









在三十而立的日子,把很久之前写的东西发出来,以纪念这个特殊的日子。
因为研究生研究经历,以及工作经历中前前后后涉及过这块,之前也和很多人私下探讨过这个领域问题,现在把里面一些关键点写出来,算抛砖引玉吧。
范涛
发表于2017/12/07
--------------------------------------------------------------------------------------------------------------
背景
为什么是图模型?
(1) 现实世界,实体之间本身就是存在自然关联的。
(2)欺诈者容易改变自身欺诈手法,逃避风控规则,但是他难以改变的全部关联关系,以及难以掌握全局视图,难以让他所在网络群体同步执行相同操作来躲避风控。还有一句话"天网恢恢,疏而不漏",当关联网络覆盖到一个很大范围时候,欺诈者即使再小心,可能也会无意中暴露出一点蛛丝马迹。在一个大型关联网络中,是十分容易发现逻辑不一致的地方(当一个人用一个谎言弥补自己的的过错时候,未来他会用更多的谎言去圆当初的谎言,这个时候是十分容易出现逻辑悖论)。
图模型挑战:
(1)标记数据获取难度大,效果评估难度大;
(2)工业界关联网络规模巨大,要求算法不仅识别精度高,在时间和空间上能scalable。
(3) 如何对模型进行解释
技术方案
一:
Structure based
1.1 Feature based
1.1.1 构建分类模型
计算节点的入度,出度,聚类系数,节点介数,node2vec(节点向量表现形式)等,利用这些feature,以及节点本身具备的额外属性特征构建分类器,识别是否欺诈。这种监督方法也比较主流,效果还是不错的(蚂蚁金服人工智能部对外技术分享提到过他们把node2vec,融入到风控模型中,带来不错的效果提升[1])。
风险点:把图模型的特征融合到样本特征体系中,需要考虑覆盖情况,当你的关联数据不够庞大时候,图模型特征可以覆盖的样本可能不足,这在训练和应用监督模型时候可能是个问题。
