









 本文介绍如何使用自定义函数GetSameDistRandomFrame解决在样本抽帧中等距随机抽取的问题,从20到75帧随机选取29帧,确保间隔均匀。
本文介绍如何使用自定义函数GetSameDistRandomFrame解决在样本抽帧中等距随机抽取的问题,从20到75帧随机选取29帧,确保间隔均匀。
在实际的样本抽帧需求中,往往有这样一种需求,例如,从20帧到75帧,抽取29帧数据,如果使用python自带的randint 函数,往往抽取的数据间隔是不一致的,这就需要等距随机抽样。
等距随机抽样就是,从开始的索引到结束索引,随机抽取若干个数,并要求数字之间的间隔尽可能的一致。搜索了好久,有使用randint的,使用randsample的,等等,都不满足我的需求,这样,只能是自己写了,所以将代码贴出来,如有帮助,希望大家留个脚印。
使用方法,例如从[20,75],随机抽取29个数,调用方式如下:
如果Status为False证明你给的数组的个数小于你抽取的个数。
piIndex,status = GetSameDistRandomFrame(20,75,29)def GetSameDistRandomFrame(iStartFrame,iEndFrame,iGetNum):
status = True
FrameIndex = []
iLength = iEndFrame -iStartFrame +1
iMargin =iLength//iGetNum
if iMargin == 0:
status = False
return FrameIndex,status
iLeft = iLength%iGetNum
iAddIndex = random.sample(range(0,iGetNum-1),iLeft)
iAddIndex.sort()
iEveryMargin = np.ones(iGetNum,dtype=np.int64) * iMargin
for i in range(iLeft):
index = iAddIndex[i]
iEveryMargin[index] = iEveryMargin[index] + 1
iStartIndex = iStartFrame
for i in range(iGetNum):
iEndIndex = iStartIndex + iEveryMargin[i] - 1
FrameIndex.append(iEndIndex)
iGet = random.randint(iStartIndex,iEndIndex)
iStartIndex = iEndIndex +1
return FrameIndex,status系统说我篇幅过段,后面都是废话,请忽略,谢谢!!!
或受成本拖累,康师傅方便面、饮品两大核心业务净利润降近四成。
8月22日晚间,康师傅控股有限公司(00322.HK,康师傅控股)披露2022年中期业绩。今年上半年,康师傅收益约382.17亿元,同比(较上年同期)增长7.97%;公司股东应占溢利同比下滑38.42%至12.53亿元,基本每股溢利为22.25分。
康师傅并未扭转2021年的净利润下滑态势,今年上半年,净利润同比大幅下滑超38%。实际上,康师傅自2021年中期以来一直处于“增收不增利”的状态。康师傅在财报中指出,净利润受毛利率下降2.83个百分点影响下滑,中期毛利率也降至近十年低点。
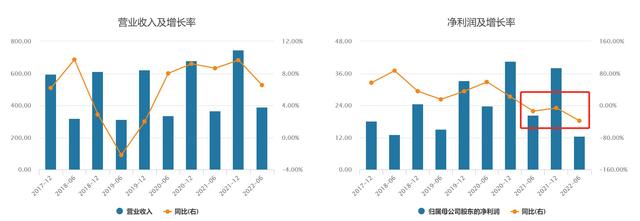
康师傅近五年中期及全年营收、净利润表现 来源:Wind康师傅的核心业务分为方便面及饮品两大板块,而这两大板块在今年上半年均出现毛利率下滑拖累净利润的情况。今年上半年,康师傅的方便面业务营收135.48亿元,同比增长6.49%,占集团总收益的35.45%。据尼尔森资料,康师傅方便面的销量与销售额继续保持市场占有率首位,分别为44.6%与46.7%。
而康师傅在财报中坦言,期内由于原材料价格上涨,方便面的毛利率同比下滑3.26%至20.63%,进而导致方便面板块上半年的净利润同比下滑39.23%至5.44亿元。
尽管今年上半年康师傅饮品业务整体收益242.98亿元,同比增长9.08%,但饮品板块同样面临原材料价格上涨压力及组合变化,毛利率同比下降2.64%至32.14%,导致饮品板块上半年净利润同比下降37.06%至7.44亿元。

















 6415
6415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









