









过去进行数据库设计是比较繁琐的,需要自己一句句进行 “Create Table”的动作,或者是自己一个个在数据库里创建好记录以后导出,或者是在文档中通过表格形式设计好数据库,然后再创建成为SQL。
这些都是效率不够高,如何提升数据库设计的效率,在Ai时代,完全可以考虑借助 Cursor + Claude/Gemini 来加速这个过程。
新的AI生成基础数据表结构设计流程
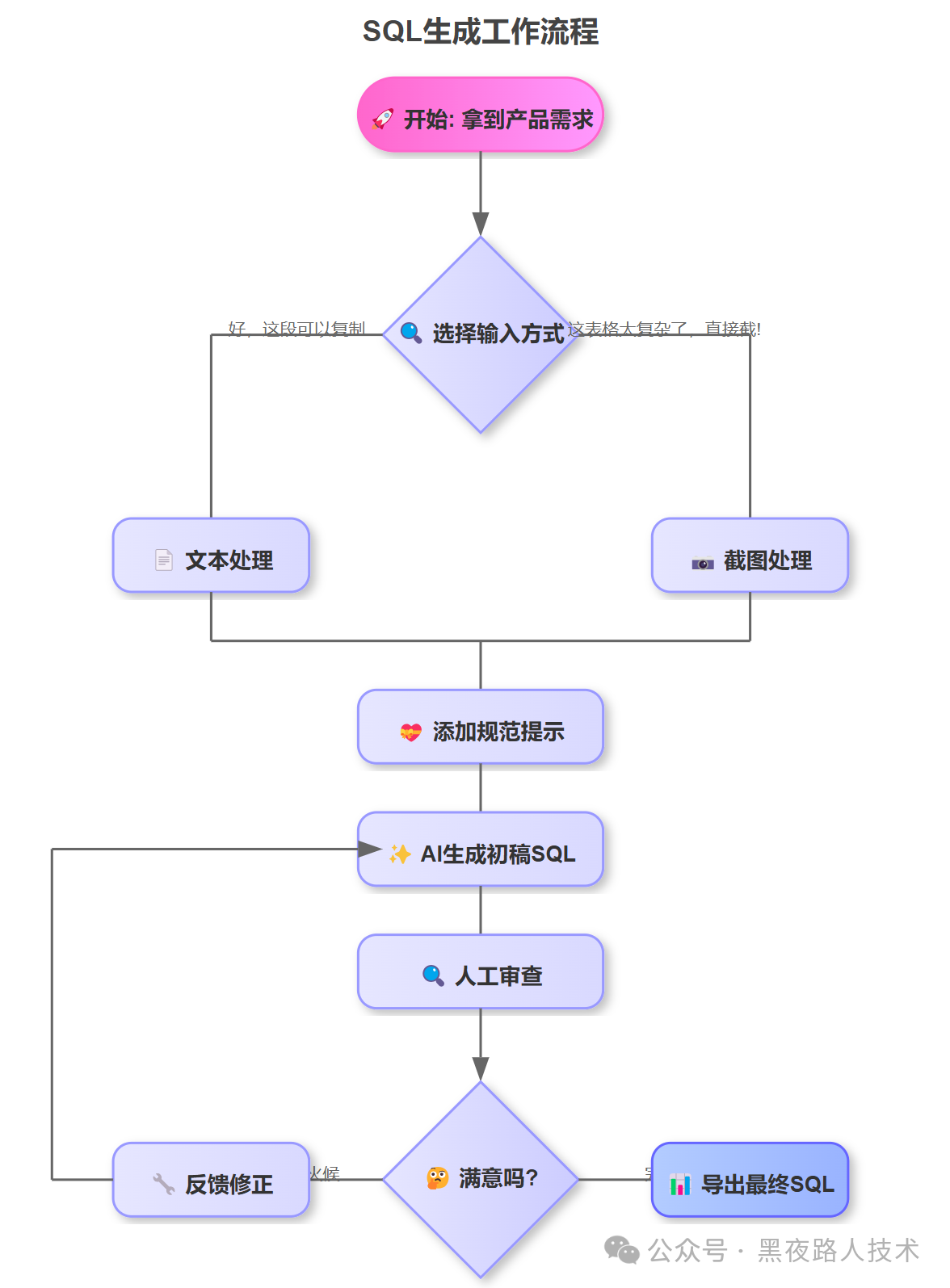
第一步、整理产品需求文档(PRD)
-
1. 原始需求文档不是越多越好,AI容易晕而导致幻觉(过拟合),尽量给一些关键信息给大模型
-
2. 一些灌的细节:
- 遇到复杂表格、原型图、流程图?别再手动整理了!直接截图保存。
- 实战技巧:我发现对于那些有表格结构的需求,最好同时截取表头和实例数据,这样AI能更准确推断字段类型和长度。
- 某些特别长的PRD文档,比如50页word,可能只需要其中10页最关键就可以了,太多反而坏事
- 对于那些格式整齐的文字需求,复制粘贴更高效。

第二步、让AI生成对应的基础SQL
生成要求:
- 使用 Cursor + Claude(3.5/3.7都可,Gemini也可)
- 需要给AI的提示词模版,在这个过程中第一个提示词比较重要,最好可以把约定的数据库规范和表结构设计规范都融入进去,方便AI更好的工作。
给示范的SQL生成Prompt模版参考:
1. 生成PostgreSQL的prompt模版(可以保存为 sql-create-template.md)
我有一个[应用类型]系统需求,请帮我设计最优数据库结构。
【任务说明】
分析我提供的需求(图片/文本),设计符合以下要求的数据库:
1. 提取核心业务实体与关系
2. 设计符合规范的表结构
3. 生成完整SQL
**必须遵循的数据库设计原则:**
* **命名规范**:
* 表名 `模块名_实体名` (如 `user_op`)。
* 字段名 `snake_case`,力求**简洁、明确,避免不必要的缩写**。
* 索引名 `idx_字段名` 或 `uk_字段名` (唯一索引)。
* 表和关键字段必须有**清晰的中文注释**。
* **基础字段 (我们团队的标准)**:
* 所有表必须包含 `id` (bigserial primary key), `created_at` (timestamp not null), `updated_at` (timestamp not null), `deleted_at` (timestamp null default null, 用于软删除)。
* 根据需要包含 `status` (smallint not null default 1, 注释状态含义), `lang` (varchar(10) not null default 'zh-CN', 注释语言含义), `created_by` (bigint not null), `updated_by` (bigint not null)。