1.1.2 挖掘异常subgraph
在网络结构,比如某些subgraph在某些feature上(如平均degree值)远高于其他,那这种结构在我们定义的网络关系中是否合理?
当我们根据历史欺诈case发现某种欺诈场景的关联网络subgraph基本呈现特定结构,那我们可以在全局的关联网络图中把符合这个特定结构的subgraph都找出来。

1.2
Influence Propagation based
1.2.1 半监督方法
标记一些黑信息种子节点,通过网络信息传播算法对节点黑信息进行扩算,发现更多的黑信息节点。常见的信息传播方法有personal pagerank,trust rank,anti-trust rank等[4][5][6]。但这几种算法基本都是基于有向图的传播,同时传播过程都有自己的假设前提。以网页连接图为例,有这样的假设条件:好的网页一般会连接好的网页,极少会连接到恶意网页,恶意的网页一般只会被恶意网页连接,但是恶意网页连接的网页未必是恶意的,因为他们通过连接一些好的网页来提高自己影响力。所以trust rank 算法进行信任节点传播时候,是沿着节点的出节点信任传播,执行personalpagerank。但是anti-trust rank 算法对恶意信息进行传播时候则不能这样进行,不能沿着出节点对恶意值进行传播,而是如假设所说,应该沿着这个节点入节点对恶意信息进行反向传播。这种情况,可以把原来网络图连接关系进行反转(入链变成出链,出链变成入链),然后执行personalpagerank,得到每个节点恶意得分。
值得思考和深入研究的是,很多欺诈网络是无向图,利用上面的传播方式是否合理? 或者如何把无向图转成有向图,再执行上述算法?同时即使是有向图,实际场景是否满足这个anti-trust算法假设呢? 