







 文章介绍了图形学中几种重要的光照和纹理技术,包括Blinn-Phong光照模型、Gamma校正以适应不同显示器的亮度表现、sRGB纹理处理颜色空间问题、阴影映射技术(点阴影、法线贴图、视差贴图和陡峭视差映射)以及视差遮蔽映射,这些都是提升3D场景真实感的关键技术。
文章介绍了图形学中几种重要的光照和纹理技术,包括Blinn-Phong光照模型、Gamma校正以适应不同显示器的亮度表现、sRGB纹理处理颜色空间问题、阴影映射技术(点阴影、法线贴图、视差贴图和陡峭视差映射)以及视差遮蔽映射,这些都是提升3D场景真实感的关键技术。
目录
Blinn-Phong
phong 模型中的高光项在视线方向和反射方向角大于 90 度时,反射项变为 0
这导致了奇怪的效果
因此现在计算一个半程向量,他是光线的方向向量和观察向量加到一起,并将结果正规化(Normalize)
当视线正好与(现在不需要的)反射向量对齐时,半程向量就会与法线完美契合。所以当观察者视线越接近于原本反射光线的方向时,镜面高光就会越强。
现在,不论观察者向哪个方向看,半程向量与表面法线之间的夹角都不会超过90度(除非光源在表面以下)。它产生的效果会与冯氏光照有些许不同,但是大部分情况下看起来会更自然一点,特别是低高光的区域。Blinn-Phong 着色模型正是早期固定渲染管线时代时 OpenGL 所采用的光照模型。
翻译成GLSL代码如下:
vec3 lightDir = normalize(lightPos - FragPos);
vec3 viewDir = normalize(viewPos - FragPos);
vec3 halfwayDir = normalize(lightDir + viewDir);
接下来,镜面光分量的实际计算只不过是对表面法线和半程向量进行一次约束点乘(Clamped Dot Product),让点乘结果不为负,从而获取它们之间夹角的余弦值,之后我们对这个值取反光度次方:
float spec = pow(max(dot(normal, halfwayDir), 0.0), shininess);
vec3 specular = lightColor * spec;
除此之外Blinn-Phong模型就没什么好说的了,Blinn-Phong与冯氏模型唯一的区别就是,Blinn-Phong测量的是法线与半程向量之间的夹角,而冯氏模型测量的是观察方向与反射向量间的夹角。
在引入半程向量之后,我们现在应该就不会再看到冯氏光照中高光断层的情况了。
除此之外,冯氏模型与Blinn-Phong模型也有一些细微的差别:半程向量与表面法线的夹角通常会小于观察与反射向量的夹角。所以,如果你想获得和冯氏着色类似的效果,就必须在使用Blinn-Phong模型时将镜面反光度设置更高一点。通常我们会选择冯氏着色时反光度分量的2到4倍。
Gamma校正
当我们计算出场景中所有像素的最终颜色以后,我们就必须把它们显示在监视器上。过去,大多数监视器是阴极射线管显示器(CRT)。这些监视器有一个物理特性就是两倍的输入电压产生的不是两倍的亮度。输入电压产生约为输入电压的2.2次幂的亮度,这叫做监视器Gamma。
Gamma也叫灰度系数,每种显示设备都有自己的Gamma值,都不相同,有一个公式:设备输出亮度 = 电压的Gamma次幂,任何设备Gamma基本上都不会等于1,等于1是一种理想的线性状态,这种理想状态是:如果电压和亮度都是在0到1的区间,那么多少电压就等于多少亮度。对于CRT,Gamma通常为2.2,因而,输出亮度 = 输入电压的2.2次幂,你可以从本节第二张图中看到Gamma2.2实际显示出来的总会比预期暗,相反Gamma0.45就会比理想预期亮,如果你将Gamma0.45叠加到Gamma2.2的显示设备上,便会对偏暗的显示效果做到校正,这个简单的思路就是本节的核心
人类所感知的亮度恰好和CRT所显示出来相似的指数关系非常匹配。为了更好的理解所有含义,请看下面的图片:

第一行是人眼所感知到的正常的灰阶,亮度要增加一倍(比如从0.1到0.2)你才会感觉比原来变亮了一倍(译注:我们在看颜色值从0到1(从黑到白)的过程中,亮度要增加一倍,我们才会感受到明显的颜色变化(变亮一倍)。打个比方:颜色值从0.1到0.2,我们会感受到一倍的颜色变化,而从0.4到0.8我们才能感受到相同程度(变亮一倍)的颜色变化。如果还是不理解,可以参考知乎的答案)。然而,当我们谈论光的物理亮度,比如光源发射光子的数量的时候,底部(第二行)的灰阶显示出的才是物理世界真实的亮度。如底部的灰阶显示,亮度加倍时返回的也是真实的物理亮度(译注:这里亮度是指光子数量和正相关的亮度,即物理亮度,前面讨论的是人的感知亮度;物理亮度和感知亮度的区别在于,物理亮度基于光子数量,感知亮度基于人的感觉,比如第二个灰阶里亮度0.1的光子数量是0.2的二分之一),但是由于这与我们的眼睛感知亮度不完全一致(对比较暗的颜色变化更敏感),所以它看起来有差异。
因为人眼看到颜色的亮度更倾向于顶部的灰阶,监视器使用的也是一种指数关系(电压的2.2次幂),所以物理亮度通过监视器能够被映射到顶部的非线性亮度;因此看起来效果不错(译注:CRT亮度是是电压的2.2次幂而人眼相当于2次幂,因此CRT这个缺陷正好能满足人的需要)。
监视器的这个非线性映射的确可以让亮度在我们眼中看起来更好,但当渲染图像时,会产生一个问题:我们在应用中配置的亮度和颜色是基于监视器所看到的,这样所有的配置实际上是非线性的亮度/颜色配置。请看下图:
(也就是说,第一行是 gamma = 2.2 是显示器的 gamma 是显示器输出的效果 是符合人眼直觉的效果;第二行是 gamma = 1 是线性空间 但不符合人眼直觉)
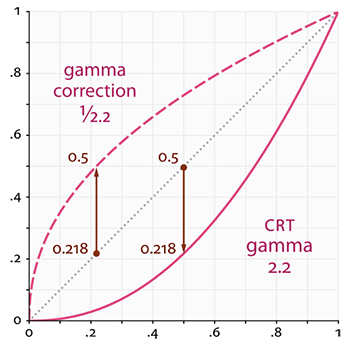
点线代表线性颜色/亮度值(译注:这表示的是理想状态,Gamma为1),实线代表监视器显示的颜色。如果我们把一个点线线性的颜色翻一倍,结果就是这个值的两倍。比如,光的颜色向量L¯=(0.5,0.0,0.0)代表的是暗红色。如果我们在线性空间中把它翻倍,就会变成(1.0,0.0,0.0),就像你在图中看到的那样。然而,由于我们定义的颜色仍然需要输出的监视器上,监视器上显示的实际颜色就会是(0.218,0.0,0.0)。在这儿问题就出现了:当我们将理想中直线上的那个暗红色翻一倍时,在监视器上实际上亮度翻了4.5倍以上!
