,我们才认为它具有强大的泛化能力。
到目前为止,纯粹的深度神经网络中表现最好的是一个2010年的6层网络,它达到了0.35%的错误率。这个网络的规模非常大,每层有数千个神经元。研究者们坦率地表示,他们之所以能达到这样的效果,是因为他们拥有强大的计算资源,特别是能加速训练的高性能显卡。

在MNIST手写数字识别问题上,使用纯全连接的深度神经网络似乎已经达到了某种极限。即使我们不断增加网络的大小和复杂度,也很难再有显著的性能提升。这种情况,用现在流行的话来说,就是“内卷”了,意味着单纯的数量增加并不能带来质量的飞跃,而且内卷在任何情况下都是不利的。
为了突破这种局限,研究者们开始尝试另一种类型的神经网络——卷积神经网络(CNN)。卷积神经网络在MNIST数据集上取得了显著的成果。例如,早在1998年提出的LeNet-5,一个经典的卷积神经网络,就能达到99.2%的准确率。到了2012年,准确率更是提高到了99.77%。
卷积神经网络之所以有效,是因为它们能够捕捉图像数据中的局部特征并逐层构建更为复杂和抽象的特征表示,这使得它们在图像识别任务上表现得非常出色。
卷积怎么工作
卷积神经网络(CNN)的工作原理可能听起来有点复杂,但让我们用简单的方式理解它。
想象一下,我们把一张图片转换成了一个由很多数字组成的长列表,这些数字代表了图片中每个像素的亮度。如果我们只看这些数字,很难知道图片上是什么,就像一串数字很难让人联想到一个茶杯或口罩。
人类在看图片时,大脑会自动寻找图片中的特征,比如形状、颜色和纹理。这些特征帮助我们快速识别物体。但是,如果我们把图片转换成一维的数字序列,就会丢失这些有用的空间信息。
举个例子,假设有两种虚构的东西,我们称之为“咕叽咕叽”和“呱啦呱啦”。尽管它们看起来完全不同,但如果我们只看到它们转换后的数字序列,就很难区分它们。
这说明,图片中的空间特征对于识别和分类非常重要。卷积神经网络之所以强大,就是因为它能够保留和利用这些空间特征,而不是简单地将图像信息降维成一维。
通过提取图像的关键特征,CNN能够提高模型的泛化能力,即使面对新的、未见过的数据,也能做出准确的判断。这就是为什么卷积神经网络在图像识别任务上如此有效。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









