







AR-Net:用于复制-移动伪造检测的自适应注意和残差改进网络
摘要
提出了一种基于自适应注意和残差细化网络(AR-Net)的端到端神经网络。通过自适应注意机制融合位置和通道注意特征,充分捕捉上下文信息,丰富特征表示。其次,采用深度匹配计算特征图之间的自相关,并将空间金字塔池化融合比例相关图生成粗掩模;最后通过保留物体边界结构的残差细化模块对粗掩模进行优化。
在CASIAII、COVERAGE和CoMoFoD数据集上进行的大量实验表明,AR-Net比最先进的算法有更好的性能,可以在像素级定位被篡改和相应的真实区域。此外,AR-Net对后期处理操作具有很高的鲁棒性,如噪声、模糊和JPEG再压缩。
引言
方法的提出
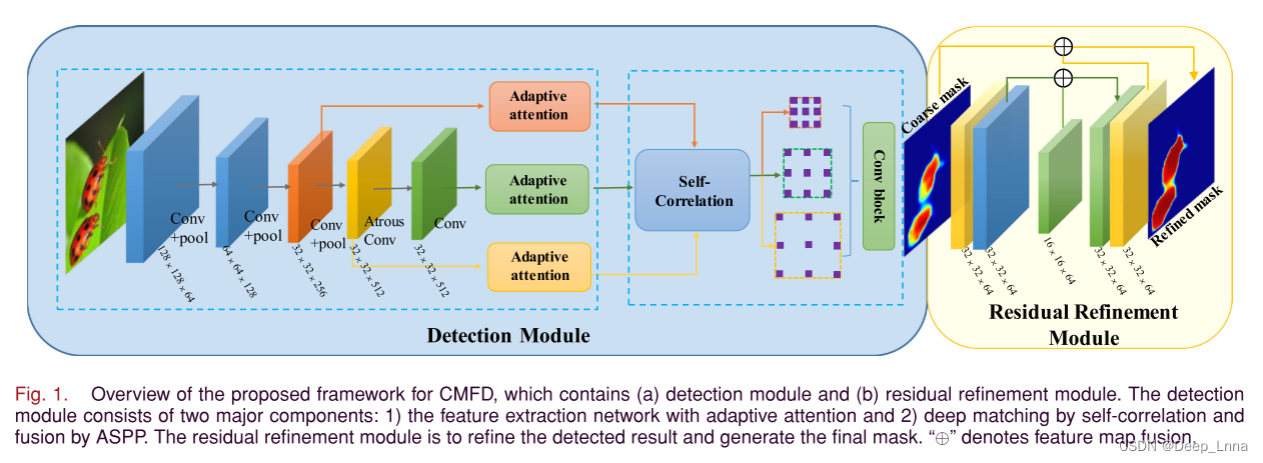
如图1所示。AR-Net主要包括获取粗篡改掩模的检测模块和优化预测掩模边界的残差细化模块两个模块,能有效定位篡改区域,在三个标准数据集上均有较好的性能结果。检测模块主要由两部分组成:1)自适应注意特征提取网络;2)自相关深度匹配和ASPP融合。残差细化模块是对检测结果进行细化,生成最终的掩码。“⊕”表示特征图融合。
主要贡献
- 我们提出了一种新的自适应注意机制来提取被篡改的特征,这些特征可以添加到任何伪造检测框架中,以提高篡改定位的准确性。
- 与现有的大多数伪造检测方法预测掩码较粗不同,采用残差求精模块优化预测边界,得到完整的篡改对象。
