









语义分割学习
1 简介
实例分割、语义分割区别
分割网络一般结构包括backbone、encoder(类似于检测的neck?)、decoder(相当于检测的head?)三个结构
分割中的loss
Dice loss
Dice Loss 最先是在VNet 这篇文章中被提出,后来被广泛的应用在了医学影像分割之中。
首先将∣ X ∩ Y ∣近似为预测图与 GT 分割图之间的点乘,并将点乘的元素结果相加,交集可以简单理解为相似性,相似性越高越好。

smooth的好处
(1)避免当|X|和|Y|都为0时,分子被0除的问题
(2)减少过拟合
详细介绍,很好
2 SegNeXt
2023年的效果最优,SegNeXt比其他SOTA方案平均提高2.0%mIoU,且计算量相当或更少(如使用了大量的depth wise卷积)。backbone采用了convnext。
encoder:一般是各种特征融合,金字塔、attention等,个人理解算是对backbone特征的进一步升级
decoder:常规语义分割模型的骨干往往在ImageNet上预训练得到,为捕获高级语义信息,通常需要一个Decoder模块,decoder连接encoder和loss,起到解码、特征转换的作用
分割中的attention
分割中常见的attention主要分为两类:channel attention和spatial attention。区域注意力使模型更加关注重点的区域,而通道注意力使模型更加关注重要的目标或类型。
本文对卷积注意力设计进行了重思考并提出了一种简单而有效的编码器-解码器架构SegNeXt。不同于已有Transformer方案,SegNeXt对Transformer-Convolution Encoder-Decoder架构进行了逆转,即对编码器模块采用传统卷积模块设计但引入了多尺度卷积注意力,对解码器模块采用了Hamberger(自注意力的一种替代方案)进一步提取全局上下文信息。因此,SegNeXt能够从局部到全局提取多尺度上下文信息,能在空域与通道维度达成姿势星星,能从底层到高层进行信息聚合。上图给出了Cityscape与ADE20K数据集上所提方案与标杆方案的计算量与性能对比
编码器MSCAN
续已有方案,本文在Encoder部分同样采用了金字塔架构,每个构成模块采用了类似ViT的结构,但不同之处在于:本文并未使用自注意力,而是设计一种多尺度卷积注意力模块MSCA(见下图,其实就是一种多尺度版VAN,MSCA是encoder的关键创新点)。

如上图所示,MSCA由三部分构成,MSCA图中的+和*都是元素级的运算
- depth-wise 卷积:用于聚合局部信息,两个维度上的,17级联71,两个维度都关注,比如横杆、竖杆
- 多分支depth-wise卷积:用于捕获多尺度上下文信息
- 1×1卷积:用于在通道维度进行相关性建模。1*1卷积本质上也可以当成通道注意力,这里虽然是通道注意力,但是其实是多尺度特征相加后的通道注意力,所以也可以说是多尺度卷积注意力
MSCA可以描述为如下公式:
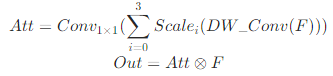
MSCA代码如下,看代码一目了然
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u
解码器Hamberger
待补充
ocrNet
该论文的主要思想也就是像素的类别标签是由它所在的目标的类别标签决定的。主要思路是利用目标区域表示来增强其像素的表示。与之前的考虑上下文关系的方法不同的是,之前的方法考虑的是上下文像素之间的关系,没有显示利用目标区域的特征。
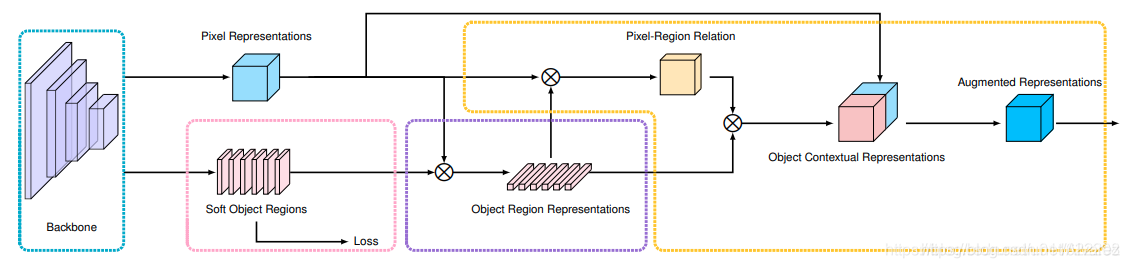
上图中的pixel-region Relation是概率值,即softmax(QK)/根号Dk,pixel-region Relation再乘以下面的object region representtions(即attention的V),就构成了一个attention,这里是attention应该不是self attention

