







目录
一.KNN概念
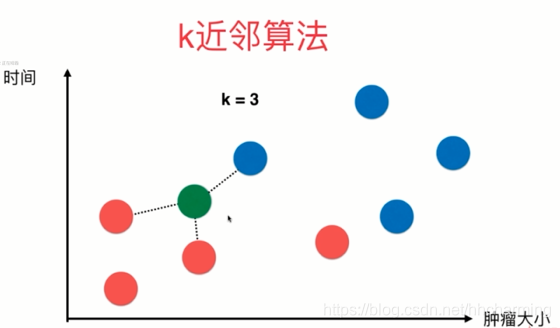
K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻近值来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
和它相近的K个样本中,哪个类别最多,就认为新的样本属于哪个类别。相似性靠两个样本在空间中的距离来决定。(如图,红色个数多于蓝色,该样本认为是红色类)
解决分类问题
二.简单例子
现有十组肿瘤数据,raw_data_x 分别是肿瘤大小和肿瘤时间,raw_data_y代表的是 良性肿瘤和恶性肿瘤,x代表的是测试数据,并用蓝色区分,我们需要通过kNN算法判断其实良性肿瘤还是恶性肿瘤。
1.KNN基础
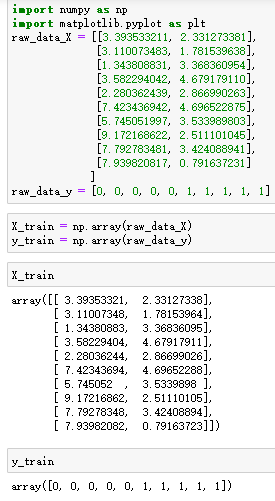
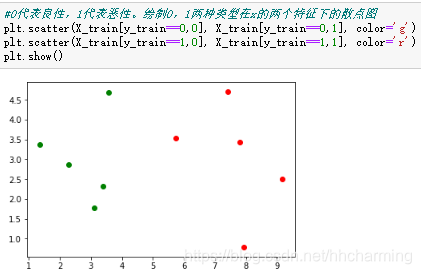
2.产生一个新点进行预测
绿色为良性肿瘤,红色为恶性肿瘤,蓝色为测试的样本
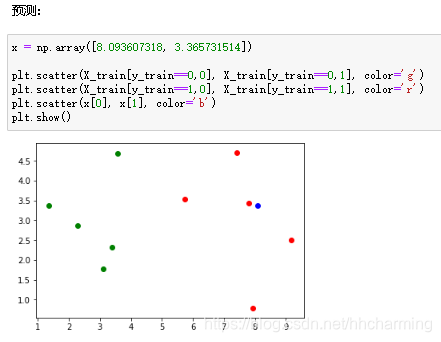
3.KNN过程
(1)先通过欧拉距离计算distances
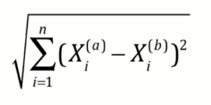
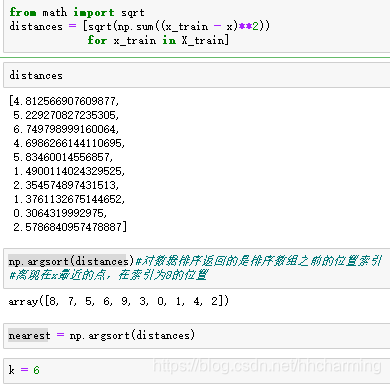
(2)然后想得到离他最近的K个点是哪些点
np.argsort(distances),得到离x从近到远依次是哪些位置的点。
(3)计算最近的6个点的y是什么,方法为在y中索引,nearest前k个
(4)投票。先统计上面的到的y得到votes,再votes.most_common(1)#找出票数最多的元素
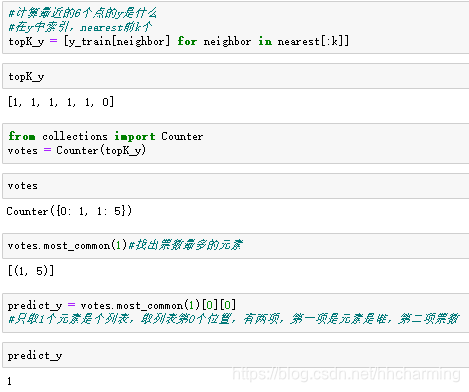
由以上结果知该样本为良性
三.使用scikit-learn中的kNN
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
x = np.array([8.093607318, 3.365731514])
#生成一个k为6 kNN的对象
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# 将训练数据写入,拟合数据集
kNN_classifier.fit(x_train,y_train)
# 预测数据
y_predict = kNN_classifier.predict(x.reshape(1,-1))
# 输出预测结果
print(y_predict )四.训练集、测试集
train_test_split
分离出一部分数据做训练,另外一部分数据做测试。
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ration must be valid"
if seed:
np.random.seed(seed)
#150个行的索引的随机排列
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_testsklearn中的train_test_split


















 2423
2423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