- 结合上述两个模块,提出了一种新的CMFDNetwork。 大量的实验证明,AR-NET能够有效地检测出篡改区域和相应的真实区域,并且对常见的后处理操作具有很强的鲁棒性。
网络架构概述
CMFD的主要目的是区分真实区域和篡改区域。我们提出的AR-Net在像素级上定位了同一幅图像中被篡改的区域和对应的真实区域。如图1所示,在AR-Net中主要有两个模块:检测模块和残差细化模块。检测模块主要由两部分组成:具有自适应注意的特征提取网络、自相关的深度匹配和atrous空间金字塔池融合(ASPP)。
自适应注意模块
池化层可以减少网络参数的数量,但不可避免地降低了空间分辨率。为了丰富深层特征的空间信息,生成高分辨率的特征图,我们采用了在第四层卷积之后展开速率为“2”的Atrous卷积。
由于CNN只提取局部特征,我们利用自适应注意力模块提取全局特征,如图2所示,在位置和通道维度上采用自适应注意机制来捕捉全局像素的长程相关性,突出篡改区域和真实区域的差异。
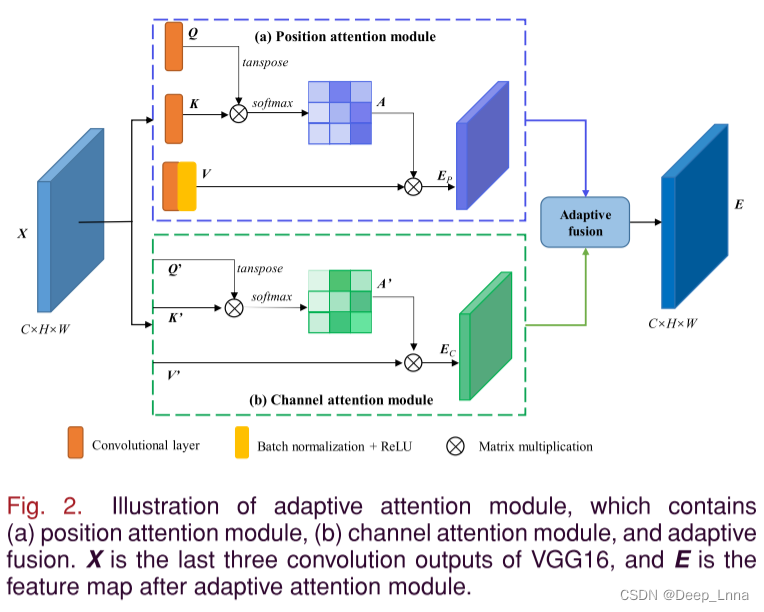
通过在位置注意模块上应用自注意机制,可以将更广泛的上下文信息编码为局部特征,丰富了卷积特征的表示。 在位置注意模块中,特征映射X的位置注意矩阵A被计算为
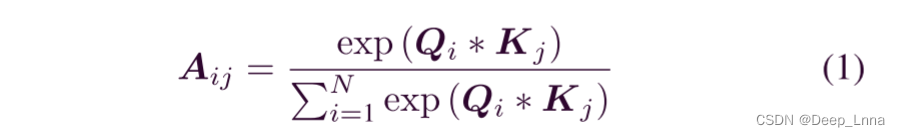
其中Aij表示第i个像素对第j个像素的影响,Q和K是卷积后的特征图。如图2(a)所示。位置注意特征图EP可以计算为