以支付交易为例,支付转账交易本身是有向图,一般欺诈节点就是转账接收方,但是转账发起方却未必是欺诈(如被骗交易),如果这对这种case一般就不能直接应用anti-trust进行恶意信息正向传播,反而应该进行类似trust-rank那样沿着出节点进行正向传播恶意度。但是对盗卡的转账交易,这种基本是满足anti-trust假设条件的。 总的来说,应该根据实际业务场景去定制你的算法模型。
1.2.2 无监督方法
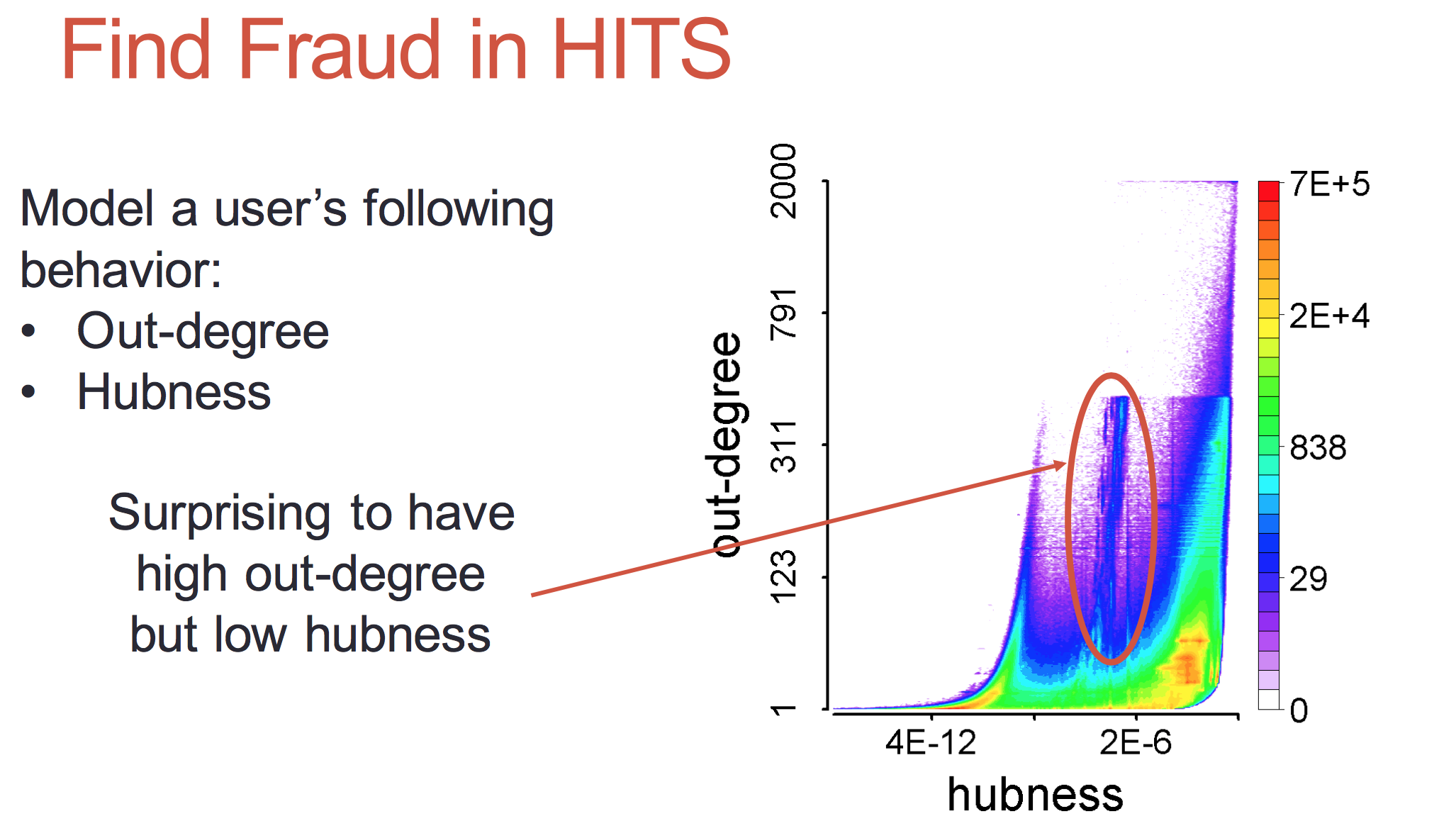
“CatchSync”[7]算法是用来捕获大规模有向图中同步行为,利用HITS算法,计算节点的hub值,authoritativeness值。
构建节点出度-hubness 分布图,入度-authoritativeness分布图。通过对这两个分布图分析,可以发现节点异常行为。
当一个节点的邻居节点大多属于这个分布图同一个区域,那说明节点的邻居具有同步行为。也可以通过衡量节点的邻居节点和网络其他节点在这些分布图区域一致性占比,来衡量节点的正常性。

二: Community based methods
2.1 介绍几个经典在工业界应用不错的community detection 算法
2.1.1
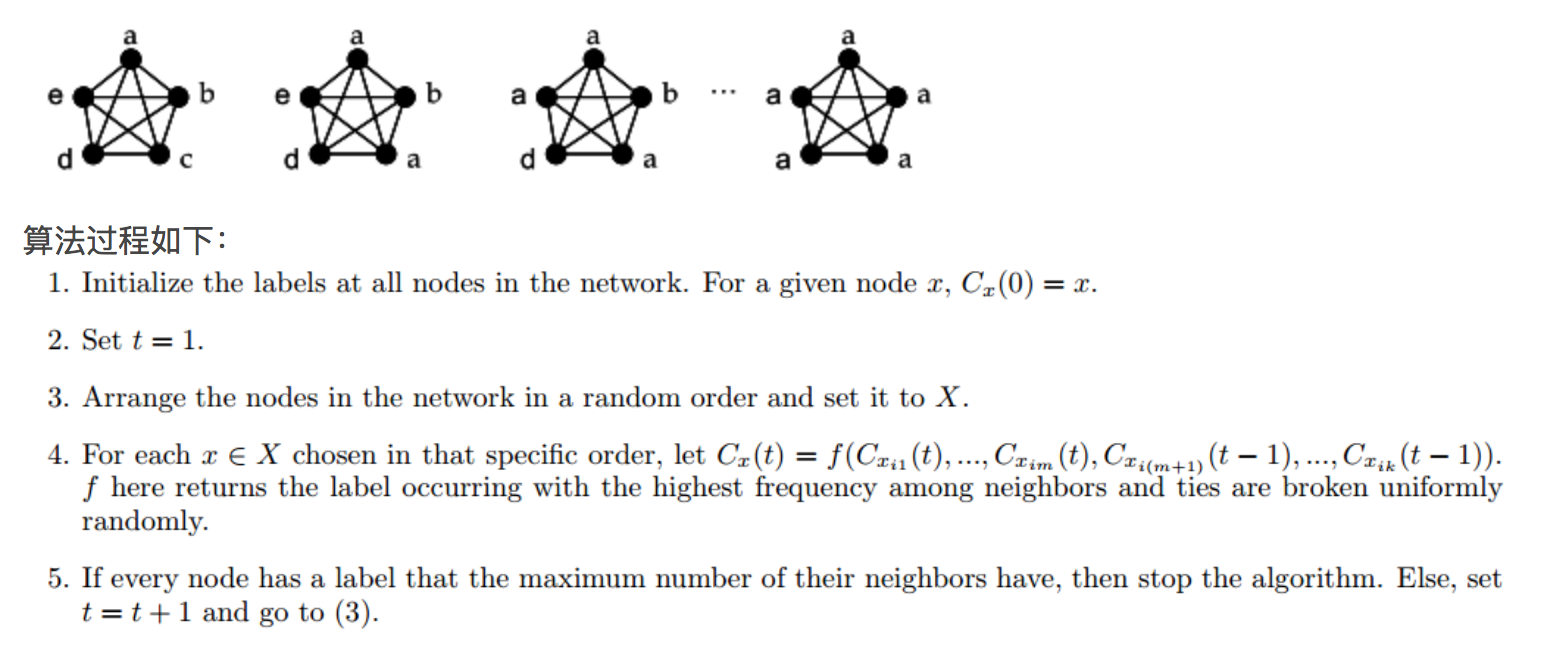
label propagation algorithms (LPA)
[8]
这个方法是每次用户获取邻居中出现频次最高的社区标签作为自己的标签,反复迭代,直到收敛。这个算法一般使用异步更新节点社区标签,因为如果网络出现局部二部图结构,会出现震荡。他这个不是直接优化模块度的,时间很快,线性时间复杂度,但是经常出现不收敛情况,同时因为引入了随机性,容易导致每次结果不一致。
2.1.2 LabelRank
[9]
A Stabilized Label Propagation Algorithm for Community Detection in Networks.