具体步骤如下参考链接:
-
根据骨干网络中间层Pixel Representations预测Soft Object Regions (K个Soft Masks, 每个Mask对应于一个语义类别);
-
根据Soft Object Regions对网络深层的Pixel Representations加权求和得到Object Region Representations (每一类都对应于一个Object Region Representation);
-
Pixel Representations作为Query, Object Region Representations作为Key-Value, 送入Cross-Attention,输出作为Object Contextual Representations; 然后把Object Contextual Representations和输入的Pixel Representation拼接在一起经过融合之后得到Augmented Representations,最后加一个分类器用于预测最后的语义分割结果;
step1 提取类别区域特征
目标:根据 像素语义信息 和 像素特征 得到每个 类别区域特征。其中像素语义信息是常规的语义分割结果,像素特征就是backbone提取得到的特征图,具体做法如下:
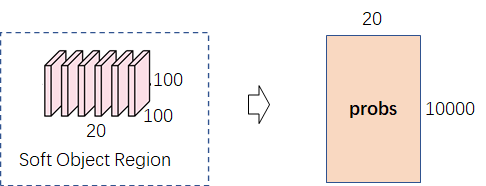
(1)像素语义(20×100×100)展开成二维(20×10000),其每一行表示每个像素点(10000个像素点)属于某类物体(总共20个类)的概率。
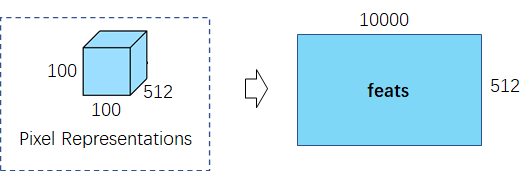
(2)像素特征(512×100×100)展开成二维(512×10000),其每一列表示每个像素点(10000个像素点)在某一维特征(512维)。
(3)像素语义的每行乘以像素特征的每列再相加,得到类别区域特征,其每一行表示某个类(20类)的512维特征。
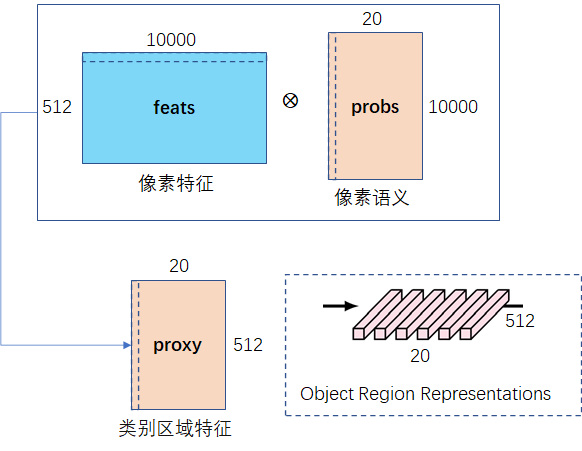
def get_proxy(feats,probs):
batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
# 1, 20, 100, 100
probs = probs.view(batch_size, c, -1)
# (1, 20, 10000)
feats = feats.view(batch_size, feats.size(1), -1)
# (1, 512, 10000)
feats = feats.permute(0, 2, 1) # batch x hw x c
# (1, 10000, 512)
probs = F.softmax(self.scale * probs, dim=2)# batch x k x hw
# (1, 20, 10000)
proxy = torch.matmul(probs, feats).permute(0, 2, 1).unsqueeze(3)# batch x k x c
# (1, 512, 20, 1)
return proxy
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
probs = torch.randn((1, 20, 100, 100))
proxy=get_proxy(feats,probs)
Step2:像素区域相似度
对像素特征 feats 和 step1 得到类别区域特征 proxy ,使用 self-attention 得到像素与区域的相似度,即依赖关系。
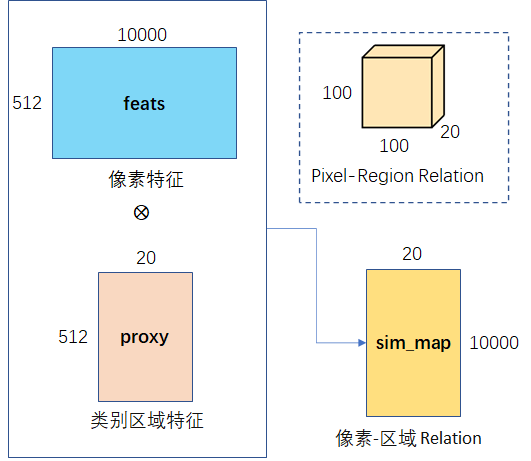