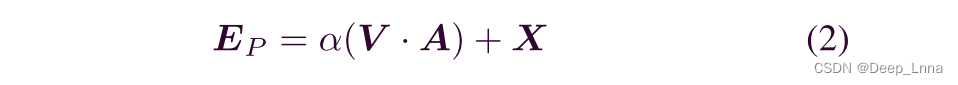
其中α为初值为零的可学习参数,V为卷积、批归一化、ReLU后的特征映射,如图2(a)所示。与位置注意相似,通道注意特征图EC计算如图2(b)所示。
若直接连接位置和通道注意力的特征图,不考虑它们之间的权重将导致信息丢失,不利于定位被篡改的区域。因此,我们以自适应的方式融合 EP 和 EC 以获得特征图,这将丰富上下文信息并在不同位置的特征之间建立关系。自适应注意力模块可以充分捕获上下文信息并丰富卷积特征的表示,可以计算为:
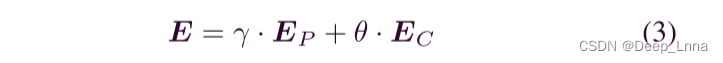
其中和是两个自适应参数,初始化为标准高斯分布,在训练过程中不断学习。
深度匹配和ASPP模块
对于CMFD,深度特征的相关性计算是一个核心问题。通过自适应注意模块生成伪造特征。由于复制-移动检测的特殊性,我们还需要找到相应的正确的区域。由于被篡改区域是从相应的真实区域复制而来的,所以它们之间的相似度要比被篡改区域和其他真实区域高得多。因此,我们使用深度匹配来定位相似的区域。
E3、E4 和 E5 是我们可以找到匹配补丁的特征图。具体地,第m个补丁Emk的特征图与第n个
补丁Enk的特征图之间的相似度得分sk(m,n)计算为:
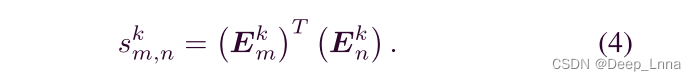
为了抑制不相关的信息,我们使用排序池按降序选择第一个T分数对应的索引作为indk(T):