* **字段类型选择**:
* 优先选择最合适、最高效的类型和长度。
* 字符串:**根据预估最大长度选用 `VARCHAR(n)`,仅在必要时(如长文本内容)使用 `TEXT`**。
* 数字:整数用 `INTEGER` 或 `BIGINT` (根据范围),**小数/金额务必使用 `NUMERIC(m,n)`**。
* 时间:时间戳用 `TIMESTAMP`,若只需日期用 `DATE`。
* 布尔值/简单枚举:使用 `SMALLINT`,并在注释中说明含义 (例如 `状态 (0:禁用, 1:启用)`)。
* **枚举/状态处理**:
* **简单、固定枚举 (如状态)**: 使用 `SMALLINT` 并加注释说明。
* **(备选方案)** 对于复杂、可能变化或需后台管理的枚举值,可考虑设计专门的**字典表 (Dictionary Table)** 模式,但这非本模板默认要求。
* **索引设计**:
* 主键自带索引。
* 为所有**经常用于查询条件 (WHERE)、排序 (ORDER BY)、分组 (GROUP BY) 的字段或字段组合**创建索引 (`CREATE INDEX idx_...`)。
* 为需要保证**唯一性的字段或字段组合**创建 `CREATE UNIQUE INDEX uk_...`。
* 遵循最左前缀原则设计复合索引。
* **避免过度索引**,权衡查询性能提升与写入性能损耗。
* **其他重要规范**:
* **严格禁止在数据库层面使用外键约束 (FOREIGN KEY)**,关联逻辑在应用层保证。
* 为字段设置**合理且明确的 `DEFAULT` 值** (如 `0`, `''`, `'默认值'`, `CURRENT_TIMESTAMP`),或显式允许 `NULL` ( `DEFAULT NULL`)。
**请严格按照以下 SQL 模板生成 `CREATE TABLE` 语句(业务字段需根据 PRD 智能填充):**
```sql
-- 示例模板,仅供参考结构,具体字段需智能生成
DROP TABLE IF EXISTS 模块名_表名;
CREATE TABLE 模块名_表名 (
id BIGSERIAL PRIMARY KEY,
-- === 业务字段 (请根据PRD智能填充) ===
title VARCHAR(255) NOT NULL,
content TEXT NULL,
price NUMERIC(10, 2) NOT NULL DEFAULT 0.00,
user_email VARCHAR(128) NULL,
-- === 标准字段 (按需添加) ===
