







Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning(CVPR2017)
文章认为,非视觉词如the,of 等更多的依赖语言信息而不是视觉信息,他们的梯度反而会影响视觉信息的有效性。因此论文引进了一个参数 β \beta β,来控制attention中视觉信息和历史信息(语言信息)的比重。设计了 visual sentinel来表示已经生成的历史信息(语言信息)。
论文的贡献有:
- 改进了传统的soft attention模型,提出了spatial attention模型。
- 提出了带有视觉哨兵的自适应的adaptive attention模型.
传统的soft attention模型:
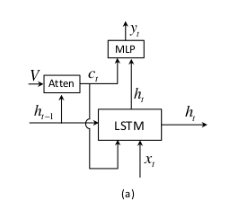
改进的spatial attention模型:
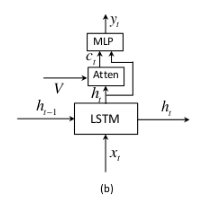
与传统的soft attention不同的是:使用 h t h_{t} ht,而不是 h t − 1 h_{t-1} ht−1输入attention。
作者认为 C t C_{t} Ct可以看作是 h t h_{t} ht的残差连接,可以在预测下一个词时,降低不确定性或提供情报。
adaptive attention模型:
作者采用在spatial attention的基础上扩展LSTM的方式,得到adaptive attention模型。
具体的扩展方式是在LSTM的基础上加了两个公式:
g t = σ ( w x x t + w h h t − 1 ) g_{t}=\sigma(w_{x}x_{t}+w_{h}h_{t-1}) gt=σ(wxxt+whht−1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1565
1565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









