







前言:网上搜索reid map的计算,会出现很多版本的计算方式,有很多中计算方式,但是这么多哪一个是正确的,看了这么多版本该信谁的?所以还是去Google找资料,看paper,下面是我的个人理解,希望能帮到你
MAP的计算在目标检测中和图像检索中稍有不同
REID的评价标准
首先说一下 REID的评价标准,常见的有 top-1 top-5 top-10 CMC MAP评价指标,那么为什么要有这么多的评价指标,都是干嘛的,简单来说top-n的指标大家都知道是干嘛的,但是这个指标不能很好的评价模型的好坏,所以这里就提出了另外的计算方式CMC,这个指标是在top-n的指标上生成的,那他是干嘛的,比如我有3个query:
下述中的0 1 不代表ID,只代表是不是和query对应的ID,1代表是一样的ID
第一个query的结果为 1,0,0,0,1所以对应的top-1:100% top-5:100%
第二个query的结果为 0,0,0,0,0所以对应的top-1:0% top-5:0%
第三个query的结果为 0,0,0,0,1所以对应的top-1:0% top-5:100%
所以最终的CMC就是三者平均的结果(而不是具体针对某一个qurey的结果):top-1:33.3% top-5:50%,表示该模型top-1的整体识别准确率为 33.3%,对应的我们可以画出不同top-n下的CMC曲线,一次命中率越高,说明我们的模型性能越好
那么为什么又有AP了,假如我们现在只计算top-1的CMC,现有这样的一个查询结果,CMC都是1,但是明显可以看到b的效果好于c的,所以在multi-query的背景下,CMC指标不再是一个很有效的指标,所以这里就要AP这个指标来评判了,所以才计算MAP
note: 这张图来自market-1501提出的paper : Scalable Person Re-identification: A Benchmark
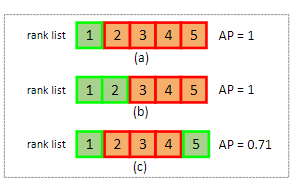
REID MAP的计算
图像检索中的MAP的计算又分为 single-shot和 multi-shot,不同的shot方式对应不同的map计算方式
1、single-shot
该种方式说的是在gallery中最多只有一个匹配,这个可以参考我的这篇博客中的解释,比如我想做一个行人的查询,在训练集中可能每个人都有很多张的照片,但是在构建 gallery 的时候,这里每个人也就是每个ID只有一个向量,这个向量可以是随机挑选这个人(相同的ID)其中一张照片生成的,也可以是这个人/ID的所有图像向量的均值,所以当我们拿一个query做查询的时候,在gallery中最多只会得到一个正确的结果。所以这里的AP就特别好计算,由于最终的recall的值要么为1,要么为0,所以这里就可以直接忽略recall的值,可以参照我下面博客链接中的方式进行实现。
2、multi-shot
这种方式计算的就很有意思了,目前网络上查询会出现很多的版本,每种版本的计算方式都略有不同
方式一
目前最常见的方式和single-shot的计算方式相似,只是计算AP的值,具体的计算方式见这个 图像检索:信息检索评价指标,
方式二
这里就是根据MAP的定义进行计算,即求P-R曲线下面的面积,关于precision 和 recall的计算方式和上述相同,然后根据目标检测的方式进行AP的计算。
但是这种方式还存在一个问题就是:预测的时候我们取前多少个作为prediction输出,验证集中ID对应gallery中相同ID的数量不同,有的多有的少怎么办,比如取前100个prediction输出的概率,那么如果一部分ID对应的相同ID的图像数量只有10张,另一部分有100张怎么办,是数据倾斜的问题还是MAP会将这样的输出进行抵消?论文中的MAP计算方式都是map@5、map@100还是 计算所有的gallery,进行排序?
(看了几个GitHub的实现链接1,Market1501Evaluat)
这几个中都是对于market1501数据集的evaluation的评判标准,这里面的计算有几个关键的点:其中的predctions是全部的gallery的计算结果,其中计算recall的分母为gallery中所有和query相同的ID图像的总数量(如果考虑 cross-view的话(也就是跨境识别),就要除去同一camera下的 junk图像),所以这里面不涉及到取预测值的前多少个,所以也就不涉及到上述中提到的问题了。
还有一种方式是比如取前5个prections,然后recall的计算分母就是5(默认输出的就应该是正确的,这个是之前一直想错的地方),计算方式和上面的相同,也是计算P-R曲线下面的面积,但是这里具体实现方式和之前做的不太一样,这里的计算方式为计算梯形的面积,具体的计算过程会感觉没有Recall的参与吗,但是实际上参与了,只是没有显示的参与。具体的解释见这篇博客(看过最清晰的解释)ReID任务中的CMC和mAP
note: 这里的计算方式和上述market-1501 paper 图中的计算结果是不相符的,但是目前很多的计算方式都是基于上述连接中的计算方式,paper中没有进行具体的描述,所以这里就暂时认为那张图只是进行说明,具体的计算还是以这个链接为准ReID任务中的CMC和mAP。
方式三
这里的方式是谷歌地标识别大赛的一种评价方式,这方式实现的方法和上述链接ReID任务中的CMC和mAP中的方式挺像的,也用到了 Recall ,只是将其放到了分母中。
其中 nq 的值为 prection的个数,和设定的100取最小值,一般的预测输出的个数就是gallery的大小,也就是说一般都是大于100的
mq为在gallery中和query相同ID的图像个数,取其和100的最小值,也就在另外一个角度解释了当有的图像在gallery中相同ID的图像数量多,有的少的计算方式不同,比如有的query图像在gallery中有10张相同ID的图像,那么我们预测输出的100个预测值中最多有10个正确的,有的query图像在gallery中有100张相同ID的图像,那么我们预测输出的100个预测值中可能就全部正确,这样对于那些图像数量少的就有点不公平了,所以这里就做了一个min的操作。
对应的代码链接:Google Landmark Retrieval 2020 中的MAP计算

最新:
目前确定的计算方式为方式二中的计算方式,因为很多GitHub上的实现方式为该种,计算所有的gallery中的数据(本人的项目中不用考虑cross-view的情况)
















 3775
3775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