status SMALLINT NOT NULL DEFAULT 1,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
deleted_at TIMESTAMP NULL DEFAULT NULL,
created_by BIGINT NOT NULL,
updated_by BIGINT NOT NULL
);
-- 添加表和字段注释
COMMENT ON TABLE 模块名_表名 IS '表说明 (请根据PRD智能生成)';
COMMENT ON COLUMN 模块名_表名.id IS '主键ID';
COMMENT ON COLUMN 模块名_表名.title IS '标题示例 (使用VARCHAR)';
COMMENT ON COLUMN 模块名_表名.content IS '内容示例 (必要时使用TEXT)';
COMMENT ON COLUMN 模块名_表名.price IS '价格示例 (使用NUMERIC)';
COMMENT ON COLUMN 模块名_表名.user_email IS '用户邮箱 (可能需要唯一索引)';
COMMENT ON COLUMN 模块名_表名.status IS '状态 (0:禁用, 1:启用)';
COMMENT ON COLUMN 模块名_表名.created_at IS '创建时间';
COMMENT ON COLUMN 模块名_表名.updated_at IS '更新时间';
COMMENT ON COLUMN 模块名_表名.deleted_at IS '删除时间 (软删除标记)';
COMMENT ON COLUMN 模块名_表名.created_by IS '创建人用户ID';
COMMENT ON COLUMN 模块名_表名.updated_by IS '最后更新人用户ID';
-- === 常用索引 (按需添加) ===
CREATE INDEX idx_模块名_表名_status ON 模块名_表名(status);
-- === 其他业务索引 (请根据PRD智能添加) ===
CREATE INDEX idx_模块名_表名_created_at ON 模块名_表名(created_at);
CREATE UNIQUE INDEX uk_模块名_表名_user_email ON 模块名_表名(user_email);
-- CREATE INDEX idx_模块名_表名_combo_example ON 模块名_表名(field_a, field_b); -- 复合索引示例
```
请将所有表的 SQL 语句统一完整输出,不要中途省略或分开输出。2. 生成用于MySQL数据库的Prompt模版(可以保存为 sql-create-template.md)
我有一个[应用类型]系统需求,请帮我设计最优数据库结构。
【任务说明】
