







目录
支持任意语义分割任务类型,包括医学语义分割、遥感语义分割、作物语义分割等。支持任意数据类型,无需修改代码,tif、png、jpg等。本教程以Unet为例,其他模型可以替换模型文件即可。
一、数据介绍


二、代码实现
1、UNet网络
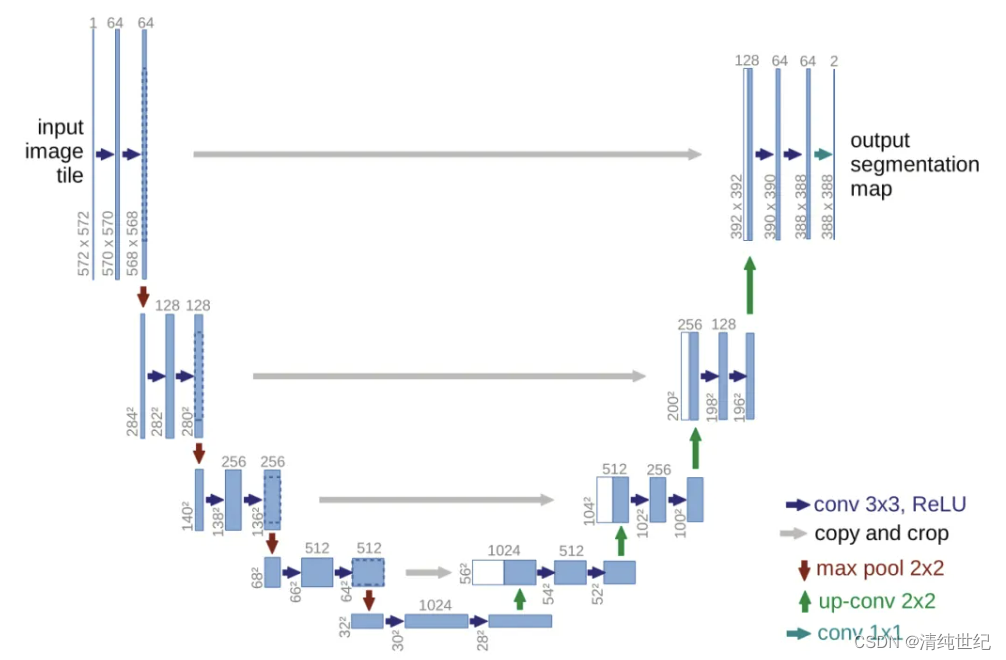
import torch.nn as nn
import torch
class UNet(nn.Module):
def __init__(self, input_channels, out_channels):
super(UNet, self).__init__()
self.enc1 = self.conv_block(input_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
self.center = self.conv_block(512, 1024)
self.dec4 = self.conv_block(1024 + 512, 512)
self.dec3 = self.conv_block(512 + 256, 256)
self.dec2 = self.conv_block(256 + 128, 128)
self.dec1 = self.conv_block(128 + 64, 64)
self.final = nn.Conv2d(64,out_channels, kernel_size=1)
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
enc1 = self.enc1(x)
enc2 = self.enc2(self.pool(enc1))
enc3 = self.enc3(self.pool(enc2))
enc4 = self.enc4(self.pool(enc3))
center = self.center(self.pool(enc4))
dec4 = self.dec4(torch.cat([enc4, self.up(center)], 1))
dec3 = self.dec3(torch.cat([enc3, self.up(dec4)], 1))
dec2 = self.dec2(torch.cat([enc2, self.up(dec3)], 1))
dec1 = self.dec1(torch.cat([enc1, self.up(dec2)], 1))
final = self.final(dec1)
return final2、数据集划分
指定训练集、验证集、测试集的大小
if __name__ == '__main__':
# 指定源文件夹路径和训练集、验证集、测试集文件夹路径
source_folder = r"./data/data"
train_folder = r"./data/train"
valid_folder = r"./data/val"
test_folder = r"./data/test"
# 指定数据文件夹路径和标签文件夹路径
data_folder = r"./data/data"
label_folder = r"./data/label"
# 指定训练集、验证集和测试集数据文件夹路径
train_data_folder = r"./data/train/data"
valid_data_folder = r"./data/val/data"
test_data_folder = r"./data/test/data"
# 指定训练集、验证集和测试集标签文件夹路径
train_label_folder = r"./data/train/label"
valid_label_folder = r"./data/val/label"
test_label_folder = r"./data/test/label"
# 调用函数划分训练集、验证集和测试集
split_dataset(data_folder, label_folder,
train_data_folder, valid_data_folder, test_data_folder,
train_label_folder, valid_label_folder, test_label_folder,
valid_ratio=0.2, test_ratio=0.2,
label_and_data_name_are_equal=True,label_add_name="")3、超参数设置
# -------------参数设置------------------------
num_epochs = 50 # 迭代次数
lr = 0.001 # 学习率
class_num = 9 # 类别数量
batch_size = 8 # 批量大小
re_size = (224, 224) # resize大小,如果不需要,则 None
extension_img = "png" # 图像后缀
extension_lab = "png" # 标签后缀
# -------------------------------------------4、数据加载
支持多波段数据,支持tif、png、jpg等格式。定义数据后缀即可
# 加载训练集
images_dir = r"./data/train/data"
labels_dir = r"./data/train/label"
train_dataset = RSDataset(images_dir, labels_dir,image_size=re_size, extension_img=extension_img, extension_lab=extension_lab)
trainloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 加载测试集
images_dir = r"./data/val/data"
labels_dir = r"./data/val/label"
val_dataset = RSDataset(images_dir, labels_dir,image_size=re_size, extension_img=extension_img, extension_lab=extension_lab)
valloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)5、训练
# 开始训练
best_score=0.0
for epoch in range(num_epochs):
total_loss = 0.0
model.train()
label_true = torch.LongTensor()
label_pred = torch.LongTensor()
for i, (images, labels) in enumerate(trainloader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.cpu().item()
label_true = torch.cat((label_true, labels.data.cpu()), dim=0)
label_pred = torch.cat((label_pred, outputs.argmax(dim=1).data.cpu()), dim=0)
total_loss /= len(trainloader)
acc, mean_acc, mean_iou,_ = label_accuracy_score(label_true.numpy(), label_pred.numpy(), class_num)
print('epoch:[{}/{}], train_loss:{:.4f}, acc:{:.4f}, mean_acc:{:.4f}, mean_iou:{:.4f}'.format(
epoch + 1,num_epochs, total_loss, acc, mean_acc, mean_iou))
6、结果出图
# -------------参数设置------------------------
class_num = 9 # 类别数量
re_size= (224, 224) # resize大小,如果不需要,则 None
extension_img = "png" # 图像后缀
extension_lab = "png" # 标签后缀
batch_size = 8 # 批量大小
color = np.array([[125, 255, 100],
[0, 45, 100],
[50, 100, 150],
[150, 200, 40],
[0, 78, 32],
[96, 196, 235],
[5, 156, 246],
[46, 79, 129],
[56, 79, 205]]) # 显示的颜色编码
# -------------------------------------------数据

