






转自知乎 Kissrabbit
最近还在忙于毕设,大概需要加深网络的深度,但是,在这个过程中,发现了一个问题,很多时候,一个8层更加复杂的网络的效果远不及一个3层相对简单的网路的效果(当然,也有可能是因为本人调参水平菜的一笔),这然我挺头疼的,因为,网络简单了,学习出来的模型实在是不好使,想复杂一些,加深网络深度,但无奈不仅仅没有效降低train_error,反而还加重了训练的压力,苦恼了好一阵子,,,后来,想起了ResNet,于是去读了读其论文(https://arxiv.org/pdf/1512.03385v1.pdf),发现,这不正是我所期望的方法嘛!
按照文章的说法,ResNet可以做到在不断加深网络的深度的同时,还能降低train_error,解决了梯度弥散的问题,提高网络的性能,最重要的是,ResNet不仅可以很深,而且,网络的结构还很简单,就是用很单一的小模块堆砌起来的,其单元模块block如下图所示:
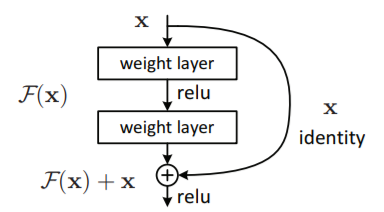
如果我们把一个网络的输出定义为 ,残差定义为
,那么,ResNet其实就是在学习这个残差
,通过将残差最小化,来学习模型。另外,我们知道在CNN中,输出的维度可以与输入维度不一样,比如池化层、或者卷积核的strides设为2,这就会导致输出
与输入
的维度不一样,举个例子,输入维度
,其中10是batch大小,28和28是图片的尺寸,1是图像通道,经过池化或strides=2的卷积,得到
,这个时候就不能直接把
直接相加了,针对这种情况,ResNet作者建议可以用
的卷积层,stride=2,来使得
,从而与
维度匹配起来,再进行相加。
ResNet的基本原理就算说完了,看,是不是很简单,但就是这种很简单的想法却让网络的效果有了质的变化,所以,能带来惊艳效果的,往往都是这些看似平凡的方法。给出文中用上面的block堆砌的一个例子:

图中的虚线表示,这一块,输入和输出的维度不匹配了,需要将输入的维度匹配到输出的维度上,具体做法,就是用上面说到的1x1卷积层来解决。
更多的了解,可以去读一下原文,开头给了网址,有兴趣的可以读一下。
上干货!
ResNet结构是很简单的,所以自己尝试写了一个block的代码resnet.py,如下:
import numpy as np
import tensorflow as tf
slim = tf.contrib.slim
def res_identity(input_tensor, conv_depth, kernel_shape, layer_name):
"""不改变输入张量的维度"""
with tf.variable_scope(layer_name):
relu = tf.nn.relu(slim.conv2d(input_tensor, conv_depth, kernel_shape))
output_tensor = tf.nn.relu(slim.conv2d(relu, conv_depth, kernel_shape) + input_tensor)
return output_tensor
def res_change(input_tensor, conv_depth, kernel_shape, layer_name):
"""改变输入张量的维度"""
input_depth = input_tensor.shape[3]
with tf.variable_scope(layer_name):
relu = tf.nn.relu(slim.conv2d(input_tensor, conv_depth, kernel_shape, stride=2))
input_tensor_reshape = slim.conv2d(input_tensor, conv_depth, [1,1], stride=2) #改变输入的维度,从而保证维度的匹配
output_tensor = tf.nn.relu(slim.conv2d(relu, conv_depth, kernel_shape) + input_tensor_reshape)
return output_tensor
其中,第一个函数,就是没有图像尺寸没有发生变化的时候,输入与输出的维度是匹配的。第二个函数,就是图像尺寸改变了,这里用的是步长为2的卷积操作,没有用池化层。(并且,使用了slim这么个高层封装,就是为了让代码看起来简洁一些,毕竟太长了,就丑了,大家就不想看了)
有了这么一个模块,就可以搭建自己的ResNet网络,然后在MNIST数据集上进行训练和测试。训练代码mnist_train.py如下:
import tensorflow as tf
import sys
from tensorflow.examples.tutorials.mnist import input_data
import win_unicode_console
win_unicode_console.enable()
import mnist_inference
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 10000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = sys.path[0]+"/model/"
MODEL_NAME = "model.ckpt"
def train(mnist):
x = tf.placeholder(tf.float32, [None, 28*28*1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x)
global_step = tf.Variable(0, trainable = False)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