分析我提供的需求(图片/文本),设计符合以下要求的数据库:
1. 提取核心业务实体与关系
2. 设计符合规范的表结构
3. 生成完整SQL
**必须遵循的数据库设计原则:**
* **命名规范**:
* 表名 `模块名_实体名` (如 `user_op`)。
* 字段名 `snake_case`,力求**简洁、明确,避免不必要的缩写**。
* 索引名 `idx_字段名` 或 `uk_字段名` (唯一索引)。
* 表和关键字段必须有**清晰的中文注释**。
* **基础字段 (我们团队的标准)**:
* 所有表必须包含 `id` (bigint unsigned auto_increment primary key), `created_at` (datetime not null), `updated_at` (datetime not null), `deleted_at` (datetime null default null, 用于软删除)。
* 根据需要包含 `status` (tinyint not null default 1, 注释状态含义), `lang` (varchar(10) not null default 'zh-CN', 注释语言含义), `created_by` (bigint unsigned not null), `updated_by` (bigint unsigned not null)。
* **字段类型选择**:
* 优先选择最合适、最高效的类型和长度。
* 字符串:**根据预估最大长度选用 `VARCHAR(n)`,仅在必要时(如长文本内容)使用 `TEXT` 或 `LONGTEXT`**。
* 数字:整数用 `INT` 或 `BIGINT` (根据范围),**小数/金额务必使用 `DECIMAL(m,n)`**。
* 时间:时间戳用 `DATETIME`,若只需日期用 `DATE`。
* 布尔值/简单枚举:使用 `TINYINT`,并在注释中说明含义 (例如 `COMMENT '状态 (0:禁用, 1:启用)'`)。
* **枚举/状态处理**:
* **简单、固定枚举 (如状态)**: 使用 `TINYINT` 并加注释说明。
* **(备选方案)** 对于复杂、可能变化或需后台管理的枚举值,可考虑设计专门的**字典表 (Dictionary Table)** 模式,但这非本模板默认要求。
* **索引设计**:
* 主键自带索引。
* 为所有**经常用于查询条件 (WHERE)、排序 (ORDER BY)、分组 (GROUP BY) 的字段或字段组合**创建索引 (`INDEX idx_...`)。
* 为需要保证**唯一性的字段或字段组合**创建 `UNIQUE KEY uk_...`。
* 遵循最左前缀原则设计复合索引。
* **避免过度索引**,权衡查询性能提升与写入性能损耗。
