







作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,从事过搜索和推荐相关工作。
责编:何永灿(heyc@csdn.net)
本文首发于CSDN,未经允许不得转载。
TensorFlow Wide And Deep 模型详解与应用(一)
前面讲了模型输入的特征,下面谈谈模型本身。关于 wide and deep 模型官方教程中有一段描述:The wide models and deep models are combined by summing up their final output log odds as the prediction, then feeding the prediction to a logistic loss function。从这里大概看出,线性模型与 DNN 模型进行结合的方式是对两者的预测结果进行相加,然后把相加过后的值拿去计算分类的 loss。下面我们在源代码级别把上面这段描述展开,详细分析 wide 端模型和 deep 端模型是如何实现结合的。
由于我们运用的只是分类模型,所以就不对回归模型进行分析。
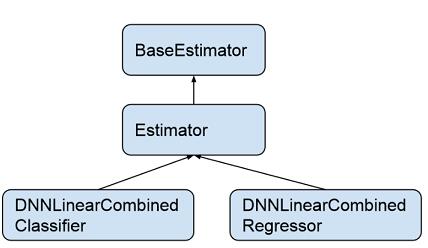
DNNLinearCombinedClassifier 类继承于类 Estimator,Estimator 类继承于类 BaseEstimator。BaseEstimator 是一个抽象类,定义了通用的模型训练以及评测的函数接口 (train_model, evaluate_model, infer_model),Estimator 类中用一个统一函数 call_model_fn 来实现 train_model, evaluate_model, infer_model。
为了更好了解整个过程,我们看看内部函数的调用过程(代码可以参见 estimator/estimator.py):
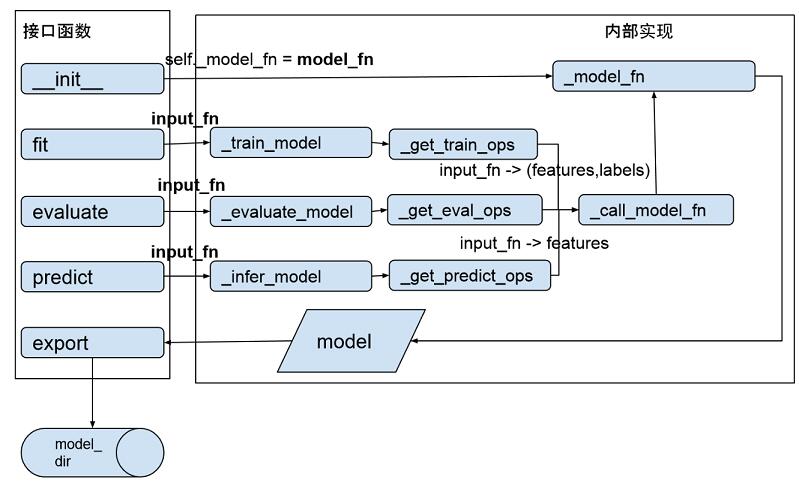
模型训练通过调用 BaseEstimator 的 fit() 接口开始,其调用栈是:fit -> _train_model -> _get_train_ops ->_call_model_fn(ModelKeys.TRAIN) -> _model_fn,最终_model_fn() 产生模型并通过 export 函数将模型输出到 model_dir 对应目录中。
我们把训练模型的调用过程在代码级别展开,标出关键的几个函数和数据结构,省略不关键的代码,希望能让读者看到训练模型的大致过程:
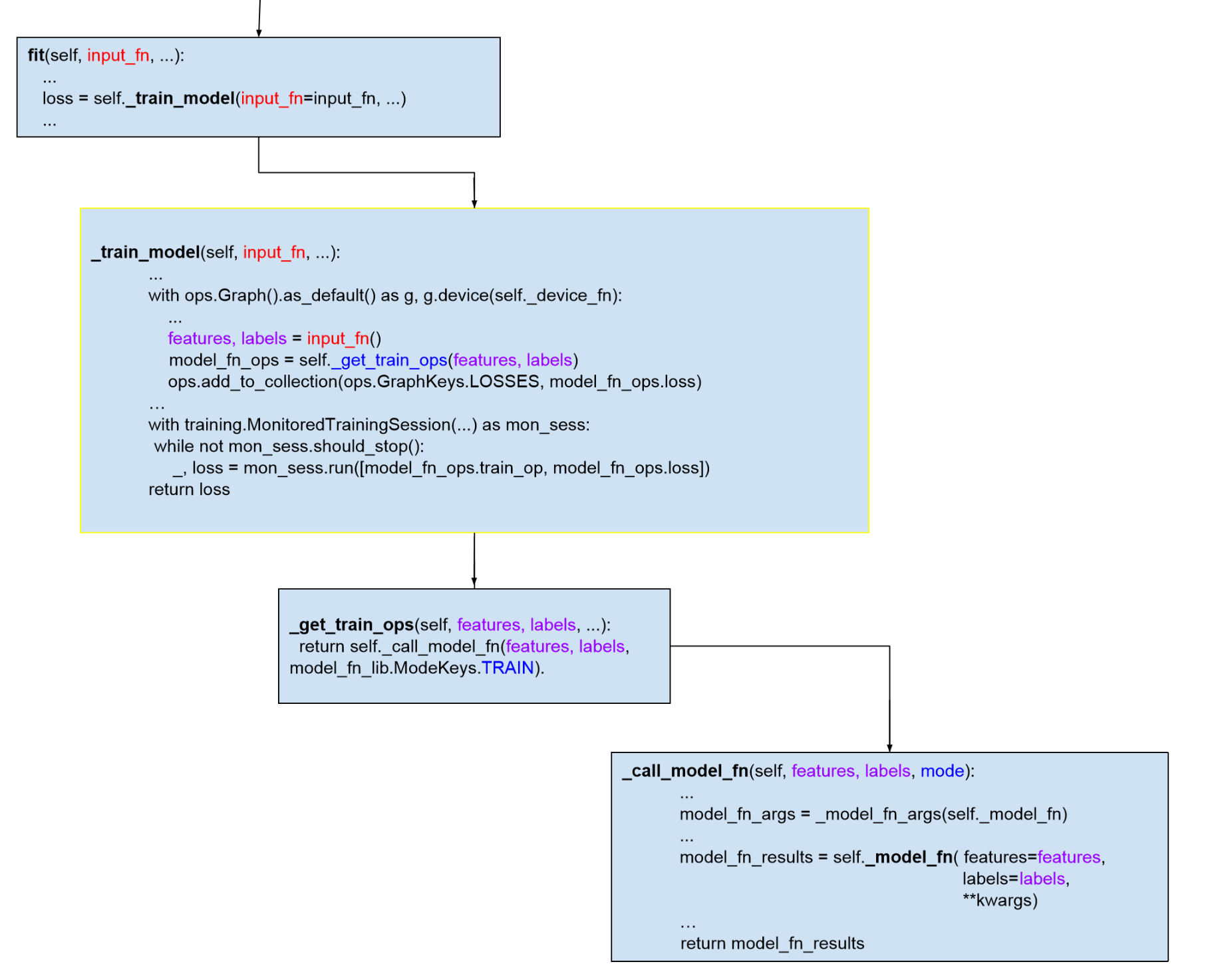
评测(evaluate)和预测(predict)的过程与训练(train)大致相同,读者可以通过源代码文件找到对应函数了解。可以看出,整个函数调用栈中最关键的 2 个函数是: input_fn 和 model_fn。input_fn 从输入数据中生成 features 和 labels,features 是一个 Tensor 或者是一个从特征名到 Tensor 的字典,如果 features 是一个 Tensor,程序会给这个 Tensor 一个空字符串的键值,转换成特征名到 Tensor 的字典。labels 是样本的 label 构成的 tensor。input_fn 由应用程序调用者提供实现,返回(features, labels)二元组,要求 tf.get_shape(features)[0] == tf.get_shape(labels)[0],也就是两个 tensor 的行数目得保持一致。model_fn 定义训练和评测模型的具体逻辑,如模型训练产生的误差 (model_fn_ops.loss) 以及训练算子(model_fn_ops.train_op)通过封装在 EstmiatorSpec 的对象中由 training 的 Session 进行调用。每个具体模型需要实现的是自定义的 model_fn。