直到现在,我们还一直假设我们所有的工作都是在线性空间中进行的(译注:Gamma为1),但最终还是要把所有的颜色输出到监视器上,所以我们配置的所有颜色和光照变量从物理角度来看都是不正确的,在我们的监视器上很少能够正确地显示。出于这个原因,我们(以及艺术家)通常将光照值设置得比本来更亮一些(由于监视器会将其亮度显示的更暗一些),如果不是这样,在线性空间里计算出来的光照就会不正确。同时,还要记住,监视器所显示出来的图像和线性图像的最小亮度是相同的,它们最大的亮度也是相同的;只是中间亮度部分会被压暗。
Gamma校正
Gamma校正(Gamma Correction)的思路是在最终的颜色输出上应用监视器Gamma的倒数。回头看前面的Gamma曲线图,你会有一个短划线,它是监视器Gamma曲线的翻转曲线。我们在颜色显示到监视器的时候把每个颜色输出都加上这个翻转的Gamma曲线,这样应用了监视器Gamma以后最终的颜色将会变为线性的。我们所得到的中间色调就会更亮,所以虽然监视器使它们变暗,但是我们又将其平衡回来了。
我们来看另一个例子。还是那个暗红色(0.5,0.0,0.0)。在将颜色显示到监视器之前,我们先对颜色应用Gamma校正曲线。线性的颜色显示在监视器上相当于降低了2.2次幂的亮度,所以倒数就是1/2.2次幂。Gamma校正后的暗红色就会成为(0.5,0.0,0.0)1/2.2=(0.5,0.0,0.0)0.45=(0.73,0.0,0.0)。校正后的颜色接着被发送给监视器,最终显示出来的颜色是(0.73,0.0,0.0)2.2=(0.5,0.0,0.0)。你会发现使用了Gamma校正,监视器最终会显示出我们在应用中设置的那种线性的颜色。
2.2通常是是大多数显示设备的大概平均gamma值。基于gamma2.2的颜色空间叫做sRGB颜色空间。每个监视器的gamma曲线都有所不同,但是gamma2.2在大多数监视器上表现都不错。出于这个原因,游戏经常都会为玩家提供改变游戏gamma设置的选项,以适应每个监视器(译注:现在Gamma2.2相当于一个标准,后文中你会看到。但现在你可能会问,前面不是说Gamma2.2看起来不是正好适合人眼么,为何还需要校正。这是因为你在程序中设置的颜色,比如光照都是基于线性Gamma,即Gamma1,所以你理想中的亮度和实际表达出的不一样,如果要表达出你理想中的亮度就要对这个光照进行校正)。
有两种在你的场景中应用gamma校正的方式:
使用OpenGL内建的sRGB帧缓冲。 自己在像素着色器中进行gamma校正。 第一个选项也许是最简单的方式,但是我们也会丧失一些控制权。开启GL_FRAMEBUFFER_SRGB,可以告诉OpenGL每个后续的绘制命令里,在颜色储存到颜色缓冲之前先校正sRGB颜色。sRGB这个颜色空间大致对应于gamma2.2,它也是家用设备的一个标准。开启GL_FRAMEBUFFER_SRGB以后,每次像素着色器运行后续帧缓冲,OpenGL将自动执行gamma校正,包括默认帧缓冲。
开启GL_FRAMEBUFFER_SRGB简单的调用glEnable就行:
glEnable(GL_FRAMEBUFFER_SRGB);
自此,你渲染的图像就被进行gamma校正处理,你不需要做任何事情硬件就帮你处理了。有时候,你应该记得这个建议:gamma校正将把线性颜色空间转变为非线性空间,所以在最后一步进行gamma校正是极其重要的。如果你在最后输出之前就进行gamma校正,所有的后续操作都是在操作不正确的颜色值。例如,如果你使用多个帧缓冲,你可能打算让两个帧缓冲之间传递的中间结果仍然保持线性空间颜色,只是给发送给监视器的最后的那个帧缓冲应用gamma校正。
(一开始我看这里被弄晕了,我还以为他说的是,gamma 校正之后,最后看到的结果,显示器上的结果的 gamma 不是 1?不是这样的,他说的是 gamma 校正的过程是像素着色器中用 0.45 处理,所以原先输入的是线性空间 gamma = 1,0.45 处理之后变成 0.45,所以像素着色器中的代码应该在 gamma = 1 的时候进行运算,而不能在 0.45 处理之后再运算)
(帧缓冲也是这样,中间的帧缓冲是线性的,运算都是在线性 gamma 上,最后再对最后的帧缓冲做 0.45 的处理)
第二个方法稍微复杂点,但同时也是我们对gamma操作有完全的控制权。我们在每个相关像素着色器运行的最后应用gamma校正,所以在发送到帧缓冲前,颜色就被校正了。
void main()
{
// do super fancy lighting
[...]
// apply gamma correction
float gamma = 2.2;
fragColor.rgb = pow(fragColor.rgb, vec3(1.0/gamma));
}
最后一行代码,将fragColor的每个颜色元素应用有一个1.0/gamma的幂运算,校正像素着色器的颜色输出。
这个方法有个问题就是为了保持一致,你必须在像素着色器里加上这个gamma校正,所以如果你有很多像素着色器,它们可能分别用于不同物体,那么你就必须在每个着色器里都加上gamma校正了。一个更简单的方案是在你的渲染循环中引入后处理阶段,在后处理四边形上应用gamma校正,这样你只要做一次就好了。
这些单行代码代表了gamma校正的实现。不太令人印象深刻,但当你进行gamma校正的时候有一些额外的事情别忘了考虑。
sRGB纹理
对线性空间作 gamma = 0.45 的校正,得到 sRGB 空间
显示器上输出的就是 0.45 * 2.2 ≈ 1
对于 sRGB 纹理,原本是 gamma = 0.45 如果在着色器中 0.45 校正一次,显示器 2.2,就会使得结果是 gamma = 0.45 就会变亮
为了解决这个问题,我们必须确保纹理艺术家在线性空间中工作。 (他这个意思应该是,sRGB 在显示器上看到的是 gamma = 1,如果我们要求文件是 gamma = 1,也就是所谓的“在线性空间中工作”,那么艺术家看到的是 gamma = 2.2)然而,由于在 sRGB 空间中工作更容易,并且大多数工具甚至不能正确支持线性纹理,因此这可能不是首选解决方案。
另一种解决方案是在对这些 sRGB 纹理的颜色值进行任何计算之前重新校正或将其转换为线性空间。 (我觉得这个意思应该是,大家都是默认 0.45 伽马校正,但是都假设输入是线性的,但是你 sRGB
是 gamma = 0.45 的,所以把你的 sRGB 作为输入的时候,我们先做 2.2 把你转换到线性空间,你才能作为我们伽马矫正工作流的输入)我们可以这样做:
float gamma = 2.2;
vec3 diffuseColor = pow(texture(diffuse, texCoords).rgb, vec3(gamma));
不过,对 sRGB 空间中的每个纹理执行此操作相当麻烦。 内部纹理格式为我们提供了另一种解决方案 幸运的是,OpenGL 通过提供GL_SRGB 和 GL_SRGB_ALPHA 。
如果我们使用这两种 sRGB 纹理格式中的任何一种在 OpenGL 中创建纹理,一旦我们使用它们,OpenGL 就会自动将颜色校正为线性空间,从而使我们能够在线性空间中正常工作。 我们可以将纹理指定为 sRGB 纹理,如下所示:
glTexImage2D(GL_TEXTURE_2D, 0, GL_SRGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