* **其他重要规范**:
* 存储引擎统一使用 `InnoDB`。
* 字符集统一使用 `utf8mb4`,排序规则 `utf8mb4_unicode_ci`。
* **严格禁止在数据库层面使用外键约束 (FOREIGN KEY)**,关联逻辑在应用层保证。
* 为字段设置**合理且明确的 `DEFAULT` 值** (如 `0`, `''`, `'默认值'`, `CURRENT_TIMESTAMP`),或显式允许 `NULL` ( `DEFAULT NULL`)。
**请严格按照以下 SQL 模板生成 `CREATE TABLE` 语句(业务字段需根据 PRD 智能填充):**
-- 示例模板,仅供参考结构,具体字段需智能生成
DROP TABLE IF EXISTS `模块名_表名`;
CREATE TABLE `模块名_表名` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
-- === 业务字段 (请根据PRD智能填充) ===
`title` VARCHAR(255) NOT NULL COMMENT '标题示例 (使用VARCHAR)',
`content` TEXT NULL COMMENT '内容示例 (必要时使用TEXT)',
`price` DECIMAL(10, 2) NOT NULL DEFAULT 0.00 COMMENT '价格示例 (使用DECIMAL)',
`user_email` VARCHAR(128) NULL COMMENT '用户邮箱 (可能需要唯一索引)',
-- === 标准字段 (按需添加) ===
`status` tinyint NOT NULL DEFAULT 1 COMMENT '状态 (0:禁用, 1:启用)',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL COMMENT '更新时间',
`deleted_at` datetime NULL DEFAULT NULL COMMENT '删除时间 (软删除标记)',
`created_by` bigint UNSIGNED NOT NULL COMMENT '创建人用户ID',
`updated_by` bigint UNSIGNED NOT NULL COMMENT '最后更新人用户ID',
PRIMARY KEY (`id`) USING BTREE,
-- === 常用索引 (按需添加) ===
INDEX `idx_status` (`status`) USING BTREE,
-- === 其他业务索引 (请根据PRD智能添加) ===
INDEX `idx_created_at` (`created_at`) USING BTREE,
