







 1.课程概述1.1定义技术定义:数据挖掘(data mining)就是从大量变的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。商业定义:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。1.2研究对象数据—关系型数据库,事务
1.课程概述1.1定义技术定义:数据挖掘(data mining)就是从大量变的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。商业定义:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。1.2研究对象数据—关系型数据库,事务
1.课程概述
1.1定义
技术定义:数据挖掘(data mining)就是从大量变的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
商业定义:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。
1.2研究对象
数据
—关系型数据库,事务性数据库,面向对象的数据框
—数据仓库,多维数据库
—空间数据
—工程数据
—文本和多媒体数据
—时间相关的数据
—万维网(半结构化的html,结构化的XML)
1.3目的
描述:了解数据中潜在的规律
预测:用历史预测未来
1.4应用领域
解决典型商业问题:
—数据库营销(database marketing)
—客户群体划分(customer segmentation & classification)
—背景分析(profile analysis)
—交叉销售(cross-selling)
—客户流失性分析(credit analysis)
—客户信用记分(credit scoring)
—欺诈侦测(fraud detection)
—...等等
1.5实施步骤
教科书步骤:

实际业务应用的步骤:
情况一:有数据,没想法
数据探索(了解缺失值情况和数据类型...),数据预处理(),明确挖掘任务(),选择技术方案(),结果信息()。
情况二:有想法,没数据
明确挖掘任务(),收集数据(),数据预处理(),选择技术方案(),结果信息()
DIKW体系(Data-to-Information-to-Knowledge-to-Wisdom)
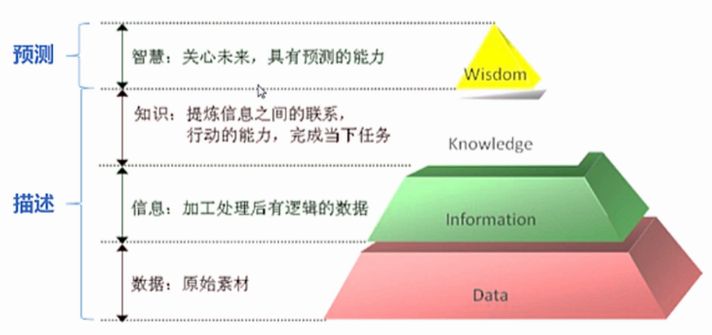
1.6技术原理
-关联分析
-分类
-聚类
-异常检测
-...其他
2.数据预处理
数据预处理(data preprocessing):是指在主要的处理以前对数据进行的一些处理。
—数据质量问题:数据太乱,数据质量差,影响后续数据挖掘结果的准确性。
—数据数量问题:数据太多,导致后续数据挖掘过程的开销太大,但未必能较大提高挖掘结果质量;数据太少,某些数据挖掘中需 要的关键属性缺少,影响数据挖掘结果的准确性。
数据质量问题
—数据不完整:缺少某些属性或某些感兴趣的属性。
—数据不正确或含噪声:包含错误或存在偏离期望的值。
—数据不一致:如用于商品分类的部门编码存在差异。
—数据时效性差:如进行近期预测,数据却是一年前的数据。
—数据可信度不高:曾经出现过错误数据,导致新数据可信度差。
—数据不可解释:使用了其他特殊编码,无法知道数据所表达的含义。
数据数量问题
—存储类型太多:存在不同的数据库中,数据结构不同。
—属性太多:数据的变量太多。
—条目太多:数据记录的条数太多。
—分类变量类别多:某个离散性变量类别很多。
—关键属性缺少:数据挖掘过程中所需的关键属性太少。
—数据层次太少:汇总数据较多,导致数据数量较少。
数据预处理技术
—数据清洗:解决数据质量太乱的问题
—数据压缩:解决数据数量太多的问题
—数据构造:解决数据数量太少的问题

2.1数据清理
缺失数据
处理缺失数据的步骤:
—步骤1:识别缺失数据
-NA代表缺失值,不可得到这个数;
-NaN代表不可能的值,不是一个数;
-Inf,-Inf分别代表正无穷和负无穷。
—步骤2:探究缺失数据
-缺失数据的比例
-缺失数据集中程度
-缺失数据的机制:
-完全随机缺失(MCAR):若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失。(简单删除)
-随机缺失(MAR):若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺 失。(建立回归模型进行预测)
-非随机缺失(NMAR):若缺失数据不属于MCAR或MAR,则数据为非随机缺失。(模型选择法和模式混合法)
—步骤3:处理缺失数据
-删除法:观测样本删除,变量删除,完全变量分析,无回答权重。
-填补法:单变量填补(简单随机填补,均值填补,回归填补,热平台和冷平台,随机回归填补法等),多变量填补(多 重填补法等)。
噪声数据
噪声数据(noisy data)定义:无意义的数据(meaningless data)。
噪声数据产生的原因:硬件故障、编程错误或者语音或光学字符识别程序中的乱码;拼写错误、行业简称和俚语也会阻碍机器读取。
噪声数据处理原则:不是所有的噪声数据都要处理掉,必须事先判断出这些离群的点是否会阻碍后面的数据挖掘任务,部分情况下噪声数据是需要保留的重要信息。
噪声数据处理方法:分箱、回归、聚类等。

不一致数据
不一致数据:编码使用的不一致,数据表示的不一致。
不一致数据处理方法:通常需要人工检测,当发现一定规律时可以通过编程进行替换和修改;若存在不一致的数据是无意义数据,可以使用缺失值处理方法进行相应处理。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









