







 在训练数据拆分上评估数据增强,以增加高质量训练样本的数量。Intuition通常希望通过数据扩充来增加训练数据的规模和多样性。它涉及使用现有样本生成合成但真实的示例。拆分数据集。想首先拆分数据集,因为如果允许将生成的样本放置在不同的数据拆分中,许多增强技术会导致某种形式的数据泄漏。例如,一些增强涉及为句子中的某些关键标记生成同义词。如果允许来自相同来源句子的生成句子进入不同的拆分,可能会在不同的拆分中泄漏具有几乎相同的嵌入表示的样本。增加训练拆分。只想在训练集上应用数据增强,因为验证和测试拆
在训练数据拆分上评估数据增强,以增加高质量训练样本的数量。Intuition通常希望通过数据扩充来增加训练数据的规模和多样性。它涉及使用现有样本生成合成但真实的示例。拆分数据集。想首先拆分数据集,因为如果允许将生成的样本放置在不同的数据拆分中,许多增强技术会导致某种形式的数据泄漏。例如,一些增强涉及为句子中的某些关键标记生成同义词。如果允许来自相同来源句子的生成句子进入不同的拆分,可能会在不同的拆分中泄漏具有几乎相同的嵌入表示的样本。增加训练拆分。只想在训练集上应用数据增强,因为验证和测试拆
在训练数据拆分上评估数据增强,以增加高质量训练样本的数量。
Intuition
通常希望通过数据扩充来增加训练数据的规模和多样性。它涉及使用现有样本生成合成但真实的示例。
-
拆分数据集。想首先拆分数据集,因为如果允许将生成的样本放置在不同的数据拆分中,许多增强技术会导致某种形式的数据泄漏。
例如,一些增强涉及为句子中的某些关键标记生成同义词。如果允许来自相同来源句子的生成句子进入不同的拆分,可能会在不同的拆分中泄漏具有几乎相同的嵌入表示的样本。
-
增加训练拆分。只想在训练集上应用数据增强,因为验证和测试拆分应该用于提供对实际数据点的准确估计。
-
检查和验证。如果扩充数据样本不是模型在生产中可能遇到的输入,那么仅仅为了增加训练样本大小而扩充是没有用的。
数据扩充的确切方法在很大程度上取决于数据类型和应用程序。以下是可以增强不同数据模式的几种方法:
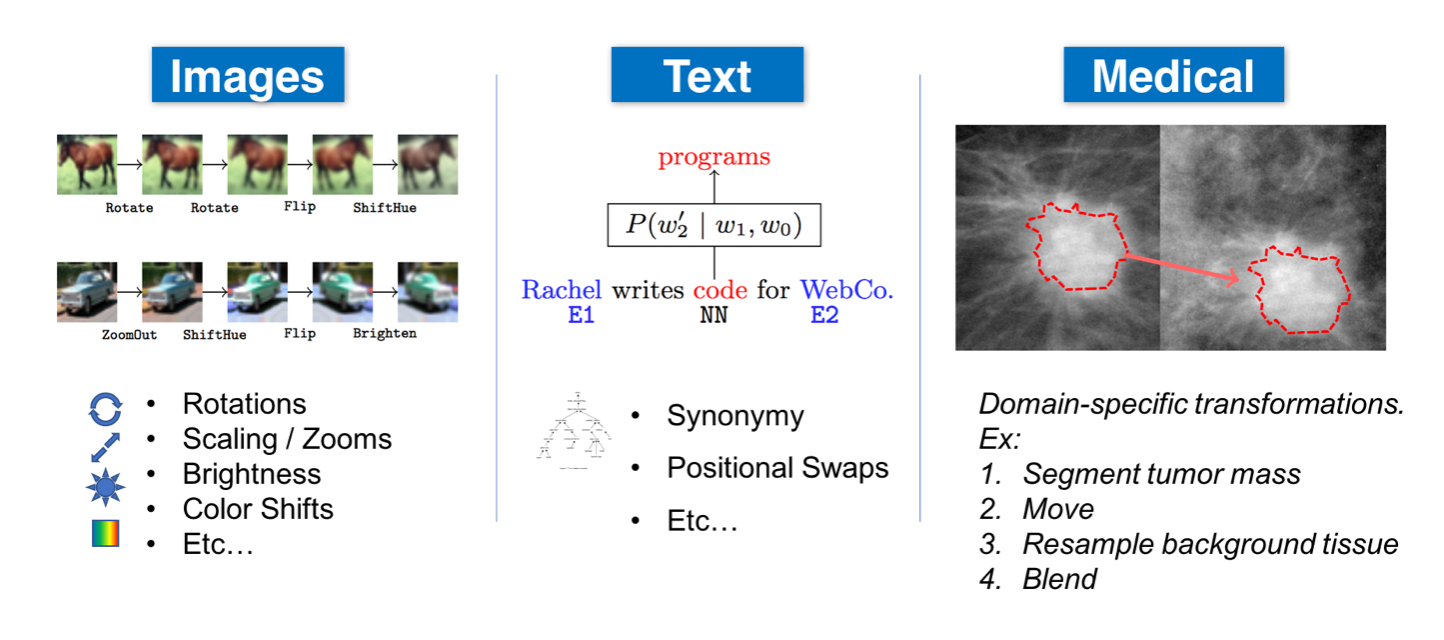
-
一般:归一化、平滑、随机噪声、合成过采样( SMOTE)等。 -
自然语言处理(NLP):替换(同义词、tfidf、嵌入、屏蔽模型)、随机噪声、拼写错误等。 -
计算机视觉(CV):裁剪、翻转、旋转、填充、饱和、增加亮度等。
warning
虽然某些数据模式(例如图像)的转换很容易检查和验证,但其他模式可能会引入无提示错误。例如,改变文本中标记的顺序可以显着改变含义(“这真的很酷”→“这真的很酷吗”)。因此,重要的是要衡量增强策略将引入的噪声,并对发生的转换进行精细控制。
library
根据特征类型和任务,有许多数据增强库允许扩展训练数据。
自然语言处理 (NLP)
-
NLPAug:NLP 的数据增强。 -
TextAttack:用于 NLP 中的对抗性攻击、数据增强和模型训练的框架。 -
TextAugment:文本增强库。
计算机视觉(简历)
-
Imgaug:用于机器学习实验的图像增强。 -
Albumentations:快速图像增强库。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