如果您还想在纹理中包含 alpha 分量,则必须将纹理的内部格式指定为 GL_SRGB_ALPHA 。
在 sRGB 空间中指定纹理时应该小心,因为并非所有纹理实际上都在 sRGB 空间中。 用于为对象着色的纹理(如漫反射纹理)几乎总是在 sRGB 空间中。 用于检索光照参数的纹理(如 镜面反射贴图 和 法线贴图 )几乎总是在线性空间中,因此如果您将它们配置为 sRGB 纹理,光照会看起来很奇怪。 请小心指定为 sRGB 的纹理。
衰减
在使用了gamma校正之后,另一个不同之处是光照衰减(Attenuation)。真实的物理世界中,光照的衰减和光源的距离的平方成反比。
float attenuation = 1.0 / (distance * distance);
然而,当我们使用这个衰减公式的时候,衰减效果总是过于强烈,光只能照亮一小圈,看起来并不真实。出于这个原因,我们使用在基本光照教程中所讨论的那种衰减方程,它给了我们更大的控制权,此外我们还可以使用双曲线函数:
float attenuation = 1.0 / distance;
双曲线比使用二次函数变体在不用gamma校正的时候看起来更真实,不过但我们开启gamma校正以后线性衰减看起来太弱了,符合物理的二次函数突然出现了更好的效果。下图显示了其中的不同:

这种差异产生的原因是,光的衰减方程改变了亮度值,而且屏幕上显示出来的也不是线性空间,在监视器上效果最好的衰减方程,并不是符合物理的。想想平方衰减方程,如果我们使用这个方程,而且不进行gamma校正,显示在监视器上的衰减方程实际上将变成 (1.0/distance^2)^2.2 。若不进行gamma校正,将产生更强烈的衰减。这也解释了为什么双曲线不用gamma校正时看起来更真实,因为它实际变成了 (1.0/distance)^2.2=1.0/distance^2.2。这和物理公式是很相似的。
我们在基础光照教程中讨论的更高级的那个衰减方程在有gamma校正的场景中也仍然有用,因为它可以让我们对衰减拥有更多准确的控制权(不过,在进行gamma校正的场景中当然需要不同的参数)。
总而言之,gamma校正使你可以在线性空间中进行操作。因为线性空间更符合物理世界,大多数物理公式现在都可以获得较好效果,比如真实的光的衰减。你的光照越真实,使用gamma校正获得漂亮的效果就越容易。这也正是为什么当引进gamma校正时,建议只去调整光照参数的原因。
阴影
阴影映射
每个物体有自己的 M 矩阵,使用从光源的角度看的 VP 矩阵,这个 VP 矩阵合为一个 T 矩阵,这个 T 矩阵使得每个物体(或者说每一个三维坐标)变到光源的可见空间中,可以渲染出一个阴影贴图
而从观察者(摄像机)看到的场景中,我也可以知道这个场景中的三维坐标,对这个三维坐标做 T 变换,可以得到这个三维坐标在光源的可见空间中的位置,也就得到了他在阴影贴图上的位置,就可以查询这个点是否在阴影中
具体步骤:
使用 glGenFramebuffers 创建深度缓冲
GLuint depthMapFBO;
glGenFramebuffers(1, &depthMapFBO);
使用 glGenTextures 创建纹理 id,glBindTexture 将纹理 id 绑定到目标点,glTexImage2D 对目标点上绑定的纹理 id 生成纹理,glTexParameteri 配置目标点上的纹理的属性
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024;
GLuint depthMap;
glGenTextures(1, &depthMap);
glBindTexture(GL_TEXTURE_2D, depthMap);
glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT,
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
前后使用 glBindFramebuffer 形成深度缓冲的作用域,使用 glFramebufferTexture2D 将创建的深度纹理绑定到深度缓冲
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, depthMap, 0);
glDrawBuffer(GL_NONE);
glReadBuffer(GL_NONE);
glBindFramebuffer(GL_FRAMEBUFFER, 0);
我们需要的只是在从光的透视图下渲染场景的时候深度信息,所以颜色缓冲没有用。然而,不包含颜色缓冲的帧缓冲对象是不完整的,所以我们需要显式告诉OpenGL我们不适用任何颜色数据进行渲染。我们通过将调用glDrawBuffer和glReadBuffer把读和绘制缓冲设置为GL_NONE来做这件事。
合理配置将深度值渲染到纹理的帧缓冲后,我们就可以开始第一步了:生成深度贴图。两个步骤的完整的渲染阶段,看起来有点像这样:
// 1. 首选渲染深度贴图
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT);
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
glClear(GL_DEPTH_BUFFER_BIT);
ConfigureShaderAndMatrices();
RenderScene();
glBindFramebuffer(GL_FRAMEBUFFER, 0);
// 2. 像往常一样渲染场景,但这次使用深度贴图
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
ConfigureShaderAndMatrices();
glBindTexture(GL_TEXTURE_2D, depthMap);
RenderScene();
这段代码隐去了一些细节,但它表达了阴影映射的基本思路。这里一定要记得调用glViewport。因为阴影贴图经常和我们原来渲染的场景(通常是窗口分辨率)有着不同的分辨率,我们需要改变视口(viewport)的参数以适应阴影贴图的尺寸。如果我们忘了更新视口参数,最后的深度贴图要么太小要么就不完整。
之后的……看原文吧
之后要解决阴影失真问题,通过对阴影贴图得到的深度给予一个偏移量来解决,偏移量是基于表面法线和光照方向的。这样像地板这样的表面几乎与光源垂直,得到的偏移就很小,而比如立方体的侧面这种表面得到的偏移就更大。
使用阴影偏移的一个缺点是你对物体的实际深度应用了平移。偏移有可能足够大,以至于可以看出阴影相对实际物体位置的偏移。
我们可以使用一个叫技巧解决大部分的Peter panning问题:当渲染深度贴图时候使用正面剔除(front face culling)你也许记得在面剔除教程中OpenGL默认是背面剔除。我们要告诉OpenGL我们要剔除正面。
因为我们只需要深度贴图的深度值,对于实体物体无论我们用它们的正面还是背面都没问题。使用背面深度不会有错误,因为阴影在物体内部有错误我们也看不见。
但这只对内部不会对外开口的实体物体有效。我们的场景中,在立方体上工作的很好,但在地板上无效,因为正面剔除完全移除了地板。地面是一个单独的平面,不会被完全剔除。如果有人打算使用这个技巧解决peter panning必须考虑到只有剔除物体的正面才有意义。