预测结果
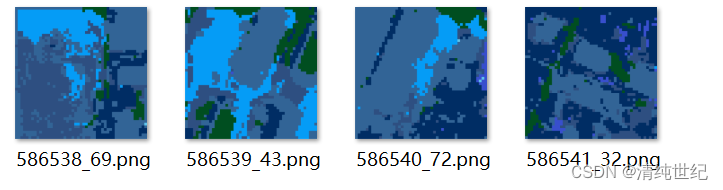
由于训练次数少,使用的数据仅为20个用于测试,因此精度较低,结果不太理想。有需要的可以自行增加数据和迭代次数。
附录
1、RGB彩色标签转单波段
由于网络使用的0,1,2,3的但波段灰度标签。如果我们是RGB色彩的三波段标签,就需要进行转换。根据RGB颜色码转:
import numpy as np
import cv2
import os
from utils import find_files_by_extension
# 标签中每个RGB颜色的值
VOC_COLORMAP = np.array([[0, 0, 0],
[0, 0, 128]])2、查看标签
可通过该代码查看标签
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 读取图像
image_path = r"G:\000 其他参考与资料\0 出售\语义分割数据集\val\mask_merge\2017_2018\9\583538_70.png"
# image = plt.imread(image_path)[:,:,2]
image = np.array(Image.open(image_path))[:,:,1]
print(np.max(image))
print(image.shape)
# 显示图像
plt.imshow(image)
plt.axis('off')
plt.show()
三、项目代码
本项目的代码通过以下链接下载:基于UNet网络的遥感图像语义分割教程(含python代码)















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











