







 本文详细介绍了信用风险评分卡开发过程的第四阶段,聚焦于如何构建有效的评分卡,以评估和管理信贷风险。
本文详细介绍了信用风险评分卡开发过程的第四阶段,聚焦于如何构建有效的评分卡,以评估和管理信贷风险。
范涛
发表于2017-03-31
第六章:Scorecard Development Process, Stage 4: Scorecard Development
开发流程: 对于申请评分卡(A 卡)来说,下面是整个开发流程。对于行为评分卡(B卡)来说,除了没有拒绝推断外,基本是一样的。
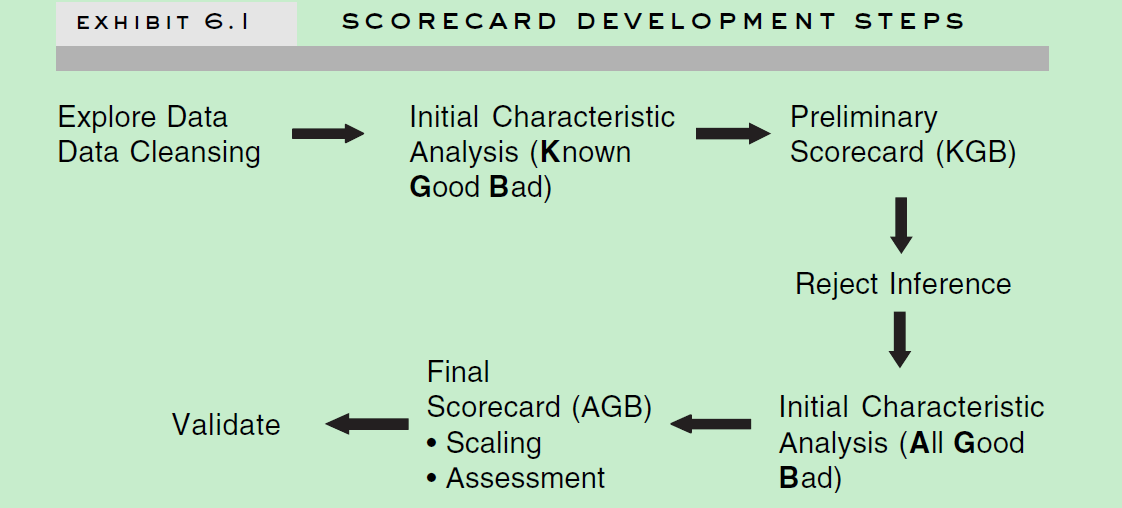
Explore Data : 数据收集和处理相关的。之前章节已经提到过
Missing Values and Outliers: 主要对缺省值和异常值处理,这里涉及方法比较多,0值填充,均值填充,中值填充,按分位点过滤异常值等。
Correlation:变量之间相关性,多重共线性。变量相关性常见的分析方法通过变量聚类(varclus),对变量进行分组,对每个分组的变量选取少数代表性高的变量,可以通过iv值来选或者根据业务逻辑选择等。多重共线性其实不是十分关注,增加样本量就会降低多重共线性可能,或者通过正则化进行处理。