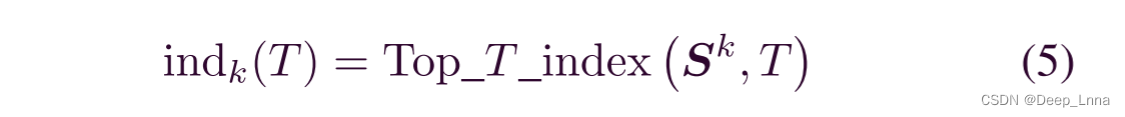
其中Top_T_index(·)为选取top-T值的索引的函数,Sk为特征图Ek的相似度得分。
在我们的网络中,由于atrous卷积,特征地图E3、E4和E5具有相同的尺寸,但不同数量的通道。深度匹配后,得到匹配特征映射Efinal为
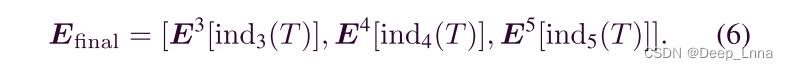
在复制-移动伪造中,被篡改的区域通常是缩放的,因此充分利用相关图提供的多尺度信息是非常重要的。我们使用ASPP来预测粗糙掩模,这有利于检测不同尺寸的篡改区域。
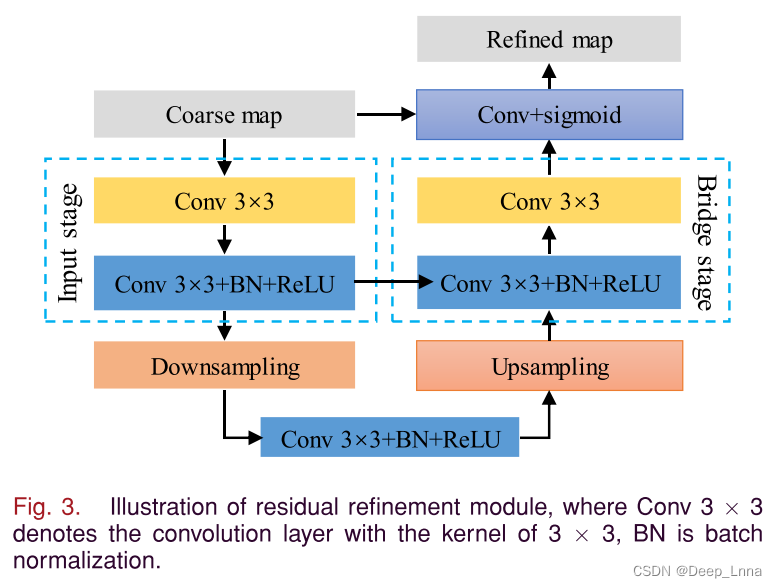
残差细化模块
现有的基于深度学习的伪造检测方法只检测被篡改的区域,没有对生成的掩码进行细化,这在一定程度上影响了检测。这里,我们把检测模块生成的掩模看作是一个粗糙掩模。如图1所示,粗掩模作为残差细化模块的输入,与U-net类似,生成一个细化的掩模。
如图3所示,残差细化模块主要由输入层、下采样层、桥接层、上采样层和输出层组成。输入级有64个3 × 3的滤波器,然后是批量归一化和ReLU函数。桥接阶段还有一个卷积层,有大小为3 × 3的64个滤波器,然后是批量归一化和ReLU函数。下采样采用平均池化,上采样采用双线性插值。同时,我们引入了一种跃层连接,在上采样后,特征映射被添加到相应输入级的特征映射中。最后,经过一个sigmoid激活函数的卷积层,得到最终的精化掩模。
