







机器学习——评价指标
1、结果统计
1.1 混淆矩阵表示
| 正样本 | 负样本 | |
|---|---|---|
| 正样本 | True Positive(TP) | False Negative(FN) |
| 负样本 | False Positive(FP) | True Negative (TN) |
TP:将正样本识别为正样本的数量或者比例
FN: 将正样本识别成负样本的数量或者比例
FP:将负样本识别成正样本的数量或者比例
TN :将负样本识别成负样本的数量或者比例
1.2 准确率,精确率和召回率
准确率:
Y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Y=\frac{TP +TN}{TP+TN+FP+FN}
Y=TP+TN+FP+FNTP+TN
表示所有的样本被分类正确的概率。
精确率(查准率):
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
在所有识别出来的正样本中,真正为正样本的概率。
召回率(查全率):
R
=
T
P
T
P
+
F
N
R = \frac{TP}{TP+FN}
R=TP+FNTP
在所有的正样本中,被准确识别的概率。
准确率和召回率是一对相对矛盾的度量,一般情况下,精确率越高的时候,召回率越低。也就是说,我们如果想要提高召回率,那就需要增加样本分类为正的数量,如所有的样本的分类均为正,那么精确率自然的提升了,因为所有实际上为正的样本均被识别成正样本。但是这难免会增加FP的值,也就引起了精确率的降低。
1.3 多数据集下的相关指标
当我们用一个模型去训练多个数据集的时候,会产生对个混淆矩阵。或者,在一个数据集上训练测试多次的时候,也会产生多个混淆矩阵。当产生多个混淆矩阵的时候,如何计算相关指标?这里有两个个简单常用的方法。
- 分别对各个混淆矩阵计算
(
p
1
,
r
1
)
,
.
.
.
.
.
,
(
p
n
,
r
n
)
(p_1,r_1),.....,(p_n,r_n)
(p1,r1),.....,(pn,rn),然后对各个p和r取平均值,生成全局的精确率和召回率:
m i r c o P = ∑ i = 1 n p i mircoP = ∑_{i=1}^np_i mircoP=i=1∑npi
m i r c o R = ∑ i = 1 n r i mircoR = ∑_{i=1}^nr_i mircoR=i=1∑nri
m a r c o F 1 = 2 ∗ m i c r o P ∗ m i c r o R m i c r o P + m i c r o R marcoF1 = \frac{2*microP*microR}{microP+microR} marcoF1=microP+microR2∗microP∗microR - 先计算,各个混淆矩阵中的TP,FP,TN,FN的的平均值
T P m e a n , F P m e a n , T N m e a n , F N m e a n TP_{mean},FP_{mean},TN_{mean},FN_{mean} TPmean,FPmean,TNmean,FNmean,然后再根据这些来计算相关指标
m i c r o P = T P m e a n T P m e a n + F P m e a n microP=\frac{TP_{mean}}{TP_{mean}+FP_{mean}} microP=TPmean+FPmeanTPmean
m i c r o R = T P m e a n T P m e a n + F N m e a n microR=\frac{TP_{mean}}{TP_{mean}+FN_{mean}} microR=TPmean+FNmeanTPmean
m i c r o F 1 = 2 ∗ m i c r o P ∗ m i c r o R m i c r o P + m i c r o P microF1=\frac{2*microP*microR}{microP+microP} microF1=microP+microP2∗microP∗microR
2、相关曲线
2.1 P-R曲线
我们将精确率和召回率的联合曲线称为:P-R曲线,如下图所示:
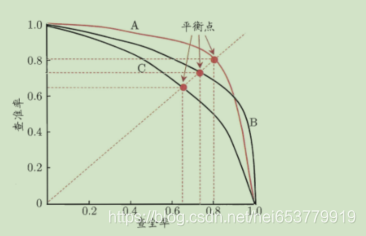
在上面的图示中,如果模型1的P-R曲线完全在模型2的P-R曲线之上,那么就可以认为模型1优于模型2。
BEP平衡点:
在该点上,精确率=召回率,一般认为该点的数值越高,模型越优。
F1值:
F1值是基于P和R的调和平均:
1
F
1
=
1
2
∗
(
1
P
+