DNNLinearCombinedClassifier 是如何实现自己的 model_fn 的呢?本文开头我们给出了它的初始化函数原型,进入初始化函数的实现中我们定位到代码行 model_fn=_dnn_linear_combined_model_fn。
这个就是 DNNLinearCombinedClassifier 的 model_fn。这个函数的定义如下:
def _dnn_linear_combined_model_fn(features, labels, mode, params, config= None)features 和 labels 大家都已经知道,mode 指定 model_fn 的操作模式,目前支持 3 个值:训练模型 (model_fn.ModeKeys.TRAIN),对模型进行评测 (model_fn.ModeKeys.EVAL),根据输入特征进行预测 (model_fn.ModeKeys.PREDICT),mode 的定义可参见文件 estimator/model_fn.py。params 和 config 参数分别定义模型训练的参数以及模型运行的配置。
模型训练的整个过程可以分为如下若干步:
(1)从 params 获取参数,定义模型优化函数
// 将输入的特征统一为字符串到 tensor 的 dict
features = _get_feature_dict(features)
// 定义线性模型的优化函数
linear_optimizer = params.get("linear_optimizer") or "Ftrl"
linear_optimizer = _get_optimizer(linear_optimizer)
// 定义 DNN 模型的优化函数
dnn_optimizer = params.get("dnn_optimizer") or "Adagrad"
dnn_optimizer = _get_optimizer(dnn_optimizer)
(2)构建 DNN 模型
首先从 dnn_feature_columns 构造 DNN 模型输入层:
dnn_feature_columns = params.get("dnn_feature_columns")
// dnn_feature_columns 中包括 DNN 模型需要的所有连续特征和 embedding 特征
net = layers.input_from_feature_columns(columns_to_tensors=features,
feature_columns=dnn_feature_columns,
weight_collections=[dnn_parent_scope],
scope=dnn_input_scope)这里的 features 是 feature column key 到 tensor 的 dict,在本文前面我们对每个特征都谈了它的 insert_transformed_feature(columns_to_tensors),在构建 DNN 模型输入层之前会调用每个 FeatureColumn 的 insert_transformed_feature 函数生成一个浮点数类型的 tensor 作为 DNN 输入层的一部分。