LabelRank 主要解决LPA算法的不收敛,结果不稳定问题,同时保持同样的时间复杂度,这个对大规模数据很重要。
a.
Propagation
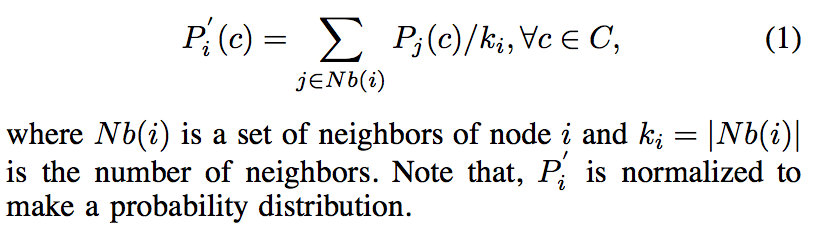
每个节点的初始化如下:

b. Inflation
概率膨胀操作,提高每个节点高概率的社团概率,降低低概率社团概率
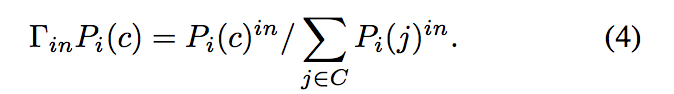
c. Cutoff
设置比率r 取值范围(0,1), 对每个节点过滤掉低概率社团。可方法可以有效的降低存储空间。
d. Explicit Conditional Update
在a,b,c 后,依然不能保证好的识别效果。最高的模块度值可能在算法收敛前达到。所以,引入该步操作。每一轮迭代,只有满足一定条件才更新节点的社团分布。这个条件背后的含义是当一个节点的最大概率社团和大多邻居的最大概率社团一致时候,则不再更新。

e. Stop criterion
什么时候算法收敛? 正常情况可以跟其他算法一样,算前后两次迭代分布差异,如果小于一定阈值的时候,则表明算法收敛。
但是,LabelRank 采用不同的机制。可以利用“Explicit Conditional Update” 规则,记录每次迭代中更新的节点数numChange。同时迭代过程中累计计算count(numChange),当任何一个numChange 的次数超过事先设定的阈值或者当本次迭代没有任何节点更新时候,则算法停止迭代。
2.1.3
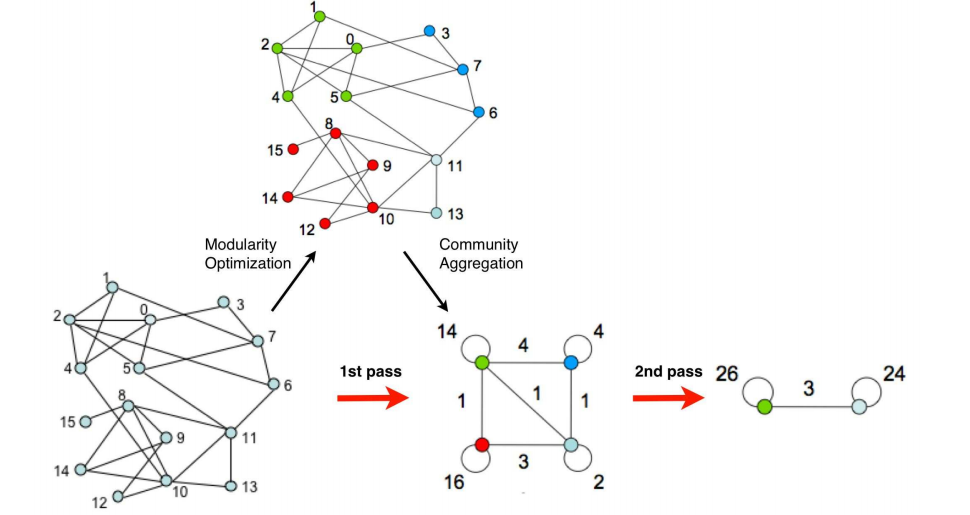
Fast unfolding
algorithms
[10]
这个算法速度也很快,效率很高,处理的节点的规模可以很大。
这个方法分两步:
(1)从节点合并开始, 构建第一步社团划分结果。每个节点根据模块度增益决定是否加入到邻居节点的社团中和到底加入到哪个邻居节点的社团中。每个节点按序执行该过程。
(2)重新构建网络。把第一步每个社团单做一个节点,边是原来社团之间链接边权的和。
迭代(1), (2),直到收敛。
其中模块度增益如下:
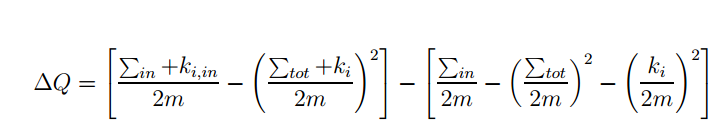
算法过程的图例如下:
2.2 介绍了3中community detection 算法后,那如何应用到欺诈检测上?