f_object和f_down的代码如下:
f_pixel = nn.Sequential(
nn.Conv2d(in_ch=in_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
nn.Conv2d(in_ch=key_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
)
f_object = nn.Sequential(
nn.Conv2d(in_ch=in_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
nn.Conv2d(in_ch=key_ch, out_ch=key_ch,kernel_size=1, stride=1, padding=0),
ModuleHelper.BNReLU(key_ch, bn_type=bn_type),
)

计算代码如下:
def get_sim_map(feats, proxy):
x=feats
batch_size, h, w = x.size(0), x.size(2), x.size(3)
# 1, 100, 100
## qk
query = f_pixel(x).view(batch_size, self.key_channels, -1)
# (1, 256, 10000)
query = query.permute(0, 2, 1)
# (1, 256, 10000)
key = f_object(proxy).view(batch_size, self.key_channels, -1)
# (1, 256, 20)
value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
# (1, 256, 20)
value = value.permute(0, 2, 1)
# (1, 20, 256)
## sim
sim_map = torch.matmul(query, key)
# (1, 10000, 20)
sim_map = (self.key_channels**-.5) * sim_map
# (1, 10000, 20)
sim_map = F.softmax(sim_map, dim=-1)
# (1, 10000, 20)
return sim_map
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
proxy=get_proxy(feats,probs)
sim_map=get_sim_map(feats,proxy)
Step3:获得上下文表示
由step2计算得到simmap,其乘以V则可context,将context和像素特征进行拼接,再做通道调整得到最终的上下文表示,计算公式如下:
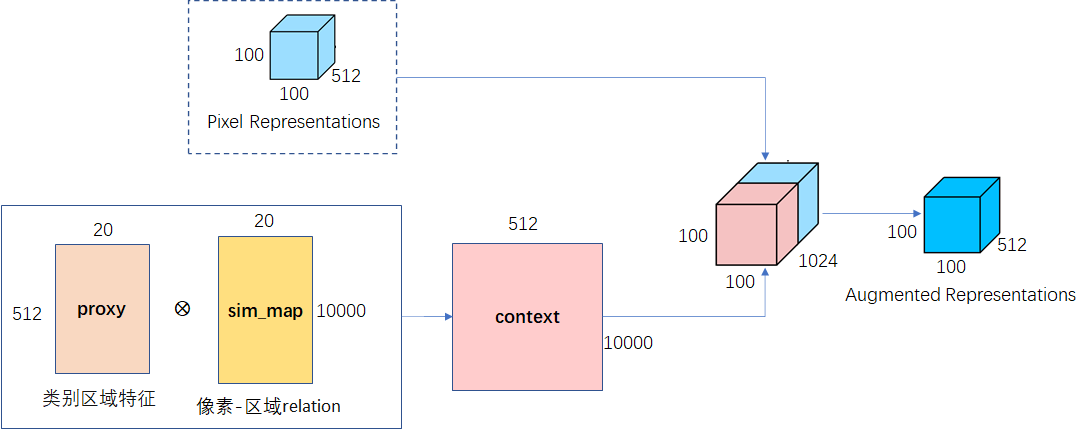
代码如下:
def get_context(feats,proxy,sim_map):
context = torch.matmul(sim_map, value) # hw x k x k x c
# (1, 10000, 256)
context = context.permute(0, 2, 1).contiguous()
# (1, 10000, 256)
context = context.view(batch_size, self.key_channels, *x.size()[2:])
# (1, 256, 100, 100)
context = f_up(context)