训练损失
该算法可分为检测模块和残差细化模块两部分。采用不同的损失来训练这两个模块。
检测模块损失
对检测模块进行训练时,利用空间交叉熵损耗函数最小化网络中最优参数集。由于伪造检测本质上是一个二进制分类问题,因此二进制交叉熵损失Lbce计算为
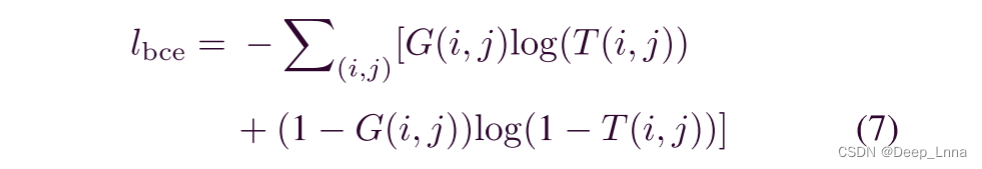
其中G(i, j)∈{0,1}表示像素(i, j)的标签,T(i, j)是像素(i, j)被篡改的预测概率值。
残差细化模块损失
BCE损失仅孤立地考虑每个像素,没有考虑每个像素与相邻像素之间的关系。 BCE损失在篡改区域和真实区域的边界上平等对待像素,不能突出篡改区域和真实区域之间的差异。 为了保留更多的结构信息并突出篡改区域的边界,我们使用混合损失函数Lref定义为
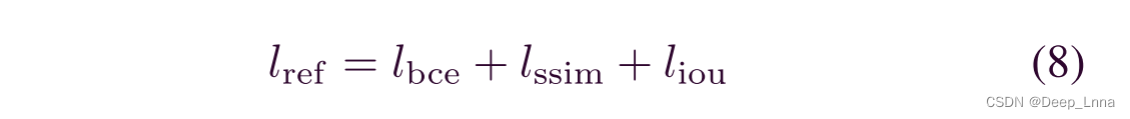
其中Lbce、Lssim和Liou分别代表BCE损失、结构相似(SSIM)损失和交并比(iou)损失。 BCE损失主要评估像素级的分割能力,帮助模型在所有像素上收敛。
SSIM损失可以捕获结构信息,并考虑到每个像素的局部邻域,这是patch级别中的度量。 通过SSIM损失,残差细化网络在训练时可以更加关注篡改区域的边界,并赋予边界更多的权重。 SSIM损失可以表示为
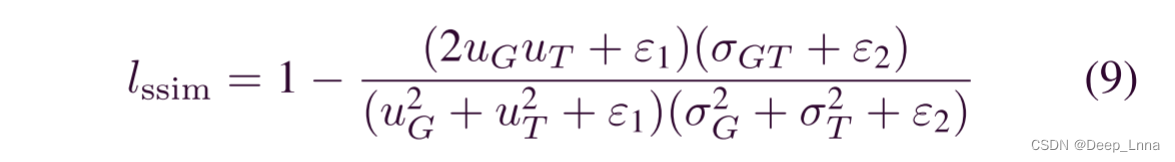