train_step = tf.train.AdadeltaOptimizer(learning_rate).minimize(loss, global_step=global_step)
#初始化Tensorflow持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
#在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:xs, y_:ys})
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g " % (i, loss_value))
saver.save(sess, MODEL_SAVE_PATH+MODEL_NAME, global_step=global_step)
def main(argv=None):
mnist = input_data.read_data_sets("D:/work/mnist/", one_hot = True) #这里换上你自己的数据集路径
train(mnist)
if __name__ == '__main__':
tf.app.run()
前向传播的代码mnist_inference.py:
import tensorflow as tf
from resnet import *
slim = tf.contrib.slim
def inference(input_tensor):
x_image = tf.reshape(input_tensor, [-1,28,28,1])
relu_1 = tf.nn.relu(slim.conv2d(x_image, 32, [3,3]))
pool_1 = slim.max_pool2d(relu_1, [2,2])
net = res_identity(pool_1, 32, [3,3], 'layer_2')
net = res_identity(net, 32, [3,3], 'layer_3')
net = slim.flatten(net, scope='flatten')
net = slim.fully_connected(net, 10, scope='output')
return net
就只加了两层resnet,有兴趣的可以多加点,加他个20层也没问题。
测试代码mnist_eval.py:
import tensorflow as tf
import time
from tensorflow.examples.tutorials.mnist import input_data
import win_unicode_console
win_unicode_console.enable()
import mnist_inference
import mnist_train
def evaluate(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, [None, 28*28*1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
validate_feed = {x: mnist.validation.images, y_:mnist.validation.labels}
y = mnist_inference.inference(x)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print("validation accuracy - %g" % accuracy_score)
else:
print('No checkpoing file found')
return
def main(argv=None):
mnist = input_data.read_data_sets("D:/work/mnist/", one_hot=True) #这里换上自己的数据集路径
evaluate(mnist)
if __name__ == '__main__':
tf.app.run()
测试的结果为0.992,准确度挺好,毕竟MNIST这个数据集实在太简单了,如果想体现出自己算法的优越性,这个数据集是完全不行的。
总的来说,自己动手实现ResNet还是很容易的,毕竟这个方法的思想还是很简单的,但就是这么简单的思想却带来了巨大的改变,实在是佩服作者的脑洞!对笔者的block的代码resnet.py觉得有问题的,可以在评论区交流,欢迎大佬指正,本人菜鸡,还望轻喷
更新2018-4-24:上面是之前给的ResNet模块的代码,前一阵子又改了改,主要的改动就是在卷积层后面都加上了BatchNormalization(批归一化,BN)处理,也更好地解决提督弥散问题,关于BN的知识,随便百度一下就有很多相关博客文章,这里就不赘述了。
先把干货端上来:
import numpy as np
import tensorflow as tf
from tensorlayer.layers import *
slim = tf.contrib.slim
def res_identity(net0, conv_depth, kernel_shape, layer_name, train):
"""不改变输入张量的维度"""
gamma_init = tf.random_normal_initializer(1., 0.02)
with tf.variable_scope(layer_name):
net = Conv2d(net0, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_1')