另一个要考虑到的地方是接近阴影的物体仍然会出现不正确的效果。必须考虑到何时使用正面剔除对物体才有意义。不过使用普通的偏移值通常就能避免peter panning。
光的视锥不可见的区域一律被认为是处于阴影中,不管它真的处于阴影之中。出现这个状况是因为超出光的视锥的投影坐标比1.0大,这样采样的深度纹理就会超出他默认的0到1的范围。根据纹理环绕方式,我们将会得到不正确的深度结果,它不是基于真实的来自光源的深度值。
我们宁可让所有超出深度贴图的坐标的深度范围是1.0,这样超出的坐标将永远不在阴影之中。我们可以储存一个边框颜色,然后把深度贴图的纹理环绕选项设置为GL_CLAMP_TO_BORDER:
现在如果我们采样深度贴图0到1坐标范围以外的区域,纹理函数总会返回一个1.0的深度值,阴影值为0.0。结果看起来会更真实
仍有一部分是黑暗区域。那里的坐标超出了光的正交视锥的远平面。你可以看到这片黑色区域总是出现在光源视锥的极远处。
当一个点比光的远平面还要远时,它的投影坐标的z坐标大于1.0。这种情况下,GL_CLAMP_TO_BORDER环绕方式不起作用,因为我们把坐标的z元素和深度贴图的值进行了对比;它总是为大于1.0的z返回true。
解决这个问题也很简单,只要投影向量的z坐标大于1.0,我们就把shadow的值强制设为0.0:
阴影现在已经附着到场景中了,不过这仍不是我们想要的。如果你放大看阴影,阴影映射对分辨率的依赖很快变得很明显。
因为深度贴图有一个固定的分辨率,多个片段对应于一个纹理像素。结果就是多个片段会从深度贴图的同一个深度值进行采样,这几个片段便得到的是同一个阴影,这就会产生锯齿边。
你可以通过增加深度贴图的分辨率的方式来降低锯齿块,也可以尝试尽可能的让光的视锥接近场景。
另一个(并不完整的)解决方案叫做PCF(percentage-closer filtering),这是一种多个不同过滤方式的组合,它产生柔和阴影,使它们出现更少的锯齿块和硬边。核心思想是从深度贴图中多次采样,每一次采样的纹理坐标都稍有不同。每个独立的样本可能在也可能不再阴影中。所有的次生结果接着结合在一起,进行平均化,我们就得到了柔和阴影。
一个简单的PCF的实现是简单的从纹理像素四周对深度贴图采样,然后把结果平均起来:
如果投影使用透视矩阵,那么还要把非线性深度映射回线性深度
点阴影
方向光源 2d深度纹理作为阴影纹理
点光源 立方体阴影纹理
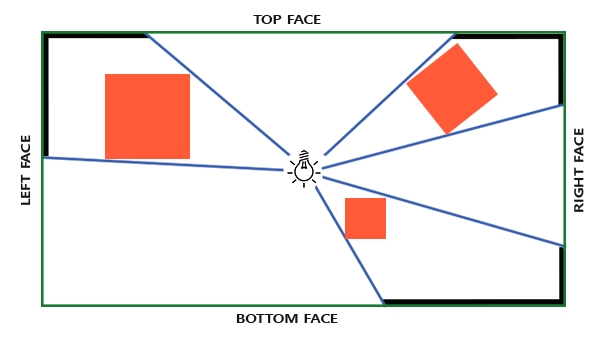
几何着色器中有内置的变量 gl_Layer 配合立方体纹理,不知道的人可能会很蒙,因为渲染深度缓冲的着色器中完全没看到立方体纹理
法线贴图
用法线贴图记录物体表面的法线方向
但是记录的都是以纹理为平面建立局部坐标系的,(0,0,1) 为表面的法向量,垂直于纹理,所以最终记录到的法线都在 (0,0,1) 附近,所以法线贴图的颜色偏蓝
但是这只是局部坐标系的,并不是世界坐标系下的,所以还要转换
如果不记录局部坐标系的坐标,就记录世界坐标系下的法线方向,那么这里记录到的结果就和模型朝向绑定了,如果模型旋转了,还要对所有法向旋转
这个局部坐标系更清楚地来说就是切线空间
从一个坐标系变换到另一个坐标系的矩阵很容易写,把旧坐标系的基向量用新坐标系的基向量表示,按列写,按列排列,得到的矩阵就是了
T B N
Tx Bx Nx
Ty By Ny
Tz Tz Tz
TBN 矩阵这三个字母分别代表 tangent、bitangent 和 normal 向量,对应世界中的 xyz
TBN 切线空间 -> 世界
TBN 的逆 世界 -> 切线空间
TBN 正交矩阵(每个轴既是单位向量同时相互垂直)的一大属性是一个正交矩阵的置换矩阵与它的逆矩阵相等。这个属性很重要因为逆矩阵的求得比求置换开销大;
T 不是随便选一个三角形的边就可以了,而是 U 坐标系的方向
三角形的两个边可以得到世界坐标中的向量,这两个向量可以表示为 T B 矩阵为基的形式,所以可以解得 T B 基向量
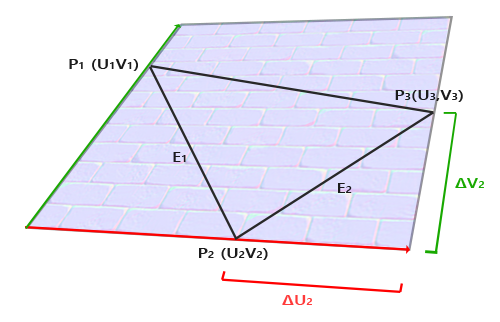

然后 N 这个法向量一叉乘就得到了
或者不用算 B,只用算 T,N 直接就从三角形的两个边代表的向量叉乘得到,然后 N 叉乘 T 得到 B
TBN 有两种用法,一种是用 TBN 将从法线贴图采样到的法线从切线空间转化到世界空间,一种是用 TBN 的逆将其他参与光照计算的世界空间中的向量转化到切线空间,与 TBN 统一
第一种方法需要在片元着色器中进行 TBN 的矩阵乘法,而第二种方法需要在顶点着色器中进行 TBN 的逆的矩阵乘法,然后把与光照有关的,切线空间中的向量,由 OpenGL 插值,传入片元着色器
一般顶点比片元少,所以在顶点着色器中进行 TBN 的逆的矩阵乘法更好
(不知道在顶点数量很多的时候,将 nanite 那种,会不会不一样?)
关于法线贴图还有最后一个技巧要讨论,它可以在不必花费太多性能开销的情况下稍稍提升画质表现。
当在更大的网格上计算切线向量的时候,它们往往有很大数量的共享顶点,当法向贴图应用到这些表面时将切线向量平均化通常能获得更好更平滑的结果。这样做有个问题,就是TBN向量可能会不能互相垂直,这意味着TBN矩阵不再是正交矩阵了。法线贴图可能会稍稍偏移,但这仍然可以改进。
使用叫做格拉姆-施密特正交化过程(Gram-Schmidt process)的数学技巧,我们可以对TBN向量进行重正交化,这样每个向量就又会重新垂直了。在顶点着色器中我们这样做:
vec3 T = normalize(vec3(model * vec4(tangent, 0.0)));
vec3 N = normalize(vec3(model * vec4(normal, 0.0)));
// re-orthogonalize T with respect to N
T = normalize(T - dot(T, N) * N);
// then retrieve perpendicular vector B with the cross product of T and N
vec3 B = cross(T, N);
mat3 TBN = mat3(T, B, N)
视差贴图
视差贴图背后的思想是修改纹理坐标使一个fragment的表面看起来比实际的更高或者更低,所有这些都根据观察方向和高度贴图。
这里粗糙的红线代表高度贴图中的数值的立体表达,向量V¯代表观察方向。如果平面进行实际位移,观察者会在点B看到表面。然而我们的平面没有实际上进行位移,观察方向将在点A与平面接触。视差贴图的目的是,在A位置上的fragment不再使用点A的纹理坐标而是使用点B的。随后我们用点B的纹理坐标采样,观察者就像看到了点B一样。
这个技巧就是描述如何从点A得到点B的纹理坐标。视差贴图尝试通过对从fragment到观察者的方向向量V¯进行缩放的方式解决这个问题,缩放的大小是A处fragment的高度。所以我们将V¯的长度缩放为高度贴图在点A处H(A)采样得来的值。下图展示了经缩放得到的向量P¯:
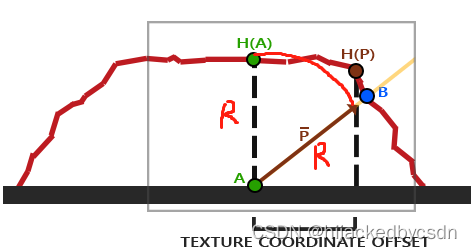
我们随后选出P¯以及这个向量与平面对齐的坐标作为纹理坐标的偏移量。这能工作是因为向量P¯是使用从高度贴图得到的高度值计算出来的,所以一个fragment的高度越高位移的量越大。
这个技巧在大多数时候都没问题,但点B是粗略估算得到的。当表面的高度变化很快的时候,看起来就不会真实,因为向量P¯最终不会和B接近,就像下图这样:
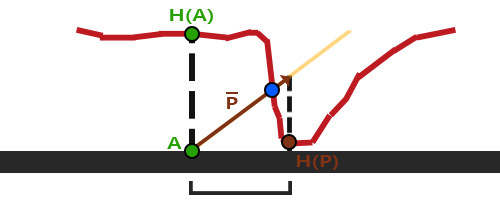
