







CVPR 2017
基于注意力的编码器-解码器架构的图像理解方法大多强制注意力机制对生成的每个单词都生效,但预测“the”、“a”这类非视觉词汇不需要太多的信息。《Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning》文章中提出了一个带有“视觉哨兵”概念的新兴型自使用注意力模型。在每个时间步骤,模型决定关注图像本身还是视觉哨兵。
给定图片和对应的解释,编码器-解码器模型直接最大化一下目标:
![]()
其中,θ是模型的参数,![]() 是图片t
是图片t![]() 是对应描述。根据链式法则:
是对应描述。根据链式法则:
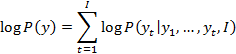
为了方便起见,减去对模型参数的依赖。
在编码器解码器架构中,使用LSTM建模每个条件概率:
![]()
f是非线性函数,输出![]() 的概率。ct是t时刻从图像
的概率。ct是t时刻从图像![]() 提取的视觉上下文向量。
提取的视觉上下文向量。
![]() 是是LSTM在t时刻的隐藏状态,xt是输入向量,mt-1是在t-1时刻的内存单元向量。
是是LSTM在t时刻的隐藏状态,xt是输入向量,mt-1是在t-1时刻的内存单元向量。
解决模型注意图像区域的问题:提出一个空间注意力模型来计算![]() :
:
![]()
其中![]() 是注意力函数,
是注意力函数,![]() 是空间图像特征,每个d维向量对应于图像的一个区域。给定
是空间图像特征,每个d维向量对应于图像的一个区域。给定![]() ,通过单层神经网络接上Softmax函数来生成图像在k个区域上的注意力分布:
,通过单层神经网络接上Softmax函数来生成图像在k个区域上的注意力分布:
![]()
![]()
其中,1![]() 是所有元素都为1的向量。
是所有元素都为1的向量。![]() 都是需要学习的参数。
都是需要学习的参数。![]() 是在V中特征上的注意力权重,则
是在V中特征上的注意力权重,则
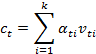
解决模型何时注意图像的问题:提出一个新的概念“视觉哨兵”——解码器一直内容的潜在表示。在解码器的内存单元中提取一个新的成分,使模型在选择不关注图像是可以回滚。用“哨兵门”决定关注图像还是视觉哨兵。扩展LSTM来获得视觉哨兵向量![]() :
:
![]()
![]()
其中,![]() 是是需要学习的权重参数,
是是需要学习的权重参数,![]() 是LSTM在t时刻的输入,
是LSTM在t时刻的输入,![]() 是应用于内存单元
是应用于内存单元![]() 的门。
的门。
定义一个新的自适应上下文向量![]() :
:
![]()
其中,![]() 是t时刻的新哨兵门,产生一个[0,1]的标量。为了计算
是t时刻的新哨兵门,产生一个[0,1]的标量。为了计算![]() ,修改之前的空间注意力成分:
,修改之前的空间注意力成分:
![]()
其中,![]() 、Wg是权重参数,
、Wg是权重参数,![]() 与之前一样,
与之前一样,![]() 就表示空间图像特征和视觉哨兵上的注意力分布,把
就表示空间图像特征和视觉哨兵上的注意力分布,把![]() 的最后一列作为门值:
的最后一列作为门值:![]() 。
。
最后,t时刻可能的词汇表概率分布为:
![]()















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