bn_1 = BatchNormLayer(net, act=tf.nn.relu, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_1')
net = Conv2d(bn_1, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_2')
bn_2 = BatchNormLayer(net, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_2')
net = ElementwiseLayer(layer=[bn_2,net0], combine_fn=tf.add, name=layer_name+'/add')
net.outputs = tf.nn.relu(net.outputs)
return net
def res_change(net0, conv_depth, kernel_shape, layer_name, train):
"""改变输入张量的维度"""
gamma_init = tf.random_normal_initializer(1., 0.02)
with tf.variable_scope(layer_name):
net = Conv2d(net0, conv_depth, kernel_shape, strides=(2,2), b_init=None, name=layer_name+'/conv_1')
bn_1 = BatchNormLayer(net, act=tf.nn.relu, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_1')
net0_reshape = Conv2d(net0, conv_depth, (1,1), strides=(2,2), name=layer_name+'/conv_2')
bn_2 = BatchNormLayer(net0_reshape, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_2')
net = Conv2d(bn_1, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_3')
bn_3 = BatchNormLayer(net, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_3')
net = ElementwiseLayer(layer=[bn_3,bn_2], combine_fn=tf.add, name=layer_name+'/add')
net.outputs = tf.nn.relu(net.outputs)
return net
这里,用上了tensorlayer,tf的一种高层封装,所以,想用这个代码,需要装tensorlayer,非常好装,命令行中输入pip install tensorlayer 就OK了(用tensorlayer写BN非常容易,一行就OK了,要是用tf的话,稍微就麻烦了,代码的可读性就不太好了)。
ResNet'在图像分类问题上,真的是厉害得不得了!不亲自体验一下,都不敢相信!传统的方法搭建8层卷积,不仅速度慢,还很难收敛,或者收敛得非常慢,迭代次数也非常多,但是用ResNet的话,效果提升极其显著,关键是,可能传统卷积层需要10万次才收敛到比较好的值,对于ResNet可能就只需要5000次(我前一阵子就是做了一个这样的对比,由于不方便公开,,大家就自己找个大点的图像做一下分类任务,亲自体验一下就知道了),所以,ResNet在分类问题上,真的是牛( ఠൠఠ )ノ(DenseNet我倒是也写了,不过,感觉要不是任务太复杂了,其实ResNet就很OK了,本人没有做过实验对比,所以就不做过多评价了)。
希望,本文能对大家有所帮助!
最近还在忙于毕设,大概需要加深网络的深度,但是,在这个过程中,发现了一个问题,很多时候,一个8层更加复杂的网络的效果远不及一个3层相对简单的网路的效果(当然,也有可能是因为本人调参水平菜的一笔),这然我挺头疼的,因为,网络简单了,学习出来的模型实在是不好使,想复杂一些,加深网络深度,但无奈不仅仅没有效降低train_error,反而还加重了训练的压力,苦恼了好一阵子,,,后来,想起了ResNet,于是去读了读其论文(https://arxiv.org/pdf/1512.03385v1.pdf),发现,这不正是我所期望的方法嘛!
按照文章的说法,ResNet可以做到在不断加深网络的深度的同时,还能降低train_error,解决了梯度弥散的问题,提高网络的性能,最重要的是,ResNet不仅可以很深,而且,网络的结构还很简单,就是用很单一的小模块堆砌起来的,其单元模块block如下图所示:
如果我们把一个网络的输出定义为 ,残差定义为
,那么,ResNet其实就是在学习这个残差
,通过将残差最小化,来学习模型。另外,我们知道在CNN中,输出的维度可以与输入维度不一样,比如池化层、或者卷积核的strides设为2,这就会导致输出
与输入
的维度不一样,举个例子,输入维度
,其中10是batch大小,28和28是图片的尺寸,1是图像通道,经过池化或strides=2的卷积,得到
,这个时候就不能直接把
直接相加了,针对这种情况,ResNet作者建议可以用
的卷积层,stride=2,来使得
,从而与
维度匹配起来,再进行相加。
ResNet的基本原理就算说完了,看,是不是很简单,但就是这种很简单的想法却让网络的效果有了质的变化,所以,能带来惊艳效果的,往往都是这些看似平凡的方法。给出文中用上面的block堆砌的一个例子:
图中的虚线表示,这一块,输入和输出的维度不匹配了,需要将输入的维度匹配到输出的维度上,具体做法,就是用上面说到的1x1卷积层来解决。
更多的了解,可以去读一下原文,开头给了网址,有兴趣的可以读一下。
上干货!
