







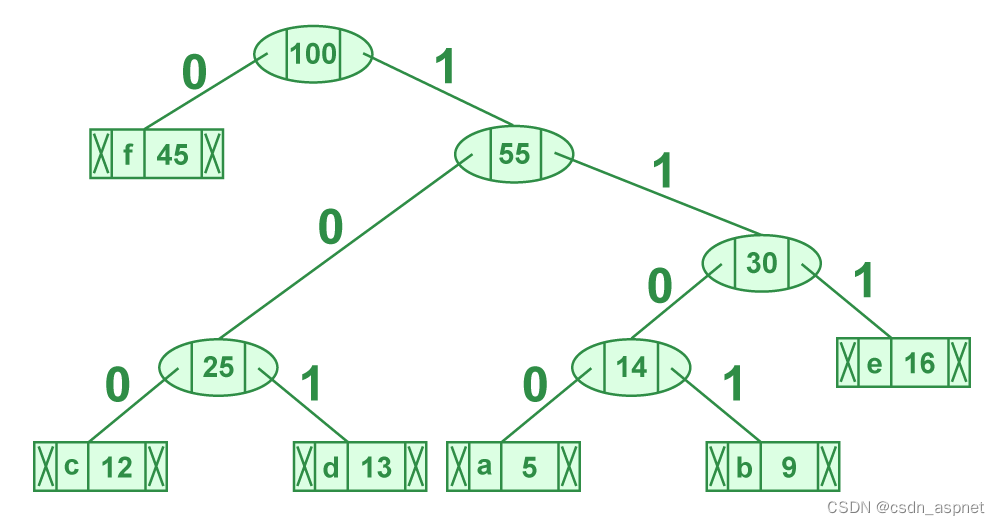
排序输入的高效霍夫曼编码 示例图
建议先阅读下面的文章:
c语言:c语言 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)_霍夫曼的贪婪c语言-CSDN博客
c++:c++ 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)_霍夫曼的贪婪算法设计核心代码-CSDN博客
c#:C# 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)-CSDN博客
c++ STL:c++ STL 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)-CSDN博客
java:java 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)-CSDN博客
python:python 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)-CSDN博客
javascript:JavaScript 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)-CSDN博客
上面讨论的算法的时间复杂度是 O(nLogn)。如果我们知道给定的数组是排好序的(按频率非递减顺序),我们可以在 O(n) 时间内生成霍夫曼码。以下是针对已排序输入的 O(n) 算法。
1.创建两个空队列。
2.为每个唯一字符创建一个叶节点,并按频率非递减顺序将其入队到第一个队列。最初第二个队列是空的。
3.通过检查两个队列的前面,使两个频率最小的节点出队。重复以下步骤两次
1. 如果第二个队列为空,则从第一个队列出队。
2. 如果第一个队列为空,则从第二个队列出队。
3. 否则,比较两个队列的前面,并使最小的节点出队。
4.创建一个新的内部节点,其频率等于两个节点频率之和。将第一个出队节点设为其左子节点,将第二个出队节点设为右子节点。将此节点入队到第二个队列。
5.重复步骤 3 和 4,直到队列中有多个节点。剩下的节点就是根节点,树就完成了。
示例代码:
# Python3 program for Efficient Huffman Coding
# for Sorted input
# Class for the nodes of the Huffman tree
class QueueNode:
def __init__(self, data = None, freq = None,
left = None, right = None):
self.data = data
self.freq = freq
self.left = left
self.right = right
# Function to check if the following
# node is a leaf node
def isLeaf(self):
return (self.left == None and
self.right == None)
# Class for the two Queues
class Queue:
def __init__(self):
self.queue = []
# Function for checking if the
# queue has only 1 node
def isSizeOne(self):
return len(self.queue) == 1
# Function for checking if
# the queue is empty
def isEmpty(self):
return self.queue == []
# Function to add item to the queue
def enqueue(self, x):
self.queue.append(x)
# Function to remove item from the queue
def dequeue(self):
return self.queue.pop(0)
# Function to get minimum item from two queues
def findMin(firstQueue, secondQueue):
# Step 3.1: If second queue is empty,
# dequeue from first queue
if secondQueue.isEmpty():
return firstQueue.dequeue()
# Step 3.2: If first queue is empty,
# dequeue from second queue
if firstQueue.isEmpty():
return secondQueue.dequeue()
# Step 3.3: Else, compare the front of
# two queues and dequeue minimum
if (firstQueue.queue[0].freq <
secondQueue.queue[0].freq):
return firstQueue.dequeue()
return secondQueue.dequeue()
# The main function that builds Huffman tree
def buildHuffmanTree(data, freq, size):
# Step 1: Create two empty queues
firstQueue = Queue()
secondQueue = Queue()
# Step 2: Create a leaf node for each unique
# character and Enqueue it to the first queue
# in non-decreasing order of frequency.
# Initially second queue is empty.
for i in range(size):
firstQueue.enqueue(QueueNode(data[i], freq[i]))
# Run while Queues contain more than one node.
# Finally, first queue will be empty and
# second queue will contain only one node
while not (firstQueue.isEmpty() and
secondQueue.isSizeOne()):
# Step 3: Dequeue two nodes with the minimum
# frequency by examining the front of both queues
left = findMin(firstQueue, secondQueue)
right = findMin(firstQueue, secondQueue)
# Step 4: Create a new internal node with
# frequency equal to the sum of the two
# nodes frequencies. Enqueue this node
# to second queue.
top = QueueNode("$", left.freq + right.freq,
left, right)
secondQueue.enqueue(top)
return secondQueue.dequeue()
# Prints huffman codes from the root of
# Huffman tree. It uses arr[] to store codes
def printCodes(root, arr):
# Assign 0 to left edge and recur
if root.left:
arr.append(0)
printCodes(root.left, arr)
arr.pop(-1)
# Assign 1 to right edge and recur
if root.right:
arr.append(1)
printCodes(root.right, arr)
arr.pop(-1)
# If this is a leaf node, then it contains
# one of the input characters, print the
# character and its code from arr[]
if root.isLeaf():
print(f"{root.data}: ", end = "")
for i in arr:
print(i, end = "")
print()
# The main function that builds a Huffman
# tree and print codes by traversing the
# built Huffman tree
def HuffmanCodes(data, freq, size):
# Construct Huffman Tree
root = buildHuffmanTree(data, freq, size)
# Print Huffman codes using the Huffman
# tree built above
arr = []
printCodes(root, arr)
# Driver code
arr = ["a", "b", "c", "d", "e", "f"]
freq = [5, 9, 12, 13, 16, 45]
size = len(arr)
HuffmanCodes(arr, freq, size)
# This code is contributed by Kevin Joshi
输出:
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
时间复杂度: O(n)
如果输入未排序,则需要先对其进行排序,然后才能通过上述算法进行处理。排序可以使用堆排序或合并排序来完成,两者都在 Theta(nlogn) 中运行。因此,对于未排序的输入,总体时间复杂度变为 O(nlogn)。
辅助空间: O(n)
















 5869
5869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