其实就是,已知 view_dir,也已知着色点 A 的位置(纹理坐标),现在采样到 A 点在高度贴图上的值为 H(A),于是从 A 出发沿着 -view_dir 的方向走 H(A) 的距离,走到了 P 点,然后取 P 点在纹理平面上的投影的纹理坐标
图中的 H§ 是算法实际取到的高度,点 B 所在的位置是理论上应该取到的高度,而算法的输出是 P 的投影点的纹理坐标
为了方便,这些运算在切线空间中完成
光照在片元中完成,所以根据高度贴图取伪高度下的纹理坐标也是在片元中
陡峭视差映射
之前的视差映射对 P 向量的做法是
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir)
{
float height = texture(depthMap, texCoords).r;
vec2 p = viewDir.xy / viewDir.z * (height * height_scale);
return texCoords - p;
}
也就是 height 这个变量是 H(A) 其他的,比如 viewDir.xy 的长度不等于 1,/ viewDir.z 之后也不一定等于 1,乘了 height_scale 之后也不一定等于 1
从深度图中采样的,某一个通道的值是在 0 到 1 之间,那么也就是深度在 0 到 1 之间,我们把 0 到 1 分成若干层
陡峭视差映射的基本思想是将总深度范围划分为同一个深度/高度的多个层。从每个层中我们沿着P¯方向移动采样纹理坐标,直到我们找到一个采样低于当前层的深度值。
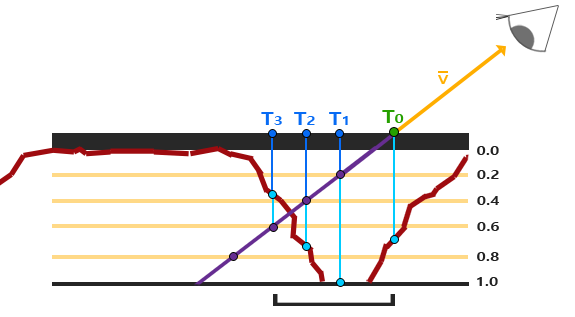
我们从上到下遍历深度层,我们把每个深度层和储存在深度贴图中的它的深度值进行对比。如果这个层的深度值小于深度贴图的值,就意味着这一层的P¯
向量部分在表面之下。我们继续这个处理过程直到有一层的深度高于储存在深度贴图中的值:这个点就在(经过位移的)表面下方。
这个例子中我们可以看到第二层(D(2) = 0.73)的深度贴图的值仍低于第二层的深度值0.4,所以我们继续。下一次迭代,这一层的深度值0.6大于深度贴图中采样的深度值(D(3) = 0.37)。我们便可以假设第三层向量P¯是可用的位移几何位置。我们可以用从向量P3¯的纹理坐标偏移T3来对fragment的纹理坐标进行位移。你可以看到随着深度曾的增加精确度也在提高。
为实现这个技术,我们只需要改变ParallaxMapping函数,因为所有需要的变量都有了:
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir)
{
// number of depth layers
const float numLayers = 10;
// calculate the size of each layer
float layerDepth = 1.0 / numLayers;
// depth of current layer
float currentLayerDepth = 0.0;
// the amount to shift the texture coordinates per layer (from vector P)
vec2 P = viewDir.xy * height_scale;
vec2 deltaTexCoords = P / numLayers;
[...]
}
我们先定义层的数量,计算每一层的深度,最后计算纹理坐标偏移,每一层我们必须沿着P¯的方向进行移动。
然后我们遍历所有层,从上开始,知道找到小于这一层的深度值的深度贴图值:
// get initial values
vec2 currentTexCoords = texCoords;
float currentDepthMapValue = texture(depthMap, currentTexCoords).r;
while(currentLayerDepth < currentDepthMapValue)
{
// shift texture coordinates along direction of P
currentTexCoords -= deltaTexCoords;
// get depthmap value at current texture coordinates
currentDepthMapValue = texture(depthMap, currentTexCoords).r;
// get depth of next layer
currentLayerDepth += layerDepth;
}
return currentTexCoords;
这里我们循环每一层深度,直到沿着P¯
向量找到第一个返回低于(位移)表面的深度的纹理坐标偏移量。从fragment的纹理坐标减去最后的偏移量,来得到最终的经过位移的纹理坐标向量,这次就比传统的视差映射更精确了。
当垂直看一个表面的时候纹理时位移比以一定角度看时的小。我们可以在垂直看时使用更少的样本,以一定角度看时增加样本数量:
const float minLayers = 8;
const float maxLayers = 32;
float numLayers = mix(maxLayers, minLayers, abs(dot(vec3(0.0, 0.0, 1.0), viewDir)));
这里我们得到viewDir和正z方向的点乘,使用它的结果根据我们看向表面的角度调整样本数量(注意正z方向等于切线空间中的表面的法线)。如果我们所看的方向平行于表面,我们就是用32层。
陡峭视差贴图同样有自己的问题。因为这个技术是基于有限的样本数量的,我们会遇到锯齿效果以及图层之间有明显的断层
视差遮蔽映射
视差遮蔽映射(Parallax Occlusion Mapping)和陡峭视差映射的原则相同,但不是用触碰的第一个深度层的纹理坐标,而是在触碰之前和之后,在深度层之间进行线性插值。我们根据表面的高度距离啷个深度层的深度层值的距离来确定线性插值的大小。看看下面的图片就能了解它是如何工作的:
你可以看到大部分和陡峭视差映射一样,不一样的地方是有个额外的步骤,两个深度层的纹理坐标围绕着交叉点的线性插值。这也是近似的,但是比陡峭视差映射更精确。
视差遮蔽映射的代码基于陡峭视差映射,所以并不难:
[...] // steep parallax mapping code here
// get texture coordinates before collision (reverse operations)
vec2 prevTexCoords = currentTexCoords + deltaTexCoords;
// get depth after and before collision for linear interpolation
float afterDepth = currentDepthMapValue - currentLayerDepth;
float beforeDepth = texture(depthMap, prevTexCoords).r - currentLayerDepth + layerDepth;
// interpolation of texture coordinates
float weight = afterDepth / (afterDepth - beforeDepth);
