







作者简介:岑玉海,滴滴出行数据架构工程师,专注于分布式存储和分布式计算。
责编:仲浩(zhonghao@csdn.net)
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2016年程序员:http://dingyue.programmer.com.cn/
笔者使用Spark已超过一年,现在公司大部分的批处理任务和机器学习任务都运行在Spark平台之上,MapReduce已经成为历史。目前生产环境刚从Spark 1.4.1升级到最新版Spark 1.6.1,使用Yarn来调度和管理资源。本文将从升级到Spark 1.6过程当中遇到的若干问题和大家分享,我也会指出目前Spark存在的问题,希望引起重视。
内存问题
Spillable集合内存溢出
这个问题的具体错误信息:Unable to acquire 163 bytes of memory, got 0。这个Exception是Spark在申请不到运行内存的时候主动抛出来的,在处理大数据量的场景下很容易复现。在Spark 1.6,默认的Shuffle仍然是Sort方式,实际上是Tungsten-sort和sort合并之后的版本,为了详细阐述这个问题产生的根源,先回顾一下Tungsten-sort的流程(如图1所示)。
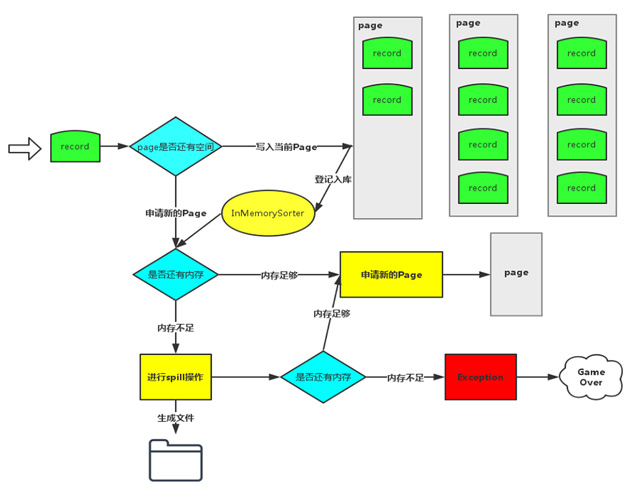
Record的key和value会以二进制的格式存储写入到ByteArrayOutputStream当中,用二进制形式存储的好处是可以减少序列化和反序列化的时间。然后判断当前Page是否有足够的内存,如果有足够的空间就写入到当前Page(注:Page是一块连续的内存)。写入Page之后,会把内存地址address和partitionId编码成一个8字节的长整形记录在InMemorySorter当中。当前Page或者InMemorySorter内存不够的时候会去申请内存,如果内存不够就要把当前数据Spill到磁盘了,如果还是申请不到内存就会报该Exception。
为什么Spill都无法释放内存呢?通过添加日志信息的方式,发现了有一个Spillable对象申请了很多内存,但是却不登记姓名,属于黑户一般的存在。
于是在社区发现了这个issue:SPARK-11293。明明发现了问题却不解决,让人很无奈。
之前使用的Spark 1.4版本也存在该问题,只是没有主动抛错误,最后演变成ExecutorLost。Spillable的具体实现有ExternalAppendOnlyMap和ExternalSorter,它们主要负责做聚合和排序。虽然自身也有Spill机制,但它的Spill不是必须的,有非常大的概率会把所有的数据保存在内存当中,等遍历完集合里面的所有数据,才会释放内存。在不修改代码的情况下,有两种方式可以减少它发生的概率:
- 增加出错阶段的partition数,在数据分布比较均匀的情况下,可以减少每个Task处理的平均数据量。
- 设置spark.shuffle.spill.numElementsForceSpillThreshold,该参数主要用于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