Initial Characteristic Analysis
一般采用woe (weight of evidence), IV (informance value)去进行统计分析。woe去统计特征各个属性预测强度,IV去计算特征的重要性。woe公式如下:

IV 值如下:

关于age的分组属性的分析如下,包括了woe和iv值
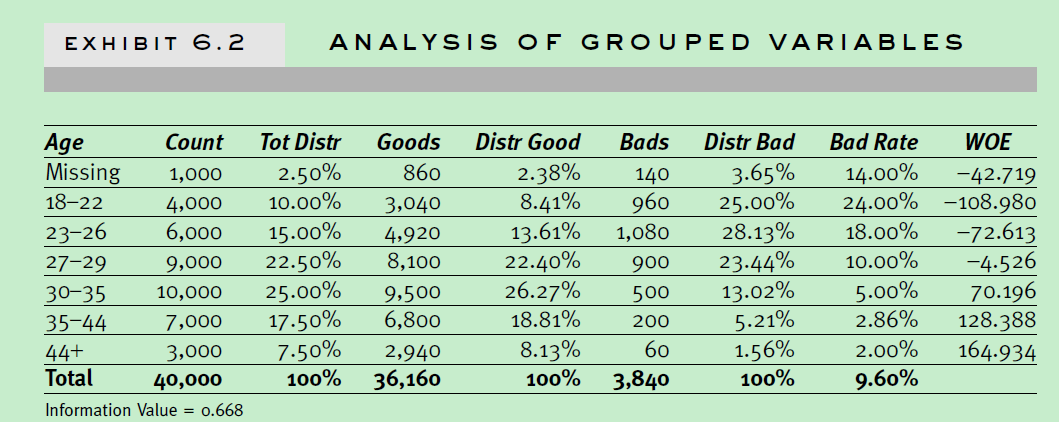
趋势分析 (分组变量各个属性的woe分布曲线):
一般要求woe分布呈线性序,如果出现非线性序,需要考虑一些业务因素看是否合理。
Preliminary Scorecard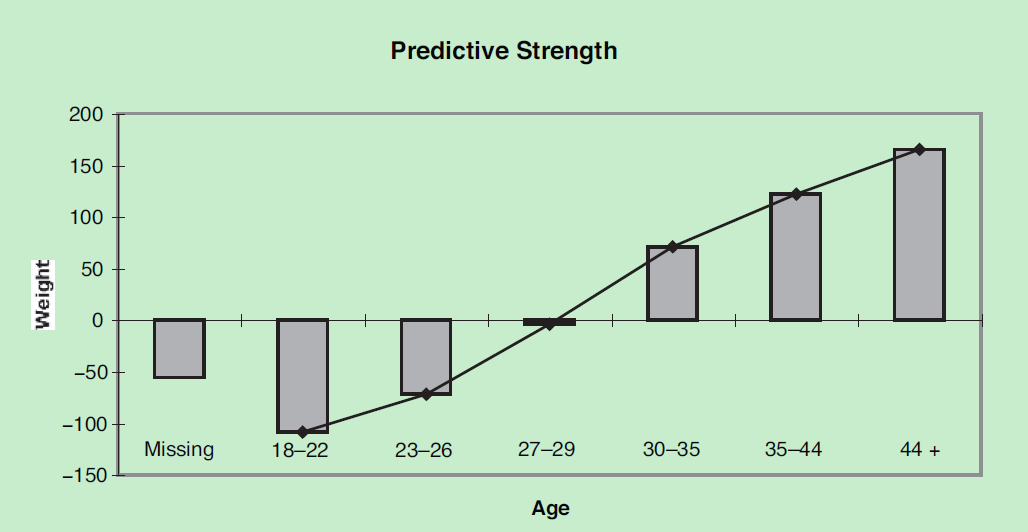
上面提到了样本处理,特征分析,下面提到模型学习,包括特征选择。
特征选择常用的方法: 前向选择(forward selection),后向消除(backward elimination),前后向算法(stepwise)
Reject Inference