其中uG,uT表示G和T的均值,σG和σT表示G和T的标准差,σGT是协方差矩阵。 ε1=0.0001和ε2=0.0009保持不变,以避免分母为零。
IOU损失常被用来评估目标检测和分割,最近又被用于训练阶段。 Liou的计算过程表示为
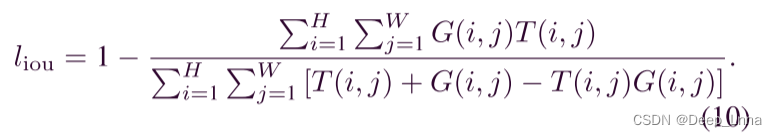
在训练残差细化模块时,我们按照(8)将这三种损失结合起来,其中BCE损失是为了使所有像素具有平滑的梯度,SSIM损失是为了保留图像的结构信息,IOU损失是为了使网络更加关注篡改区域。
实验
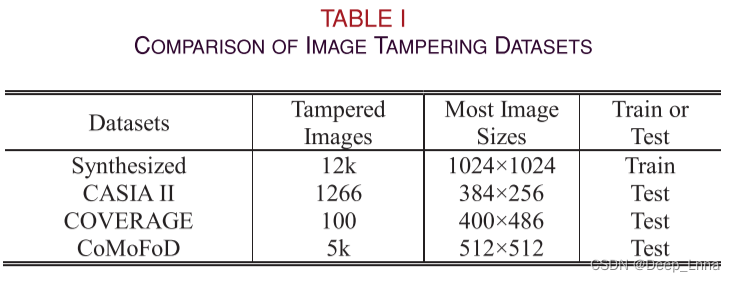
数据集
训练设置分析
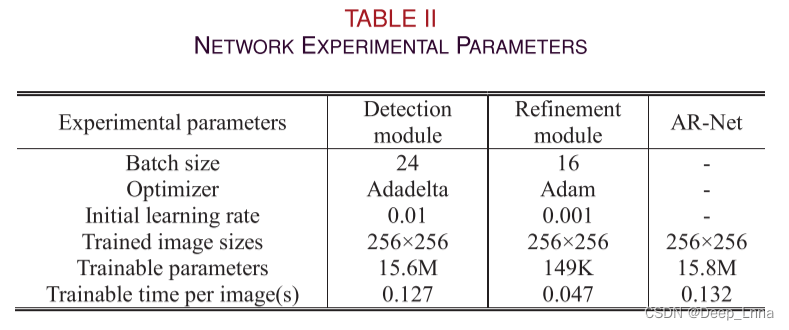
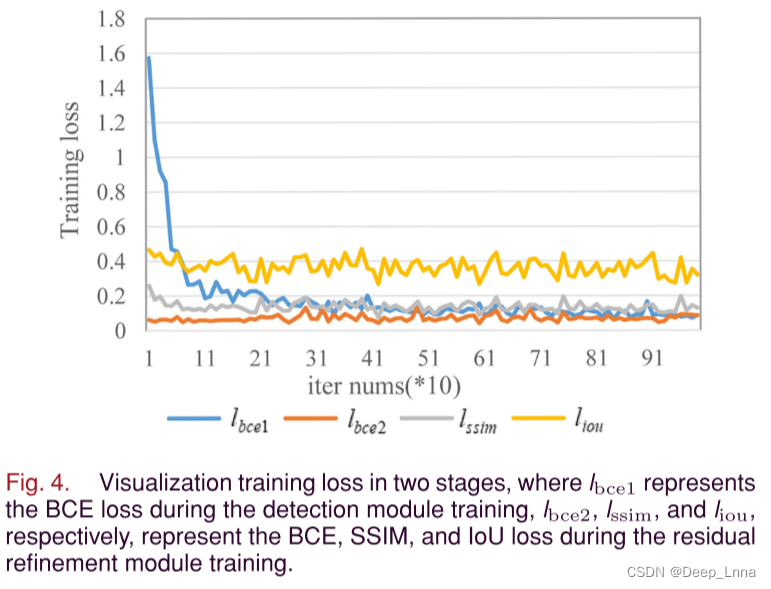
图4为两个阶段的可视化训练损失,其中Lbce1表示检测模块训练期间的BCE损失,Lbce2、Lssim和Liou分别表示残差细化模块训练期间的BCE、SSIM和IOU损失。
评价指标
Precision、Recall、F1、AUC
消融实验
自适应注意模块和残差细化模块
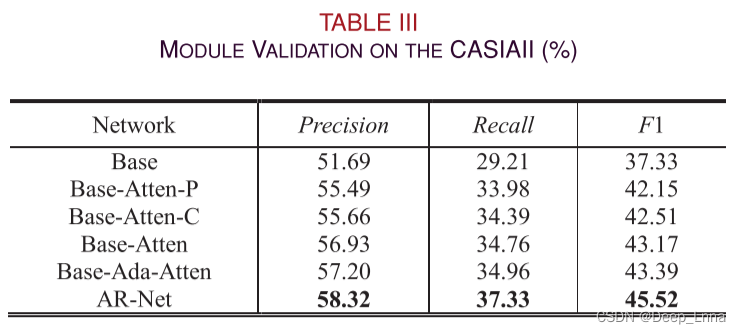
1)Base:没有自适应注意模块和残差细化模块的框架。
2)Base-Atten-P:只有位置注意模块的框架。