1
R
)
\frac{1}{F1}=\frac{1}{2}*(\frac{1}{P}+\frac{1}{R})
F11=21∗(P1+R1)
F
1
=
2
∗
P
∗
R
P
+
R
=
2
∗
T
P
样
本
总
数
+
T
P
−
T
N
F1=\frac{2*P*R}{P+R}=\frac{2*TP}{样本总数+TP-TN}
F1=P+R2∗P∗R=样本总数+TP−TN2∗TP
同样,F1值越高,模型越优。
F1还有更一般的形式:
F
β
=
(
1
+
β
2
)
∗
P
∗
R
(
β
2
∗
P
)
+
R
F_β=\frac{(1+β^2)*P*R}{(β^2*P)+R}
Fβ=(β2∗P)+R(1+β2)∗P∗R
其中β>0度量了召回率对于精确率的重要性。β>1时,召回率更重要,β<1时,精确率更重要。
2.2 ROC曲线与AUC曲线
我们现在假设TP,FN,FP,TN均为概率,则四者的关系为:
TP + FN = 1
FP + TN = 1
真正例率:
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP}{TP+FN}
TPR=TP+FNTP
假正例率:
F
P
R
=
F
P
T
N
+
F
P
FPR=\frac{FP}{TN+FP}
FPR=TN+FPFP
我们以假正例率为横轴,真正利率为纵轴,构建出一个相关的曲线,我们称之为ROC曲线。称ROC曲线包裹的面积为AUC。具体如下图所示:
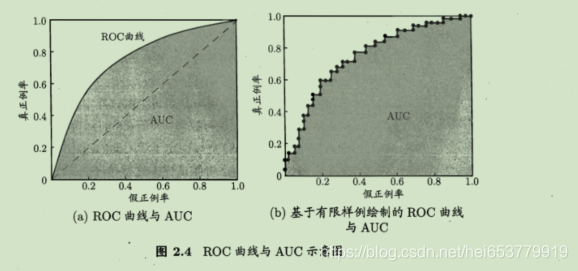
进行学习器比较的时候,与P-R曲线类似,当模型1的ROC曲线包裹了模型2的ROC曲线的时候,模型1更优。
另外一种比较是通过AUC的大小,AUC的估计计算公式为:
A
U
C
=
1
2
∑
i
=
1
m
=
1
(
x
i
+
1
−
x
i
)
∗
(
y
i
+
y
i
+
1
)
AUC = \frac{1}{2}∑_{i=1}^{m=1}(x_{i+1}-x_i)*(y_i+y_{i+1})
AUC=21i=1∑m=1(xi+1−xi)∗(yi+yi+1)
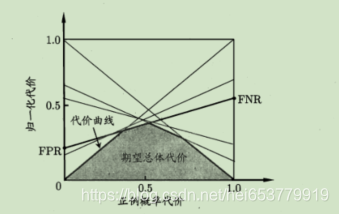
2.3 代价敏感函数和代价曲线
在实际的任务中,分类错误所造成的代价可能是不同的,比如,将正例分类为负例的代价是1,而将负例分类为正例的代价为0.5。据此,我们可以构建出来一个代价矩阵。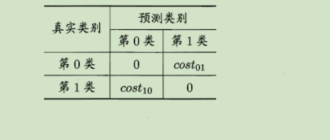
其中,将第0类的样本分类为第1类的代价为
c
o
s
t
01
cost_{01}
cost01,将第1类样本分类为第0类的代价为
c
o
s
t
10
cost_{10}
cost10。在之前假设的FN,FP等指标中,计算的都是分类错误的次数,但是并没有指出错误的代价,也可以默认将分类错误的代价是相同的。在存在代价不同分类任务中,我们的目标不再是分类错的次数降低,而是期望分类错误造成的代价是最小的。
我们假设
D
+
D^+
D+为正例集,
D
−
D^-
D−为反例集。则存在代价敏感的错误率为:
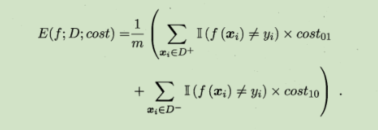
在这种情况下,单纯的依赖ROC曲线是不能刻画总体代价的,我们采用“代价曲线”的度量方式,其中横轴采用:
P
(
+
)
c
o
s
t
=
p
∗
c
o
s
t
01
p
∗
c
o
s
t
01
+
(
1
−
p
)
∗
c
o
s
t
10
P(+)cost=\frac{p*cost_{01}}{p*cost_{01}+(1-p)*cost_{10}}
P(+)cost=p∗cost01+(1−p)∗cost10p∗cost01
其中,p是样本为正例的概率,纵轴采用的是取值为[0,1]的归一化代价:
c
o
s
t
n
o
r
m
=
F
N
R
∗
p
∗
c
o
s
t
01
+
F
P
R
∗
(
1
−
p
)
∗
c
o
s
t
10
p
∗
c
o
s
t
01
+
(
1
−
p
)
∗
c
o
s
t
10
cost_{norm}=\frac{FNR*p*cost_{01}+FPR*(1-p)*cost_{10}}{p*cost_{01}+(1-p)*cost_{10}}
costnorm=p∗cost01+(1−p)∗cost10FNR∗p∗cost01+FPR∗(1−p)∗cost10
其中,FRP是假正例率,FNR = 1 - TPR是假反例率。图示如下:
3 参考文献
周志华 《机器学习》

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