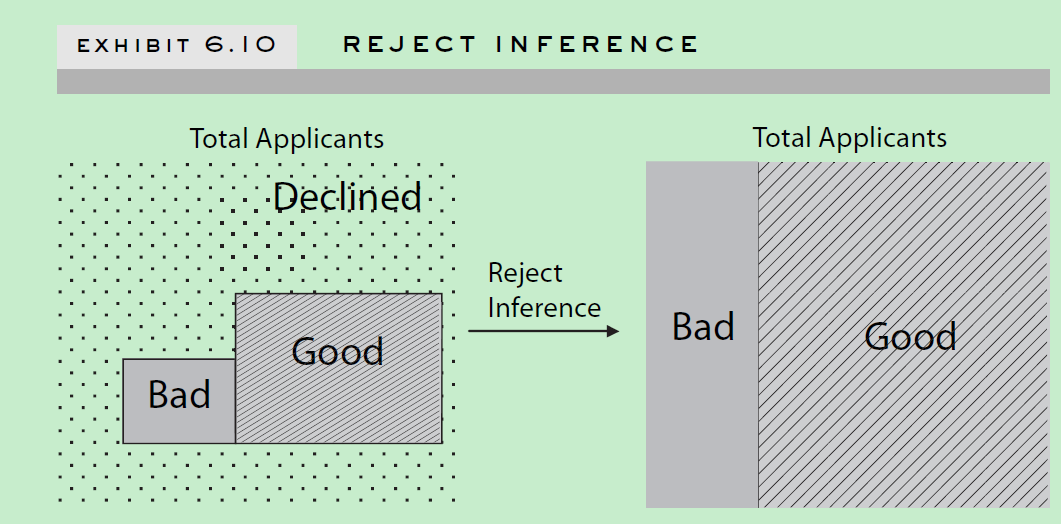
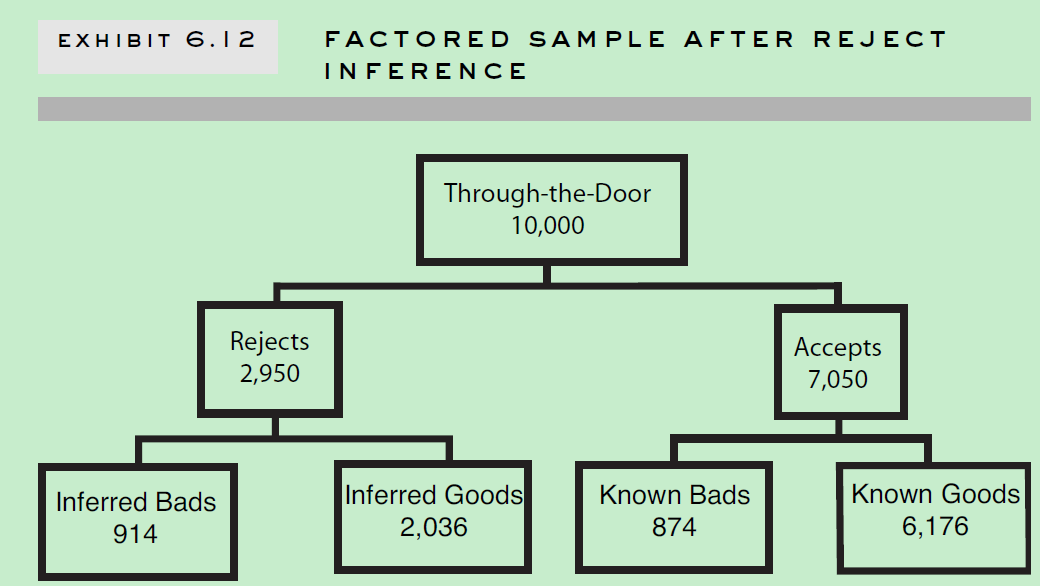
Reasons for Reject Inference
为何要做拒绝推断? 因为那些被拒绝的的账户样本,也有可能有好的样本以及坏的样本。如果我们只拿申请通过的样本做评分卡模型,那将会产生sample bias,不能很好的应用于整个申请人群。同时,拒绝推断也了为了方便评分卡模型覆盖之前决策影响。比如10000个申请样本中,有1000个是有严重不良行为的,如果拒绝了这1000个样本中940个,接受了60个,最后这60个样本最后大多数都是好样本的话。如果我不采用拒绝推断技术,只采用已知的好坏样本建立模型,你就会发现一种现象:有严重不良行为的反而是好的信用评分。拒绝推断技术可以中和这种影响。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3100
3100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