# (1, 512, 100, 100)
output = self.conv_bn_dropout(torch.cat([context, feats], 1))
# (1, 512, 100, 100)
return output
if __name__ == "__main__":
feats = torch.randn((1, 512, 100, 100))
proxy=get_proxy(feats,probs)
sim_map=get_sim_map(feats,proxy)
output=get_context(proxy,sim_map)
分割中的attention或transformer
了解了ocrnet后,再学习这个内容添加链接描述
有时间再学习
mask2former
尽管MaskFormer在多个任务上取得了很好的结果,但是其相较于SOTA还有较大gap,尤其是在实例分割任务上。此外,MaskFormer难以去训练,且需要的显存资源较多。为此,本文提出了Mask2Former,主要包括三点创新
- 使用了masked attention,将attention计算限制在需要预测的分割片段上
- 使用了多尺度高分辨率特征,帮助分割小物体
- 提出一些优化手段。比如说对调self-attention和cross-attention、使得query embedding可学习、移除dropout等
- 将loss在随机采样的point上计算,而不是全部,以减少显存消耗
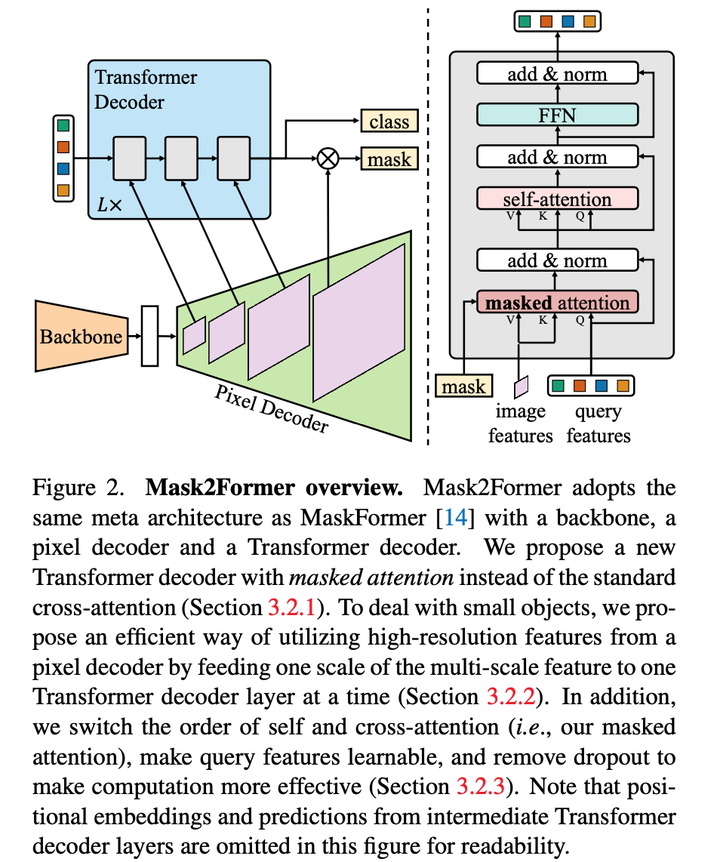
masked attention
我们知道decode里边有个masked attention的,就是控制哪两个token能产生attention。
这里作者使用一个大胆的假设,就是我们在做embeding的时候,我们只需要foreground这些区域,他们之间做attention就可以了,也就是原来在maskformer里边,每个像素和整张图像做attention,那么现在这个像素,只和自己同一个类别的,都是同一个qurey的像素,他们之间做attention。
这个是本文相对maskformer最主要的区别,最核心的贡献,公式参考论文
High-resolution features
高分辨率图像有助于提升模型效果,尤其是小目标。但是用全部高分辨率图像过于昂贵,本文使用金字塔形状的decoder,具体为多尺度deformable Transformer。这种多尺度feature将会输入到Transformer decoder,与query feature做masked attention,如上图2所示。Transformer decoder包括三层,重复L次,所以Transformer decoder共有3L层,本质是多尺度transformer
Optimization improvements
其一就是更换self-attention与cross- attention,因为刚开始的query feature是与图像无关的,因此先用self- attention不会丰富特征。很多情况下,第一层的decoder的query是全零或随机初始化的,使用self attention相当于q k v全是随机值,尝试这样的改进确实可以!其次,采用可学习的query feature,此时它更像一个region proposal network。最后,去除了dropout层。
提升训练效率
Mask2Former没有在全部point上计算loss,而是依据importance sampling稀疏采样K个point,这里的K为12544。该方法可以节省3倍内存















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