UNIQUE KEY `uk_user_email` (`user_email`) USING BTREE, -- 唯一索引示例
-- INDEX `idx_combo_example` (`field_a`, `field_b`) USING BTREE -- 复合索引示例
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci COMMENT '表说明 (请根据PRD智能生成)';
请将所有表的 SQL 语句统一完整输出,不要中途省略或分开输出。使用Cursor如下:(把需求文档作为截图形式发送给Cursor)
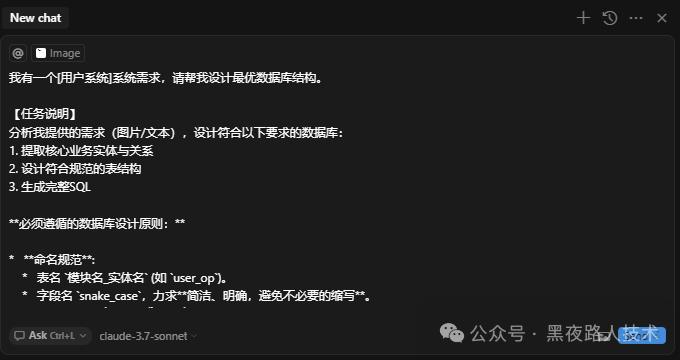
Cursor输出的第一轮结果:
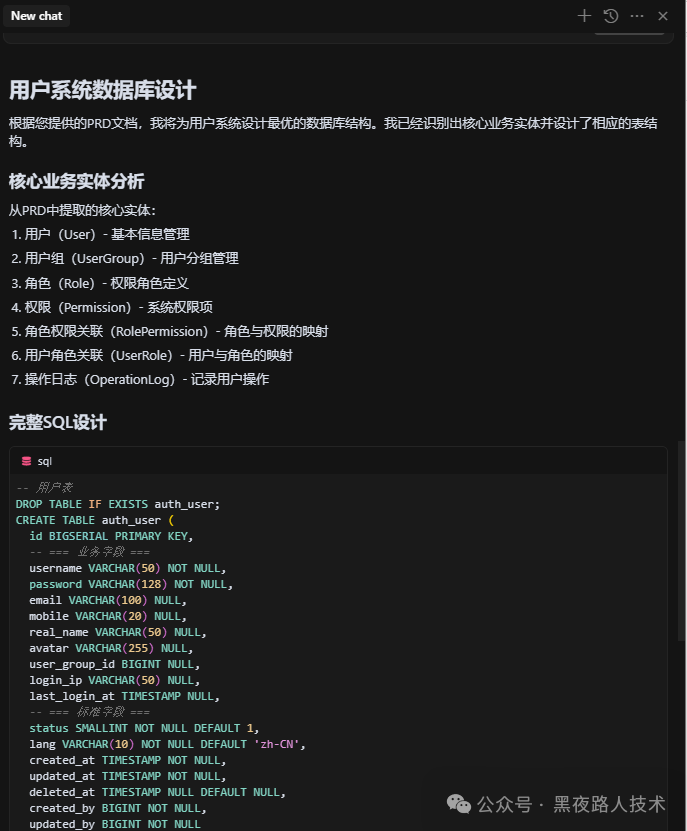
//省略其他SQL

第三步、循环迭代达到最好效果
上面生成了,但是不一定符合你的要求,所以需要进行一个迭代过程:
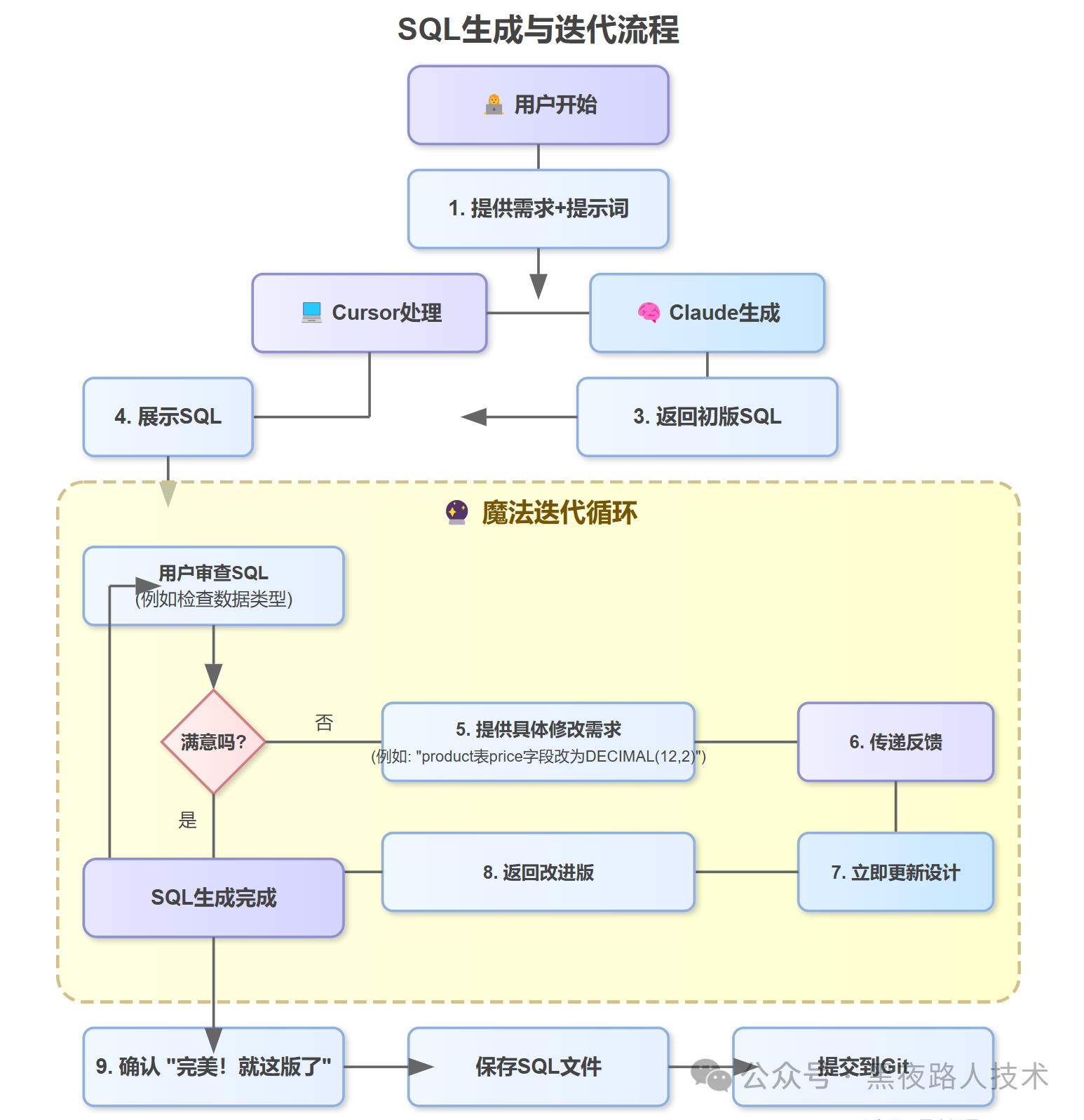
迭代过程中需要考虑几个要素:
- 需求覆盖:所有业务场景都能支持吗?
- 规范遵循:命名、类型、注释都符合团队标准吗?
- 扩展性:未来可能的业务变化能平滑支持吗?
- 性能考量:大数据量下会有瓶颈吗?索引设计合理吗?
在迭代过程中对任何一个设计或者字段不满意,可以直接让AI进行修改:
- 用户表需要增加 mobile 字段,类型为 VARCHAR(20),并添加唯一约束。
- 用户状态字段设计改进:状态字段可以设计为枚举类型,状态值包括:0为激活,1已激活,2已冻结,3已删除,4未知账户
- 用户表的 comment 字段(假设存在)类型应该改为 TEXT,因为 VARCHAR(255) 太小了。
第四步、把SQL生成数据表关系图
如果想要让整个设计出来的数据库表结构更清晰,容易理解,或者是整合到设计文档中,那么可以进一步生成相应的数据表关系图。
这个步骤也可以让Cursor和AI帮助我们:
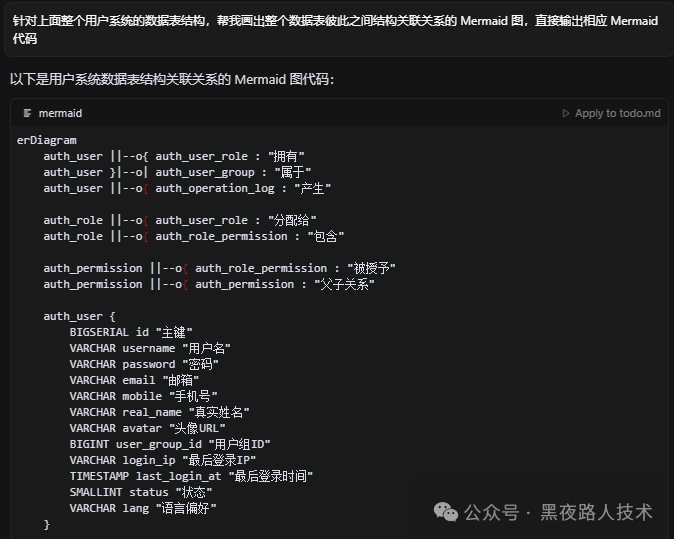
那么经过这个操作,我们就可以得到一张结构清晰的数据表关系图:
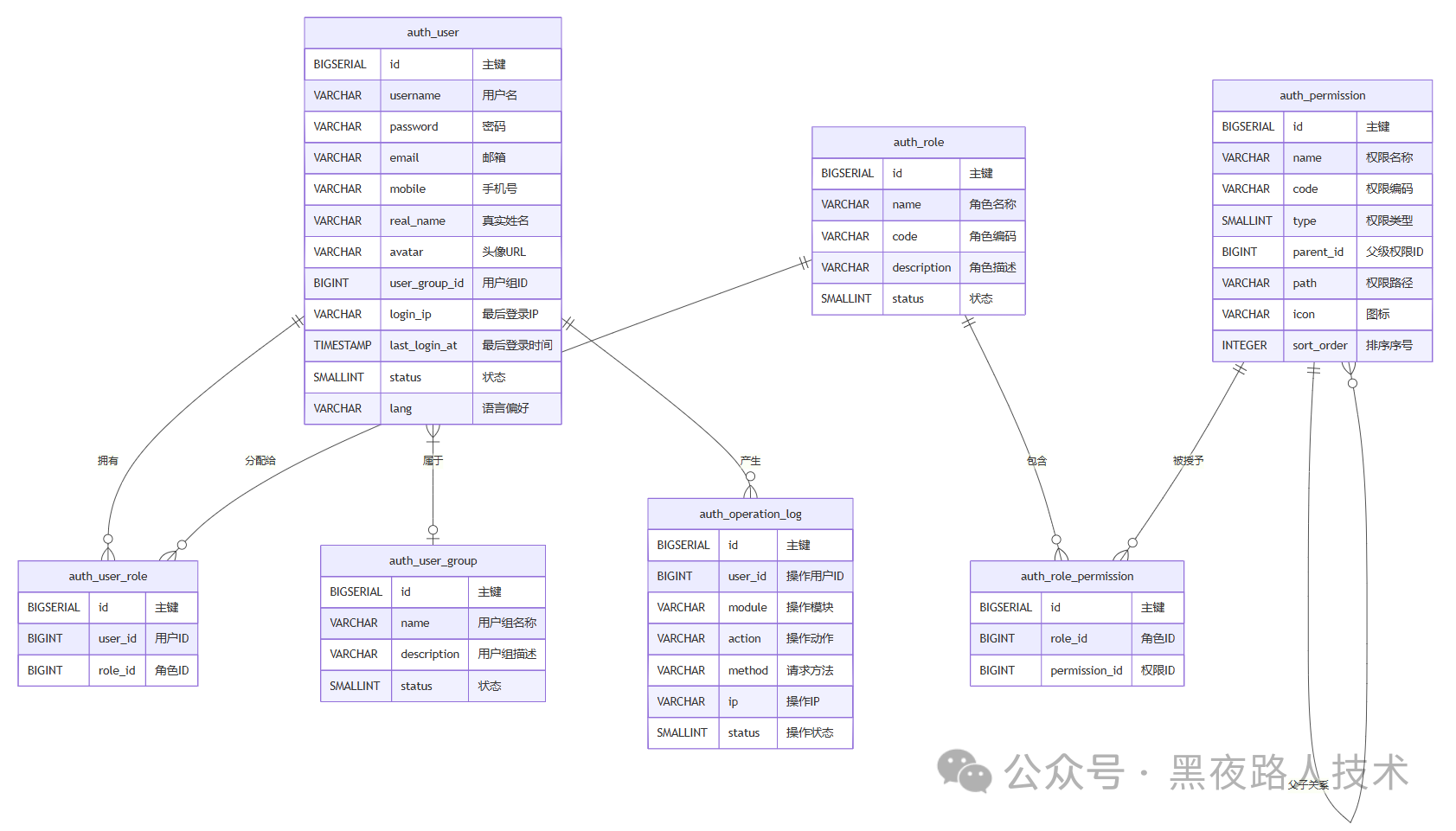
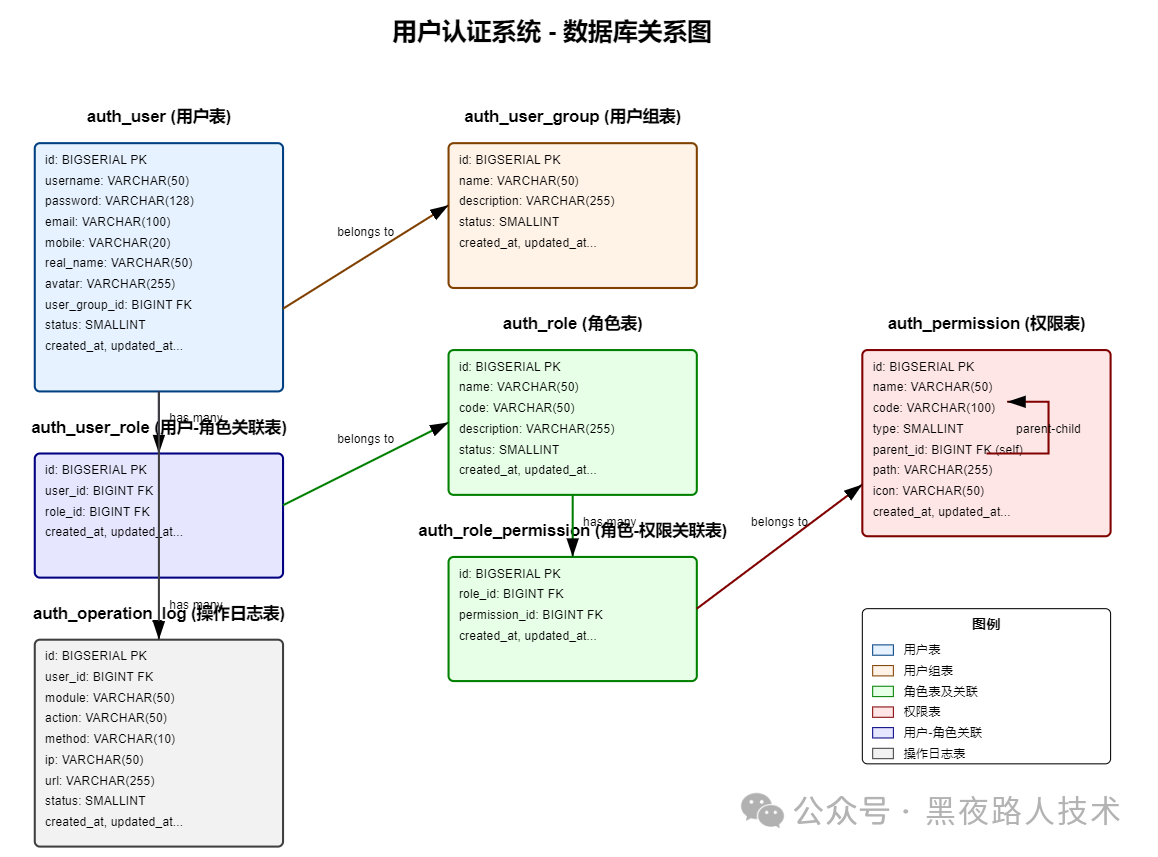
当然,我们也可以直接把SQL给能够画图的LLM,也可以直接得到类似的图(只是上面方式可以全部Cursor搞定而已),比如ER图这种,形式选自己喜欢的,生成的类似的图形样式:
第五步、把SQL生成配套的说明文档和API
在SQL语句生成以后,可以让AI辅助你生成整个数据表结构设计的文档,可以生成类似于Markdown的格式,方便对应说明介绍,以及后续针对SQL或者md文档进行API设计生成,或者是DAO/Models 层的代码生成。