工业界常用的做法:(1)半监督算法。标记一些种子节点,比如标记一些欺诈用户,黑产设备等。基于这些种子节点开始扩散建立网络图,再利用community detection算法识别里面的团伙,这些能形成团伙的社团则被认为是欺诈社团。另外还有种思路就是不用从这些种子节点去扩散建立网络,而是通过某种定义,建立一个大的关联网络,对这个大的关联网络进行community detection, 看然后查看每个社团中包含种子节点的比率,以及种子节点在该社团和其他节点的紧密关联程度等。
(2)无监督方法。没有标记的种子节点,这种情况,是没法仅仅通过community detection来识别欺诈的。比如支付,登录场景中,如果只要有关联 ,就建立一条边,比如用户和用户转账,用户和手机号,用户和设备关联,这样就会成成一个巨大关联网络,这样划分出来的社团很多都不会是欺诈的? 那如何做? 这种情况就需要从构建网络的机制出发,比如构建边时候只有当有恶意情况下才建立边,后者大概率异常关联时候才开始建立边。这种假设前提保证了划分出的社团大概率是欺诈团伙, 单个节点某些恶意关联可能出错,但是当一个群体出现类似恶意情况,那这种大概率是欺诈。也是社团识别方法的一大优势点,可以发现群体规律,利用群体规律去定义和发现问题。
2.3 识别community中overlap节点
比如互联网金融里面很多黄牛,贷款中介可能是处于团伙这的桥接节点(bridge node),比如下图的节点t,t的邻居属于多个不同社团,这些桥接点很有可能是欺诈节点。
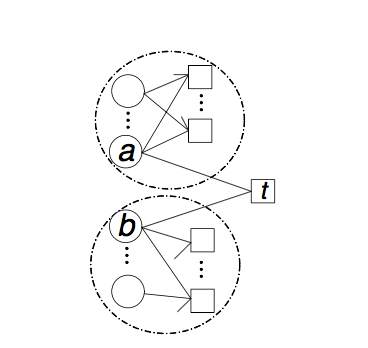
“Neighborhood Formation and Anomaly Detection in Bipartite Graphs” [11] 这个算法回到了两个问题: a)Neighborhood Formation :给定一个V1中节点a, 如何在V1中找到相似节点b? b) Anomaly Detection: 如何利用相似性,找到V2中桥接节点t?
a)节点相似性,通过类似personal pagerank思路,从节点开始进行随机游走,计算节点间的可达概率,来衡量节点间相似值。
b)Anomaly Detection是通过定义节点"normality scores"来衡量节点是否是桥接节点,进而被定义为异常点。
节点的“normality scores”是指节点邻居节点间的两两间相似度平均值,当“normality scores”比较低时候说明节点邻居节点是在不同社团。
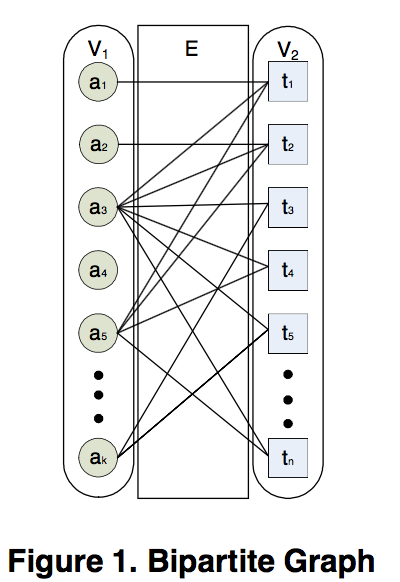
值得注意的是,这个算法的假设前提是网络中连接多个社团的桥接节点是异常节点。如果把这个应用在欺诈检测上,那就必须满足这个前提,否则算法就会失效。比如以一个人为中心的egonet网络,可能有多个社团,比如大学,高中,工作社团,这个人是这个网络桥接节点,但是这个人却不是欺诈节点。所以,需要在构建网络时候需要注意,比如利用贷款用户,贷款中介构建某种关联网络时候,需要满足当一个节点属于多个社团时候,那他极可能是欺诈节点的假设前提,否则是不可以直接应用这个算法的。
3 图模型效果解释性和评估
欺诈节点识别出来了,那如何解释这些节点?如何量化评估你算法识别效果?
