










最近在研究自然语言处理过程中,正好接触到大模型,特别是在年初chatgpt引来的一大波AIGC热潮以来,一直都想着如何利用大模型帮助企业的各项业务工作,比如智能检索、方案设计、智能推荐、智能客服、代码设计等等,总得感觉相比传统的搜索和智能化辅助手段,大模型提供的方式更高效、直接和精准等,而且结合chat,能够实现多轮次的迭代,更接近或了解用户需求,提供更精准的答复。目前正在开展大模型部署应用测试,目前开源大模型主要就是Llama、ChatGLM大模型等,包括Llama-1和Llama-2,在其基础上的改进大模型有Chinese-LLaMA、OpenChineseLLaMA、Moss、baichuan等等,本文主要对原始Llama大模型进行了本地部署与测试,后续再逐步扩展,结合行业数据资源进行finetune,希望在开源模型的基础上对油气行业大模型构建有所帮助,Llama-2大模型部署及应用测试如下。
一、部署环境
环境:利用anaconda管理python环境
conda:conda 4.3.30
python:Python 3.10.4
cuda version:11.0,安装低于该版本的包即可,我安装的是cu102,GPU采用Tesla V100,详见GPU监测情况
env:/root/anaconda3/envs/torch/
require包如下,主要看torch、torchaudio、torchvision、transformers、uvicorn、fastapi、accelerate。
二、目前已部署的大模型和运行比较
Chinese-Llama-2-7b,运行速度慢,加载速度快
Chinese-Llama-2-7b-4bit,运行速度相对快,加载速度最快
chinese-alpaca-2-7b-hf,运行速度更快,加载速度慢
chinese-alpaca-2-13b-hf,运行速度更快,加载速度慢
open-chinese-llama-7b-patch,运行速度中等,加载速度慢
三、目前支持的运行方式:
1.控制台运行,详见chinese-llama2Test2.py,运行命令:python chinese-llama2Test2.py Chinese-Llama-2-7b
2.Rest服务运行,restful运行,详见restApi.py,运行命令:python restApi.py Chinese-Llama-2-7b
对于Rest服务的调用,主要用postman或DHC客户端模拟POST请求,Content-Type=application/json,post参数是json格式,如 {"prompt": "北京最佳的旅游时间", "history": []}
四、应用测试
1.单次测试代码
# 一次性访问
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
model_path = "model/Chinese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_path).half().cuda()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""
prompt = instruction.format("用中文回答,When is the best time to visit Beijing, and do you have any suggestions for me?")
generate_ids = model.generate(tokenizer(prompt, return_tensors='pt').input_ids.cuda(), max_new_tokens=4096, streamer=streamer)
2.输出结果

3.循环交互模式测试代码
#循环交互模式
import torch
import sys, getopt
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
if (__name__ == '__main__') or (__name__ == 'main'):
# 检查参数个数
argc = len(sys.argv)
if (argc <= 1):
print('missingParms' % locals())
sys.exit()
#处理命令行参数
modelName = sys.argv[1]
#model_path = "model/Chinese-Llama-2-7b"
model_path = "model/"+modelName
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
if model_path.endswith("4bit"): #支持q4的轻量化模型,选择对应模型即可。
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map='auto'
)
else:
model = AutoModelForCausalLM.from_pretrained(model_path).half().cuda()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""
while True:
text = input("请输入提问 prompt\n")
if text == "q":
break
prompt = instruction.format(text)
generate_ids = model.generate(tokenizer(prompt, return_tensors='pt').input_ids.cuda(), max_new_tokens=4096, streamer=streamer)4.输出结果
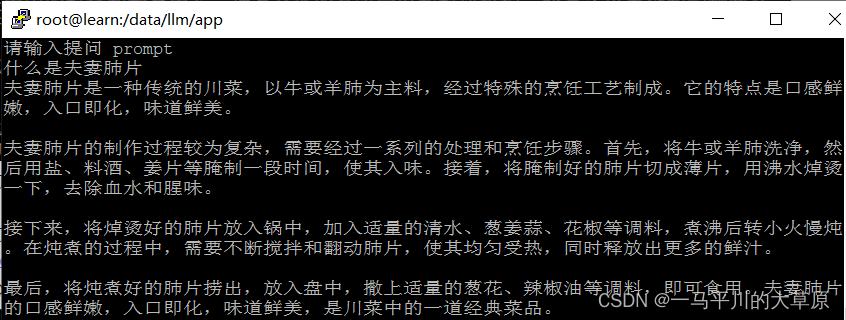
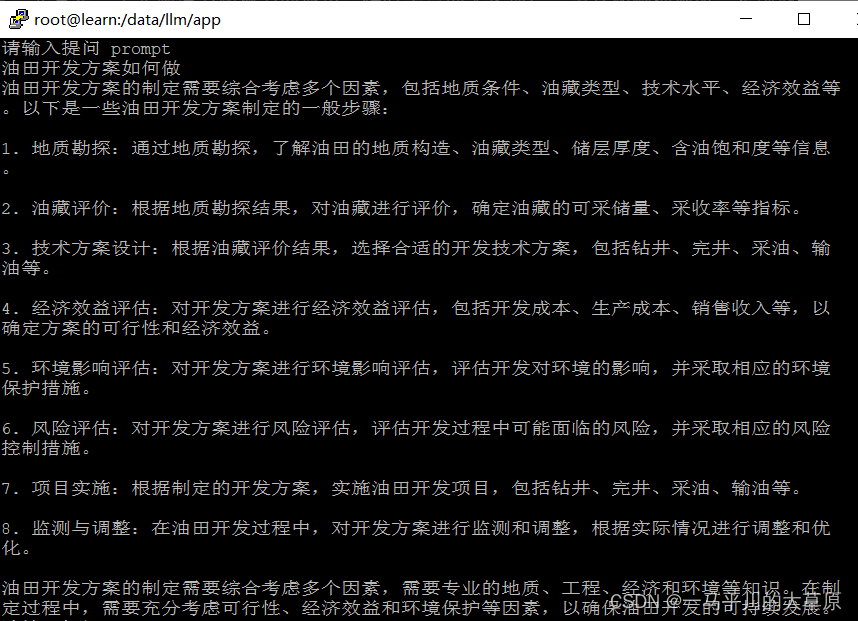

五、监测GPU的使用情况
命令:watch -n 1 -d nvidia-smi
1.启动时的GPU状态

2.运行过程中的GPU状态

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