3)Base-Atten-C:只有通道注意力模块的框架。
4)Base-Atten:简单的将position attention和channel attention整合在一起的框架,没有自适应融合。
5) Base-Ada-Atten:带有自适应注意模块但没有残差细化模块的框架。
6) AR-Net:具有注意力模块和残差细化模块的框架。
鲁棒性分析
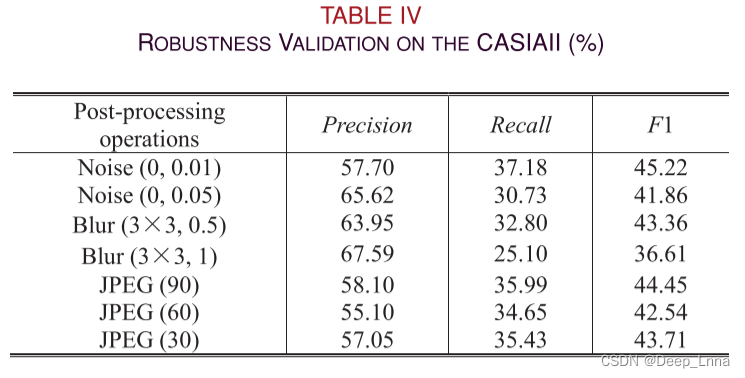
由于加入噪声后部分篡改区域被隐藏,召回率下降,但F1保持稳定。 高斯模糊与高斯噪声相似,但随着图像模糊度的增加,F1和查全率下降更明显。 因此,AR-NET对一定范围内的模糊提出了更好的鲁棒性。 对于JPEG重压缩,AR-NET保持了很强的鲁棒性。
与SoTA比较
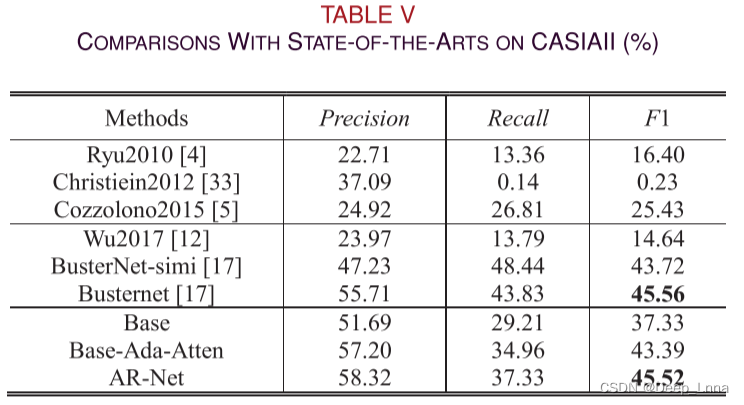
在CASIAII上比较
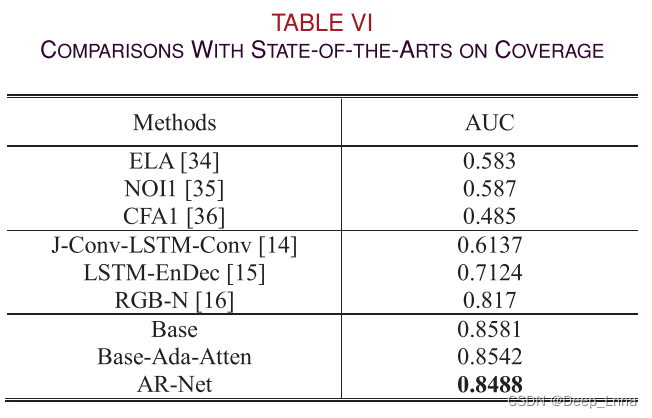
在Coverage上比较

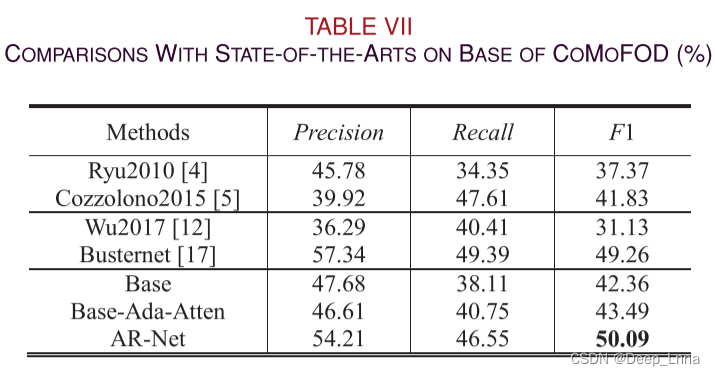
在CoMoFoD上比较
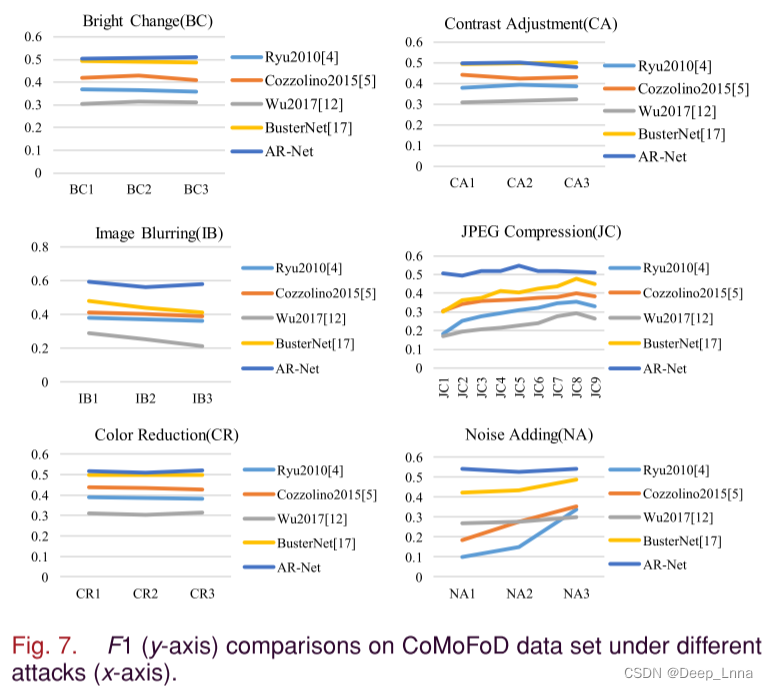
为了评估不同攻击下篡改图像的性能,我们将攻击分为六组,分别是亮度变化(BC)、对比度调整(CA)、图像模糊(IB)、JPEG压缩(JC)、颜色减少(CR)和噪声添加(NA)。目前最先进的方法与AR-Net的F1比较如图7所示,除CA3[(下界,上界)=(0.01,0.8)]外,AR-Net稳定,性能最好。