构建完输入层后,然后至底向上进行隐藏层构建,每层的隐藏单元的个数在参数
dnn_hidden_units 中定义:
dnn_hidden_units = params.get("dnn_hidden_units")
for layer_id, num_hidden_units in enumerate(dnn_hidden_units):
// 从输入层或者是下面一层隐藏层构建新的隐藏层
// dnn_activation_fn 定义隐藏层的激活函数,默认使用 RELU
dnn_activation_fn = params.get("dnn_activation_fn") or nn.relu。
net = layers.fully_connected(net,num_hidden_units,activation_fn=dnn_activation_fn,
variables_collections=[dnn_parent_scope], scope=dnn_hidden_layer_scope)
// 模型训练中对隐藏层进行 drop-out
// dnn_dropout 是舍弃隐藏单元输出的概率
dnn_dropout = params.get("dnn_dropout")
if dnn_dropout is not None and mode == model_fn.ModeKeys.TRAIN:
net = layers.dropout(net, keep_prob=(1.0 - dnn_dropout))
从最后一层隐藏层到输出层建立一个全连接就完成 DNN 模型的构建了, dnn_logits 是模型输出,它是一个分类数个数的 Tensor,Tensor 的每个元素对应 1 个分类的线性激活值(linear activation: w * net + bias):
with variable_scope.variable_scope( "logits", values=(net,)) as dnn_logits_scope:
dnn_logits = layers.fully_connected( net,
head.logits_dimension, // 分类个数
activation_fn=None, // 输出层不做非线性变换
variables_collections=[dnn_parent_scope],
scope=dnn_logits_scope)
从 dnn feature columns 中构建 DNN 输入层的工作主要由函数 layers._input_from_feature_columns 完成,每个训练样本上的 dnn feature column 的值拼接成一个 dense tensor 作为 DNN 的输入。
该函数的定义如下:
def _input_from_feature_columns( columns_to_tensors, feature_columns, weight_collections,
trainable, scope, output_rank, default_name)
transformer = _Transformer(columns_to_tensors)
for column in sorted(set(feature_columns), key 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