1. 生成数据表结构说明文档
比如针对上面的这个用户表结构:
-- 用户表
DROP TABLE IF EXISTS auth_user;
CREATE TABLE auth_user (
id BIGSERIAL PRIMARY KEY,
-- === 业务字段 ===
username VARCHAR(50) NOT NULL,
password VARCHAR(128) NOT NULL,
email VARCHAR(100) NULL,
mobile VARCHAR(20) NULL,
real_name VARCHAR(50) NULL,
avatar VARCHAR(255) NULL,
user_group_id BIGINT NULL,
login_ip VARCHAR(50) NULL,
last_login_at TIMESTAMP NULL,
-- === 标准字段 ===
status SMALLINT NOT NULL DEFAULT 1,
lang VARCHAR(10) NOT NULL DEFAULT 'zh-CN',
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
deleted_at TIMESTAMP NULL DEFAULT NULL,
created_by BIGINT NOT NULL,
updated_by BIGINT NOT NULL
);
-- 添加表和字段注释
COMMENT ON TABLE auth_user IS '用户表';
COMMENT ON COLUMN auth_user.id IS '主键ID';
COMMENT ON COLUMN auth_user.username IS '用户名';
COMMENT ON COLUMN auth_user.password IS '密码(加密存储)';
COMMENT ON COLUMN auth_user.email IS '邮箱';
COMMENT ON COLUMN auth_user.mobile IS '手机号';
COMMENT ON COLUMN auth_user.real_name IS '真实姓名';
COMMENT ON COLUMN auth_user.avatar IS '头像URL';
COMMENT ON COLUMN auth_user.user_group_id IS '用户组ID';
COMMENT ON COLUMN auth_user.login_ip IS '最后登录IP';
COMMENT ON COLUMN auth_user.last_login_at IS '最后登录时间';
COMMENT ON COLUMN auth_user.status IS '状态 (0:禁用, 1:启用)';
