






-
数据至上: 深度学习依赖数据的数量和质量,很大程度影响模型性能的好坏
-
数据增强: 利用现有的数据产生等价于数据扩增的价值,提高模型的泛化能力
-
数据增强技术分为有监督的和无监督的
-
有监督的数据增强
-
图像领域的几何变换(如翻转,旋转,裁剪,变形,缩放等),颜色变换(如随机噪点,模糊,扰动,擦除填充)
-
SMOTE: 基于K近邻随机插值,将小样本合并成新的样本,常用于解决数据不均衡的分类问题
-
算法基本流程:
-
第一步,定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定好一个采样倍率N;
-
第二步,对每一个小样本类样本(x,y),按欧氏距离找出K个最近邻样本,从中随机选取一个样本点,假设选择的近邻点为(xn,yn)。在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新样本点,满足以下公式:
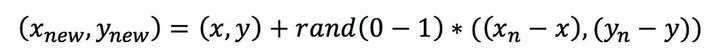
-
第三步,重复以上的步骤,直到大、小样本数量平衡。
-
-
python库: imbalanced-learn封装了基本SMOTE算法及变体
from imblearn.over_sampling import SMOTE, ADASYN from imblearn.over_sampling import BorderlineSMOTE from imblearn.over_sampling import SVMSMOTE from imblearn.over_sampling import KMeansSMOTE from imblearn.over_sampling import SMOTENC # 应用示例,使用SMOTENC对原数据插值扩充产生新的样本集 smote_nc = SMOTENC(categorical_features=[0, 2], random_state=0) X_resampled, y_resampled = smote_nc.fit_resample(X, y)
-
-
mixup
-
基于线性插值,令(xn,yn)是插值生成的新数据,(xi,yi)和(xj,yj)是训练集随机选取的两个数据,则数据生成方式如下
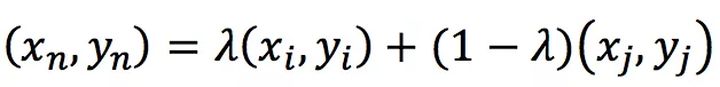
-
-
-
无监督的数据增强
-
GAN
-
通过模型学习数据的分布,随机生成与训练数据集分布一致的图片
-
包含两个网络,一个是生成网络,一个是对抗网络,基本原理如下:
-
G是一个生成图片的网络,它接收随机的噪声z,通过噪声生成图片,记做G(z) 。
-
D是一个判别网络,判别一张图片是不是“真实的”,即是真实的图片,还是由G生成的图片。
-
在训练过程中,**生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。**这样,G和D构成了一个动态的“博弈过程”。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OSUQAKsw-1616749679333)(https://www.pianshen.com/images/705/6c3feaf375a4b55950c17e49597b2a41.png)]
-
-
-
Autoaugmentation
- 基本思路是使用增强学习从数据本身寻找最佳图像变换策略,对于不同的任务学习不同的增强方法
-
-
深度学习数据增强方法小结




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