(1)解释性:图模型效果解释性一直是个难点。这里面说下一些业界目前比较常用的做法。比如识别的恶意社团, 我们可以利用已有节点属性特征(如年龄,学历,收入水平,历史变动频率)来查看这个社团是否普遍一致具备某几种恶意特性。利用结构化信息识别恶意节点,我们不仅可以观察他的feature特性,也可以刻画出这些恶意节点间连接subgraph,辅助可视化手段去分析。(曾经看过一个案例,黑时时彩线下赌博,整个转账关系网络是呈现树状结构,并且层次化的。网络最上面庄家节点在香港,他有几个代理下家分别内地几个城市,这些下家负责和内地用户进行转账交易,最上面的庄家基本只和几个内地代理下家有现金交易,并且这些下家彼此负责的用户彼此交集很小。当我们利用图的方法挖掘出来这些节点,利用网络可视化将会很容易发现这些节点的异常。)
(2) 评估:图模型相对监督模型如分类器,评估难度很大,可能很难给出特别精准的评估效果,但是依然可以找到方法进行部分评估。评估分离线评估和在线评估。离线评估方法有 a) 交叉验证,评估历史一段时间坏样本的覆盖率,好样本的误伤率 b) 利用其它模型交互验证。在线评估: 主要是A/B Test ,设计线上评估指标,如登录 成功率,交易成功率,验证成功率等等,评估这些欺诈节点在在这些评估指标上的量化效果。
参考文献
[2] Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: a survey[J]. Data Mining and Knowledge Discovery, 2015, 29(3): 626-688.
[3] Sensarma D, Sarma S S. A survey on different graph based anomaly detection techniques[J]. Indian Journal of Science and Technology, 2015, 8(31).
[4]
Aktas M S, Nacar M A, Menczer F. Personalizing pagerank based on domain profiles[C]//Proc. of WebKDD. 2004: 22-25.
[5] Krishnan V, Raj R. Web spam detection with anti-trust rank[C]//AIRWeb. 2006, 6: 37-40.
[6] Gyöngyi Z, Garcia-Molina H, Pedersen J. Combating web spam with trustrank[C]//Proceedings of the Thirtieth international conference on Very large data bases-Volume 30. VLDB Endowment, 2004: 576-587.
[7]
Jiang M, Cui P, Beutel A, et al. Catchsync: catching synchronized behavior in large directed graphs[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 941-950.
[8]
Raghavan U N, Albert R, Kumara S. Near linear time algorithm to detect community structures in large-scale networks[J]. Physical review E, 2007, 76(3): 036106.
[9]
Xie J, Szymanski B K. Labelrank: A stabilized label propagation algorithm for community detection in networks[C]//Network Science Workshop (NSW), 2013 IEEE 2nd. IEEE, 2013: 138-143.
[10]
Blondel V D, Guillaume J L, Lambiotte R, et al. Fast unfolding of communities in large networks[J]. Journal of statistical mechanics: theory and experiment, 2008, 2008(10): P10008.
[11]
Sun J, Qu H, Chakrabarti D, et al. Neighborhood formation and anomaly detection in bipartite graphs[C]//Data Mining, Fifth IEEE International Conference on. IEEE, 2005: 8 pp.
[12] http://blog.csdn.net/hero_fantao/article/details/38929803















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