ResNet结构是很简单的,所以自己尝试写了一个block的代码resnet.py,如下:
import numpy as np
import tensorflow as tf
slim = tf.contrib.slim
def res_identity(input_tensor, conv_depth, kernel_shape, layer_name):
"""不改变输入张量的维度"""
with tf.variable_scope(layer_name):
relu = tf.nn.relu(slim.conv2d(input_tensor, conv_depth, kernel_shape))
output_tensor = tf.nn.relu(slim.conv2d(relu, conv_depth, kernel_shape) + input_tensor)
return output_tensor
def res_change(input_tensor, conv_depth, kernel_shape, layer_name):
"""改变输入张量的维度"""
input_depth = input_tensor.shape[3]
with tf.variable_scope(layer_name):
relu = tf.nn.relu(slim.conv2d(input_tensor, conv_depth, kernel_shape, stride=2))
input_tensor_reshape = slim.conv2d(input_tensor, conv_depth, [1,1], stride=2) #改变输入的维度,从而保证维度的匹配
output_tensor = tf.nn.relu(slim.conv2d(relu, conv_depth, kernel_shape) + input_tensor_reshape)
return output_tensor
其中,第一个函数,就是没有图像尺寸没有发生变化的时候,输入与输出的维度是匹配的。第二个函数,就是图像尺寸改变了,这里用的是步长为2的卷积操作,没有用池化层。(并且,使用了slim这么个高层封装,就是为了让代码看起来简洁一些,毕竟太长了,就丑了,大家就不想看了)
有了这么一个模块,就可以搭建自己的ResNet网络,然后在MNIST数据集上进行训练和测试。训练代码mnist_train.py如下:
import tensorflow as tf
import sys
from tensorflow.examples.tutorials.mnist import input_data
import win_unicode_console
win_unicode_console.enable()
import mnist_inference
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 10000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = sys.path[0]+"/model/"
MODEL_NAME = "model.ckpt"
def train(mnist):
x = tf.placeholder(tf.float32, [None, 28*28*1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x)
global_step = tf.Variable(0, trainable = False)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
train_step = tf.train.AdadeltaOptimizer(learning_rate).minimize(loss, global_step=global_step)
#初始化Tensorflow持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
#在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:xs, y_:ys})
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g " % (i, loss_value))
saver.save(sess, MODEL_SAVE_PATH+MODEL_NAME, global_step=global_step)
def main(argv=None):
mnist = input_data.read_data_sets("D:/work/mnist/", one_hot = True) #这里换上你自己的数据集路径
train(mnist)
if __name__ == '__main__':
tf.app.run()
前向传播的代码mnist_inference.py:
import tensorflow as tf
from resnet import *
slim = tf.contrib.slim
def inference(input_tensor):
x_image = tf.reshape(input_tensor, [-1,28,28,1])
relu_1 = tf.nn.relu(slim.conv2d(x_image, 32, [3,3]))
pool_1 = slim.max_pool2d(relu_1, [2,2])
net = res_identity(pool_1, 32, [3,3], 'layer_2')
net = res_identity(net, 32, [3,3], 'layer_3')
net = slim.flatten(net, scope='flatten')
net = slim.fully_connected(net, 10, scope='output')
return net
就只加了两层resnet,有兴趣的可以多加点,加他个20层也没问题。
测试代码mnist_eval.py:
import tensorflow as tf
import time
from tensorflow.examples.tutorials.mnist import input_data
import win_unicode_console
win_unicode_console.enable()
import mnist_inference
import mnist_train
def evaluate(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32, [None, 28*28*1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