vec2 finalTexCoords = prevTexCoords * weight + currentTexCoords * (1.0 - weight);
return finalTexCoords;
在对(位移的)表面几何进行交叉,找到深度层之后,我们获取交叉前的纹理坐标。然后我们计算来自相应深度层的几何之间的深度之间的距离,并在两个值之间进行插值。线性插值的方式是在两个层的纹理坐标之间进行的基础插值。函数最后返回最终的经过插值的纹理坐标。
视差遮蔽映射的效果非常好,尽管有一些可以看到的轻微的不真实和锯齿的问题,这仍是一个好交易,因为除非是放得非常大或者观察角度特别陡,否则也看不到。
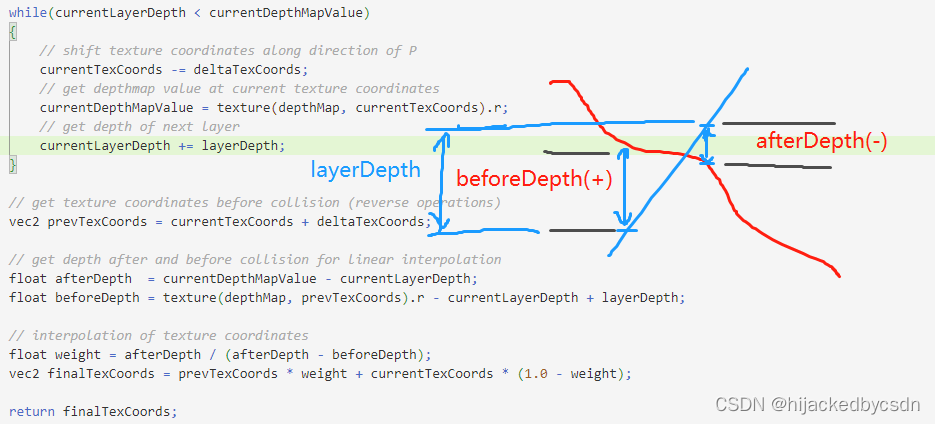
他这个会有正负号,但是最终还是会算出来 weight 是那种 a/(a+b) 的形式的,如果有负号,会是上下都能提一个负号出来
视差贴图是提升场景细节非常好的技术,但是使用的时候还是要考虑到它会带来一点不自然。大多数时候视差贴图用在地面和墙壁表面,这种情况下查明表面的轮廓并不容易,同时观察角度往往趋向于垂直于表面。这样视差贴图的不自然也就很难能被注意到了,对于提升物体的细节可以祈祷难以置信的效果。
HDR
转换HDR值到LDR值得过程叫做色调映射(Tone Mapping),现在现存有很多的色调映射算法,这些算法致力于在转换过程中保留尽可能多的HDR细节。这些色调映射算法经常会包含一个选择性倾向黑暗或者明亮区域的参数。
在实时渲染中,HDR不仅允许我们超过LDR的范围[0.0, 1.0]与保留更多的细节,同时还让我们能够根据光源的真实强度指定它的强度。比如太阳有比闪光灯之类的东西更高的强度,那么我们为什么不这样子设置呢?(比如说设置一个10.0的漫亮度) 这允许我们用更现实的光照参数恰当地配置一个场景的光照,而这在LDR渲染中是不能实现的,因为他们会被上限约束在1.0。
因为显示器只能显示在0.0到1.0范围之内的颜色,我们肯定要做一些转换从而使得当前的HDR颜色值符合显示器的范围。简单地取平均值重新转换这些颜色值并不能很好的解决这个问题,因为明亮的地方会显得更加显著。我们能做的是用一个不同的方程与/或曲线来转换这些HDR值到LDR值,从而给我们对于场景的亮度完全掌控,这就是之前说的色调变换,也是HDR渲染的最终步骤。
浮点帧缓冲
在实现HDR渲染之前,我们首先需要一些防止颜色值在每一个片段着色器运行后被限制约束的方法。当帧缓冲使用了一个标准化的定点格式(像GL_RGB)为其颜色缓冲的内部格式,OpenGL会在将这些值存入帧缓冲前自动将其约束到0.0到1.0之间。这一操作对大部分帧缓冲格式都是成立的,除了专门用来存放被拓展范围值的浮点格式。
当一个帧缓冲的颜色缓冲的内部格式被设定成了GL_RGB16F, GL_RGBA16F, GL_RGB32F 或者GL_RGBA32F时,这些帧缓冲被叫做浮点帧缓冲(Floating Point Framebuffer),浮点帧缓冲可以存储超过0.0到1.0范围的浮点值,所以非常适合HDR渲染。
想要创建一个浮点帧缓冲,我们只需要改变颜色缓冲的内部格式参数就行了(注意GL_FLOAT参数):
glBindTexture(GL_TEXTURE_2D, colorBuffer);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGB, GL_FLOAT, NULL);
默认的帧缓冲默认一个颜色分量只占用8位(bits)。当使用一个使用32位每颜色分量的浮点帧缓冲时(使用GL_RGB32F 或者GL_RGBA32F),我们需要四倍的内存来存储这些颜色。所以除非你需要一个非常高的精确度,32位不是必须的,使用GLRGB16F就足够了。
这个浮点帧缓冲用 phong shading,然后把这个浮点帧缓冲的颜色纹理附件,作为主帧缓冲的着色程序的 sampler2D,采样,采样得到的会是超过 0 到 1 的
但是即使传到 FragColor 是超过 0 到 1 的,也会钳制到 0 到 1,所以要用一个映射
Reinhard 色调映射是 x’ = x/(x+1)
曝光色调映射是 x’ = 1 - exp(-x*exposure)
HDR图片包含在不同曝光等级的细节。如果我们有一个场景要展现日夜交替,我们当然会在白天使用低曝光,在夜间使用高曝光,就像人眼调节方式一样。有了这个曝光参数,我们可以去设置可以同时在白天和夜晚不同光照条件工作的光照参数,我们只需要调整曝光参数就行了。
高曝光值会使隧道的黑暗部分显示更多的细节,然而低曝光值会显著减少黑暗区域的细节,但允许我们看到更多明亮区域的细节。下面这组图片展示了在不同曝光值下的通道:
HDR拓展
在这里展示的两个色调映射算法仅仅是大量(更先进)的色调映射算法中的一小部分,这些算法各有长短。一些色调映射算法倾向于特定的某种颜色/强度,也有一些算法同时显示低高曝光颜色从而能够显示更加多彩和精细的图像。也有一些技巧被称作自动曝光调整(Automatic Exposure Adjustment)或者叫人眼适应(Eye Adaptation)技术,它能够检测前一帧场景的亮度并且缓慢调整曝光参数模仿人眼使得场景在黑暗区域逐渐变亮或者在明亮区域逐渐变暗。
HDR渲染的真正优点在庞大和复杂的场景中应用复杂光照算法会被显示出来,但是出于教学目的创建这样复杂的演示场景是很困难的,这个教程用的场景是很小的,而且缺乏细节。但是如此简单的演示也是能够显示出HDR渲染的一些优点:在明亮和黑暗区域无细节损失,因为它们可以通过色调映射重新获得;多个光照的叠加不会导致亮度被截断的区域的出现,光照可以被设定为它们原来的亮度值而不是被LDR值限制。而且,HDR渲染也使一些有趣的效果更加可行和真实; 其中一个效果叫做泛光(Bloom),我们将在下一节讨论。
https://gamedev.stackexchange.com/questions/62836/does-hdr-rendering-have-any-benefits-if-bloom-wont-be-applied
如果泛光效果不被应用HDR渲染还有好处吗?: 一个StackExchange问题,其中有一个答案非常详细地解释HDR渲染的好处。
Bloom
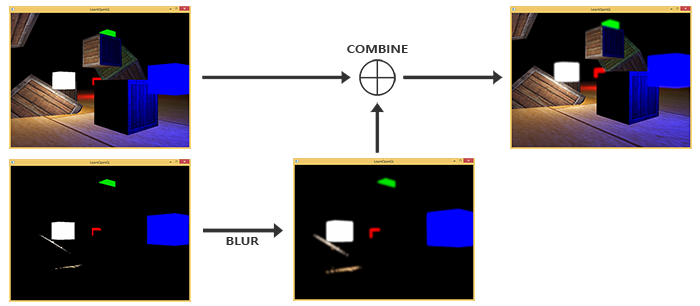
将场景渲染到两个帧缓冲
其中一个帧缓冲提取出亮度超过一定阈值的颜色,模糊
最后两个帧缓冲的颜色加在一起
泛光本身并不是个复杂的技术,但很难获得正确的效果。它的品质很大程度上取决于所用的模糊过滤器的质量和类型。简单地改改模糊过滤器就会极大的改变泛光效果的品质。
提取亮色
可以输出到两个不同的帧缓冲
也可以用另外一种方法,就是在片元着色器中指定多个输出,它们 layout 不同
这需要帧缓冲绑定了多个颜色附件,也就是 GL_COLOR_ATTACHMENT0 GL_COLOR_ATTACHMENT1
高斯模糊
高斯曲线在它的中间处的面积最大,使用它的值作为权重使得近处的样本拥有最大的优先权。比如,如果我们从fragment的32×32的四方形区域采样,这个权重随着和fragment的距离变大逐渐减小;通常这会得到更好更真实的模糊效果,这种模糊叫做高斯模糊。
要实现高斯模糊过滤我们需要一个二维四方形作为权重,从这个二维高斯曲线方程中去获取它。然而这个过程有个问题,就是很快会消耗极大的性能。以一个32×32的模糊kernel为例,我们必须对每个fragment从一个纹理中采样1024次!