COMMENT ON COLUMN auth_user.lang IS '语言偏好';
COMMENT ON COLUMN auth_user.created_at IS '创建时间';
COMMENT ON COLUMN auth_user.updated_at IS '更新时间';
COMMENT ON COLUMN auth_user.deleted_at IS '删除时间 (软删除标记)';
COMMENT ON COLUMN auth_user.created_by IS '创建人用户ID';
COMMENT ON COLUMN auth_user.updated_by IS '最后更新人用户ID';
-- 添加索引
CREATE UNIQUE INDEX uk_auth_user_username ON auth_user(username) WHERE deleted_at IS NULL;
CREATE UNIQUE INDEX uk_auth_user_email ON auth_user(email) WHERE deleted_at IS NULL AND email IS NOT NULL;
CREATE UNIQUE INDEX uk_auth_user_mobile ON auth_user(mobile) WHERE deleted_at IS NULL AND mobile IS NOT NULL;
CREATE INDEX idx_auth_user_status ON auth_user(status);
CREATE INDEX idx_auth_user_user_group_id ON auth_user(user_group_id);然后要求它生成整个说明文档,方便保存共享容易理解:
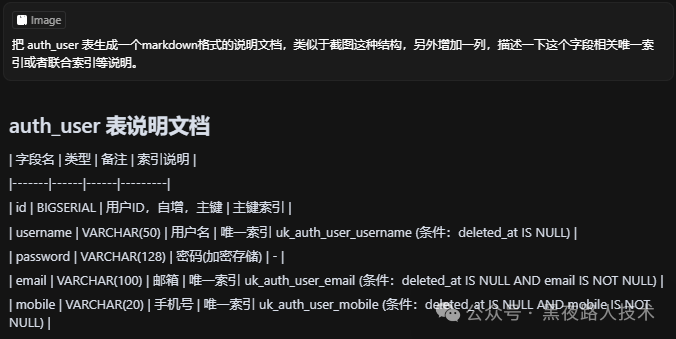
输出类似于下面结构:
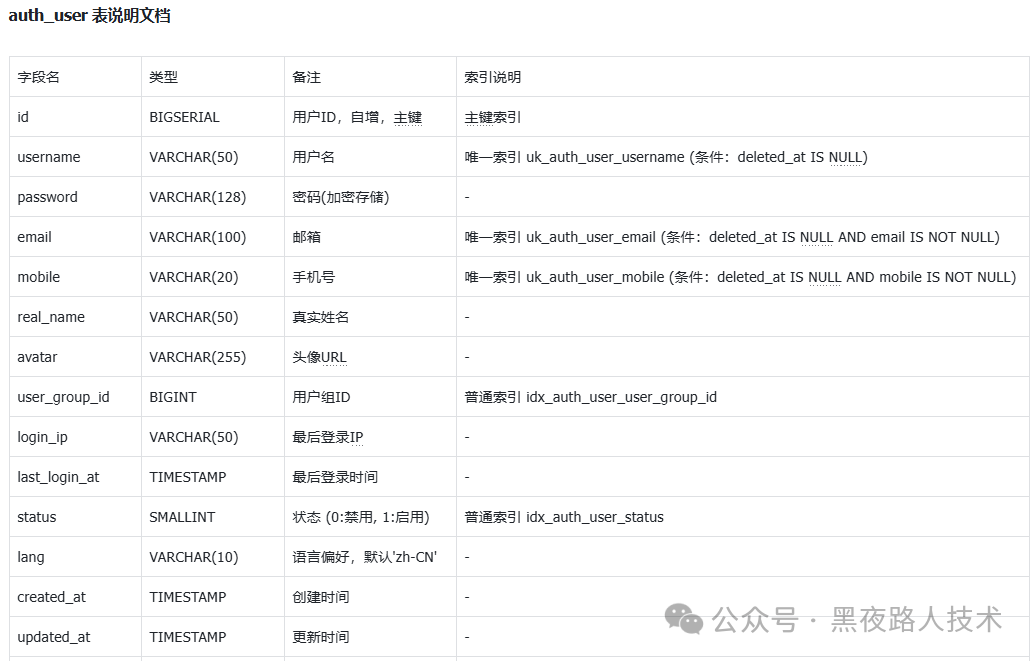
2. 生成API接口设计
如果我们想进一步“偷懒”,也可以针对数据表结构设计,然后结合PRD文档,生成基本的API接口。
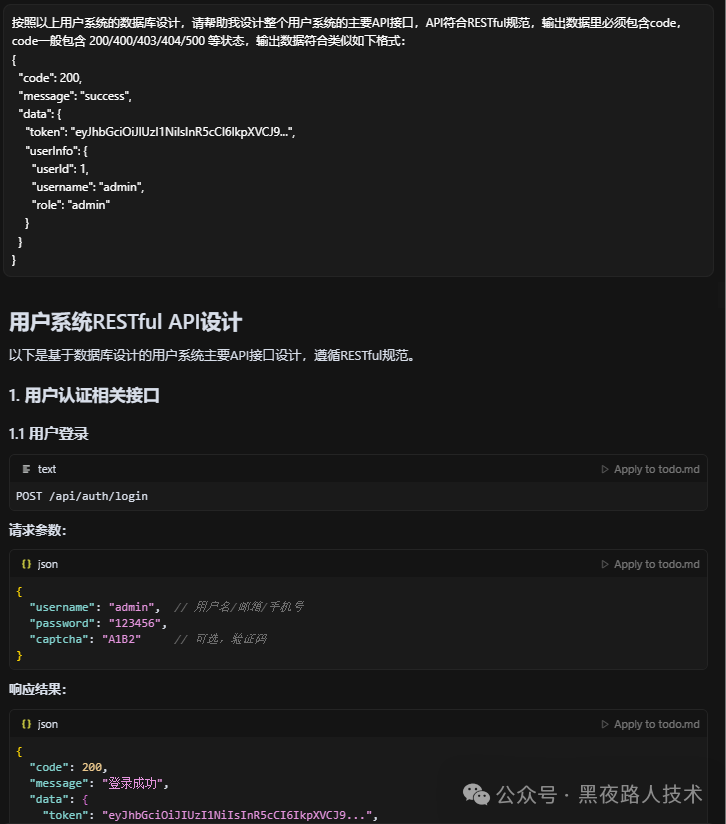
总结
从上面的过程可以看到,我们逐步慢慢的距离从一个PRD到基本Coding的过程越来越近了,逐步迭代整个过程,持续提升开发效率。
AI大模型不是洪水猛兽,用好它,让它真正为你服务,而不是被它控制和驾驭,物尽其用,不役于物。
【大模型介绍电子书】
要获取本书全文PDF内容,请在【黑夜路人技术】VX后台留言:“AI大模型基础” 或者 “大模型基础” 就会获得电子书的PDF。

















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