validate_feed = {x: mnist.validation.images, y_:mnist.validation.labels}
y = mnist_inference.inference(x)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print("validation accuracy - %g" % accuracy_score)
else:
print('No checkpoing file found')
return
def main(argv=None):
mnist = input_data.read_data_sets("D:/work/mnist/", one_hot=True) #这里换上自己的数据集路径
evaluate(mnist)
if __name__ == '__main__':
tf.app.run()
测试的结果为0.992,准确度挺好,毕竟MNIST这个数据集实在太简单了,如果想体现出自己算法的优越性,这个数据集是完全不行的。
总的来说,自己动手实现ResNet还是很容易的,毕竟这个方法的思想还是很简单的,但就是这么简单的思想却带来了巨大的改变,实在是佩服作者的脑洞!对笔者的block的代码resnet.py觉得有问题的,可以在评论区交流,欢迎大佬指正,本人菜鸡,还望轻喷
更新2018-4-24:上面是之前给的ResNet模块的代码,前一阵子又改了改,主要的改动就是在卷积层后面都加上了BatchNormalization(批归一化,BN)处理,也更好地解决提督弥散问题,关于BN的知识,随便百度一下就有很多相关博客文章,这里就不赘述了。
先把干货端上来:
import numpy as np
import tensorflow as tf
from tensorlayer.layers import *
slim = tf.contrib.slim
def res_identity(net0, conv_depth, kernel_shape, layer_name, train):
"""不改变输入张量的维度"""
gamma_init = tf.random_normal_initializer(1., 0.02)
with tf.variable_scope(layer_name):
net = Conv2d(net0, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_1')
bn_1 = BatchNormLayer(net, act=tf.nn.relu, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_1')
net = Conv2d(bn_1, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_2')
bn_2 = BatchNormLayer(net, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_2')
net = ElementwiseLayer(layer=[bn_2,net0], combine_fn=tf.add, name=layer_name+'/add')
net.outputs = tf.nn.relu(net.outputs)
return net
def res_change(net0, conv_depth, kernel_shape, layer_name, train):
"""改变输入张量的维度"""
gamma_init = tf.random_normal_initializer(1., 0.02)
with tf.variable_scope(layer_name):
net = Conv2d(net0, conv_depth, kernel_shape, strides=(2,2), b_init=None, name=layer_name+'/conv_1')
bn_1 = BatchNormLayer(net, act=tf.nn.relu, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_1')
net0_reshape = Conv2d(net0, conv_depth, (1,1), strides=(2,2), name=layer_name+'/conv_2')
bn_2 = BatchNormLayer(net0_reshape, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_2')
net = Conv2d(bn_1, conv_depth, kernel_shape, b_init=None, name=layer_name+'/conv_3')
bn_3 = BatchNormLayer(net, act=tf.identity, is_train= train, gamma_init=gamma_init, name=layer_name+'/bn_3')
net = ElementwiseLayer(layer=[bn_3,bn_2], combine_fn=tf.add, name=layer_name+'/add')
net.outputs = tf.nn.relu(net.outputs)
return net
这里,用上了tensorlayer,tf的一种高层封装,所以,想用这个代码,需要装tensorlayer,非常好装,命令行中输入pip install tensorlayer 就OK了(用tensorlayer写BN非常容易,一行就OK了,要是用tf的话,稍微就麻烦了,代码的可读性就不太好了)。
ResNet'在图像分类问题上,真的是厉害得不得了!不亲自体验一下,都不敢相信!传统的方法搭建8层卷积,不仅速度慢,还很难收敛,或者收敛得非常慢,迭代次数也非常多,但是用ResNet的话,效果提升极其显著,关键是,可能传统卷积层需要10万次才收敛到比较好的值,对于ResNet可能就只需要5000次(我前一阵子就是做了一个这样的对比,由于不方便公开,,大家就自己找个大点的图像做一下分类任务,亲自体验一下就知道了),所以,ResNet在分类问题上,真的是牛( ఠൠఠ )ノ(DenseNet我倒是也写了,不过,感觉要不是任务太复杂了,其实ResNet就很OK了,本人没有做过实验对比,所以就不做过多评价了)。
希望,本文能对大家有所帮助!















 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