幸运的是,高斯方程有个非常巧妙的特性,它允许我们把二维方程分解为两个更小的方程:一个描述水平权重,另一个描述垂直权重。我们首先用水平权重在整个纹理上进行水平模糊,然后在经改变的纹理上进行垂直模糊。利用这个特性,结果是一样的,但是可以节省难以置信的性能,因为我们现在只需做32+32次采样,不再是1024了!这叫做两步高斯模糊。
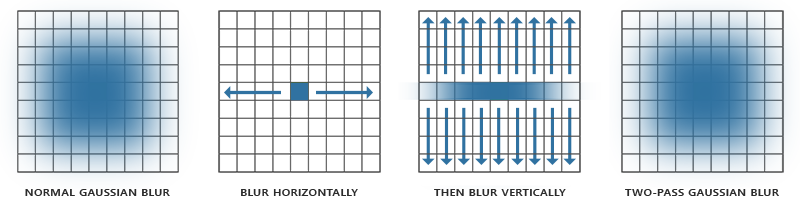
高斯模糊的片元着色器
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D image;
uniform bool horizontal;
uniform float weight[5] = float[] (0.2270270270, 0.1945945946, 0.1216216216, 0.0540540541, 0.0162162162);
void main()
{
vec2 tex_offset = 1.0 / textureSize(image, 0); // gets size of single texel
vec3 result = texture(image, TexCoords).rgb * weight[0];
if(horizontal)
{
for(int i = 1; i < 5; ++i)
{
result += texture(image, TexCoords + vec2(tex_offset.x * i, 0.0)).rgb * weight[i];
result += texture(image, TexCoords - vec2(tex_offset.x * i, 0.0)).rgb * weight[i];
}
}
else
{
for(int i = 1; i < 5; ++i)
{
result += texture(image, TexCoords + vec2(0.0, tex_offset.y * i)).rgb * weight[i];
result += texture(image, TexCoords - vec2(0.0, tex_offset.y * i)).rgb * weight[i];
}
}
FragColor = vec4(result, 1.0);
}
需要两个帧缓冲,A 的输出(颜色纹理附件)作为 B 的输入(sampler2D),B 的输入(颜色纹理附件)作为 A 的输出(sampler2D)才能完成这个操作。因为如果只有一个帧缓冲,想要把自己的颜色纹理附件作为自己的 sampler2D 的话,那就是着色器在同时读取和写入同一个纹理,会导致未定义的行为,所以不可取
所以一定要有两个帧缓冲互传结果,称为 pingpong 帧缓冲
那么就可以约定其中一个帧缓冲负责水平,一个负责竖直
对非整数纹理坐标采样,利用 GPU 双线性插值
根据 https://www.rastergrid.com/blog/2010/09/efficient-gaussian-blur-with-linear-sampling/
普通的 Blur 代码没有利用 GPU 的优势
GPU 的双线性纹理插值几乎没有成本(我还是第一次知道这事)
所以原先我们在中心选取了一个点,在一翼上选取了四个点,一次对一个方向采样,总共是 9 次
现在我们对中心点的采样依旧,但是对一翼上的四个点,每两个点之间取一个点,就变成了一翼上两个点,一个方向总共采样 5 次
偏移量为 1 2 的点之间取一个点,3 4 的点之间取一个点
既然是线性插值,那么采样点的偏移量也要线性插值
w e i g h t = w e i g h t 1 + w e i g h t 2 weight = weight_1 + weight_2 weight=weight1+weight2
o f f s e t = ( o f f s e t 1 ∗ w e i g h t 1 + o f f s e t 2 ∗ w e i g h t 2 ) / ( w e i g h t 1 + w e i g h t 2 ) offset = (offset_1 * weight_1 + offset_2 * weight_2)/(weight_1 + weight_2) offset=(offset1∗weight1+offset2∗weight2)/(weight1+weight2)
(0.1945945946 * 1 + 0.1216216216 * 2)/(0.1945945946 + 0.1216216216) = 1.384615384567
(0.0540540541 * 3 + 0.0162162162 * 4)/(0.0540540541 + 0.0162162162) = 3.230769230441
修改之后
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D image;
uniform bool horizontal;
uniform float offset[3] = float[](0.0, 1.3846153846, 3.2307692308);
uniform float weight[3] = float[](0.2270270270, 0.3162162162, 0.0702702703);
void main()
{
vec2 delta_tex_coord = 1.0 / textureSize(image, 0); // gets size of single texel
vec3 result = texture(image, TexCoords).rgb * weight[0];
if(horizontal)
{
for(int i = 1; i < 3; ++i)
{
result += texture(image, TexCoords + vec2(delta_tex_coord.x * offset[i], 0.0)).rgb * weight[i];
result += texture(image, TexCoords - vec2(delta_tex_coord.x * offset[i], 0.0)).rgb * weight[i];
}
}
else
{
for(int i = 1; i < 3; ++i)
{
result += texture(image, TexCoords + vec2(0.0, delta_tex_coord.y * offset[i])).rgb * weight[i];
result += texture(image, TexCoords - vec2(0.0, delta_tex_coord.y * offset[i])).rgb * weight[i];
}
}
FragColor = vec4(result, 1.0);
}
修改之前:
修改之后:
效果是差不多的
延迟光照
延迟着色法基于我们延迟(Defer)或推迟(Postpone)大部分计算量非常大的渲染(像是光照)到后期进行处理的想法。它包含两个处理阶段(Pass):在第一个几何处理阶段(Geometry Pass)中,我们先渲染场景一次,之后获取对象的各种几何信息,并储存在一系列叫做G缓冲(G-buffer)的纹理中;想想位置向量(Position Vector)、颜色向量(Color Vector)、法向量(Normal Vector)和/或镜面值(Specular Value)。场景中这些储存在G缓冲中的几何信息将会在之后用来做(更复杂的)光照计算。