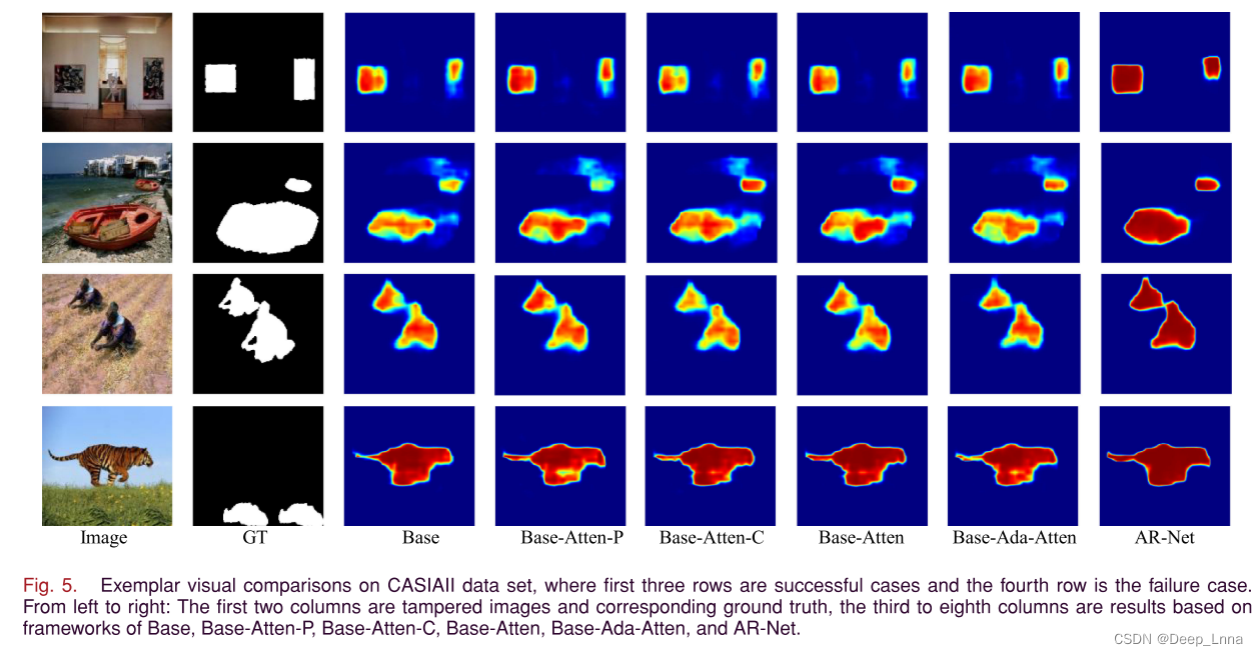
从图8的前三行我们可以看出,AR-Net有效的缓解了边界模糊,准确的预测了每个边界像素,提高了网络的整体性能。尽管如此,还是有一些失败的案例,如第四行图所示。这说明AR-Net在进行深度匹配时可以定位相似的区域,使得相似但真实的区域被标记为篡改。因此,区分相似但真实的区域和复制-移动伪造的研究仍需进一步的探索。
总结
本文提出了一种基于自适应注意机制和残差细化的端到端CMFD网络。AR-Net利用自适应注意机制融合位置特征和通道尺寸特征,使网络能够充分利用不同尺寸的篡改特征。此外,AR-Net对预测掩模进行细化,并在像素级定位出被篡改区域和对应的真实区域。实验证明了自适应注意模块的有效性,并对CASIAII, COVERAGE和CoMoFoD数据集进行了残差细化。与其他先进的CMFD方法相比,AR-Net能够准确定位被篡改区域,并且对噪声、模糊和jpeg压缩等后处理具有鲁棒性。然而,AR-Net是单流,没有利用多种模式的信息。在未来的工作中,我们会尝试整合不同模式的信息。















 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