我们会在第二个光照处理阶段(Lighting Pass)中使用G缓冲内的纹理数据。在光照处理阶段中,我们渲染一个屏幕大小的方形,并使用G缓冲中的几何数据对每一个片段计算场景的光照;在每个像素中我们都会对G缓冲进行迭代。我们对于渲染过程进行解耦,将它高级的片段处理挪到后期进行,而不是直接将每个对象从顶点着色器带到片段着色器。光照计算过程还是和我们以前一样,但是现在我们需要从对应的G缓冲而不是顶点着色器(和一些uniform变量)那里获取输入变量了。
这种渲染方法一个很大的好处就是能保证在G缓冲中的片段和在屏幕上呈现的像素所包含的片段信息是一样的,因为深度测试已经最终将这里的片段信息作为最顶层的片段。这样保证了对于在光照处理阶段中处理的每一个像素都只处理一次,所以我们能够省下很多无用的渲染调用。除此之外,延迟渲染还允许我们做更多的优化,从而渲染更多的光源。
当然这种方法也带来几个缺陷, 由于G缓冲要求我们在纹理颜色缓冲中存储相对比较大的场景数据,这会消耗比较多的显存,尤其是类似位置向量之类的需要高精度的场景数据。 另外一个缺点就是他不支持混色(因为我们只有最前面的片段信息), 因此也不能使用MSAA了。针对这几个问题我们可以做一些变通来克服这些缺点,这些我们留会在教程的最后讨论。
在几何处理阶段中填充G缓冲非常高效,因为我们直接储存像素位置,颜色或者是法线等对象信息到帧缓冲中,而这几乎不会消耗处理时间。在此基础上使用多渲染目标(Multiple Render Targets, MRT)技术,我们甚至可以在一个渲染处理之内完成这所有的工作。
过程:
while(...) // 游戏循环
{
// 1. 几何处理阶段:渲染所有的几何/颜色数据到G缓冲
glBindFramebuffer(GL_FRAMEBUFFER, gBuffer);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
gBufferShader.Use();
for(Object obj : Objects)
{
ConfigureShaderTransformsAndUniforms();
obj.Draw();
}
// 2. 光照处理阶段:使用G缓冲计算场景的光照
glBindFramebuffer(GL_FRAMEBUFFER, 0);
glClear(GL_COLOR_BUFFER_BIT);
lightingPassShader.Use();
BindAllGBufferTextures();
SetLightingUniforms();
RenderQuad();
}
延迟着色法的其中一个缺点就是它不能进行混合(Blending),因为G缓冲中所有的数据都是从一个单独的片段中来的,而混合需要对多个片段的组合进行操作。延迟着色法另外一个缺点就是它迫使你对大部分场景的光照使用相同的光照算法,你可以通过包含更多关于材质的数据到G缓冲中来减轻这一缺点。
为了克服这些缺点(特别是混合),我们通常分割我们的渲染器为两个部分:一个是延迟渲染的部分,另一个是专门为了混合或者其他不适合延迟渲染管线的着色器效果而设计的的正向渲染的部分。为了展示这是如何工作的,我们将会使用正向渲染器渲染光源为一个小立方体,因为光照立方体会需要一个特殊的着色器(会输出一个光照颜色)。
在正向渲染的阶段,还需要延迟渲染阶段的一些信息,比如正向渲染一些光源,光源与物体之间存在遮挡关系,那么就需要用到延迟渲染中的深度信息
更多光源
原来的正向渲染是先对所有物体,每一个物体都对所有光源计算一遍 shading,然后再根据深度测试判断是否写入颜色缓冲
或者启动了 early z 的话,也只是提前筛选掉一些物体,最终也要到每一个物体对所有光源计算一遍 shading
延迟渲染是先将所有物体的几何信息记录在一个缓冲上,然后再渲染一个铺屏四边形,从 gbuffer 中采样几何信息计算光照,也就是每一个片元对所有光源计算一遍 shading
这里其实并没有涉及到怎么支持更多光源
真正让大量光源成为可能的是我们能够对延迟渲染管线引用的一个非常棒的优化:光体积(Light Volumes)
通常情况下,当我们渲染一个复杂光照场景下的片段着色器时,我们会计算场景中每一个光源的贡献,不管它们离这个片段有多远。很大一部分的光源根本就不会到达这个片段,所以为什么我们还要浪费这么多光照运算呢?
隐藏在光体积背后的想法就是计算光源的半径,或是体积,也就是光能够到达片段的范围。由于大部分光源都使用了某种形式的衰减(Attenuation),我们可以用它来计算光源能够到达的最大路程,或者说是半径。我们接下来只需要对那些在一个或多个光体积内的片段进行繁重的光照运算就行了。这可以给我们省下来很可观的计算量,因为我们现在只在需要的情况下计算光照。
这个方法的难点基本就是找出一个光源光体积的大小,或者是半径。
计算一个光源的体积或半径
使用公式:
F l i g h t = 1 K c + K l ∗ d + K q ∗ d 2 F_{light} = \dfrac{1}{K_c+K_l*d+K_q*d^2} Flight=Kc+Kl∗d+Kq∗d21
计算光源的亮度
但是这个亮度永远不可能等于 0,所以我们要设置一个亮度阈值,低于这个阈值认为是不可见的
我们选择5/256作为一个合适的光照值;除以256是因为默认的8-bit帧缓冲可以每个分量显示这么多强度值(Intensity)。
我们使用的衰减方程在它的可视范围内基本都是黑暗的,所以如果我们想要限制它为一个比5/256更加黑暗的亮度,光体积就会变得太大从而变得低效。只要是用户不能在光体积边缘看到一个突兀的截断,这个参数就没事了。当然它还是依赖于场景的类型,一个高的亮度阀值会产生更小的光体积,从而获得更高的效率,然而它同样会产生一个很容易发现的副作用,那就是光会在光体积边界看起来突然断掉。
解一元二次方程得到光的半径
最直接的根据光的半径的计算思路是
struct Light {
[...]
float Radius;
};
void main()
{
[...]
for(int i = 0; i < NR_LIGHTS; ++i)
{
// 计算光源和该片段间距离
float distance = length(lights[i].Position - FragPos);
if(distance < lights[i].Radius)
{
// 执行大开销光照
[...]
}
}
}
真正使用光体积
上面那个片段着色器在实际情况下不能真正地工作,并且它只演示了我们可以不知怎样能使用光体积减少光照运算。然而事实上,你的GPU和GLSL并不擅长优化循环和分支。这一缺陷的原因是GPU中着色器的运行是高度并行的,大部分的架构要求对于一个大的线程集合,GPU需要对它运行完全一样的着色器代码从而获得高效率。这通常意味着一个着色器运行时总是执行一个if语句所有的分支从而保证着色器运行都是一样的,这使得我们之前的半径检测优化完全变得无用,我们仍然在对所有光源计算光照!
使用光体积更好的方法是渲染一个实际的球体,并根据光体积的半径缩放。这些球的中心放置在光源的位置,由于它是根据光体积半径缩放的,这个球体正好覆盖了光的可视体积。这就是我们的技巧:我们使用大体相同的延迟片段着色器来渲染球体。因为球体产生了完全匹配于受影响像素的着色器调用,我们只渲染了受影响的像素而跳过其它的像素。下面这幅图展示了这一技巧:

它被应用在场景中每个光源上,并且所得的片段相加混合在一起。这个结果和之前场景是一样的,但这一次只渲染对于光源相关的片段。它有效地减少了从nr_objects * nr_lights到nr_objects + nr_lights的计算量,这使得多光源场景的渲染变得无比高效。这正是为什么延迟渲染非常适合渲染很大数量光源。
然而这个方法仍然有一个问题:面剔除(Face Culling)需要被启用(否则我们会渲染一个光效果两次),并且在它启用的时候用户可能进入一个光源的光体积,然而这样之后这个体积就不再被渲染了(由于背面剔除),这会使得光源的影响消失。这个问题可以通过一个模板缓冲技巧来解决。
渲染光体积确实会带来沉重的性能负担,虽然它通常比普通的延迟渲染更快,这仍然不是最好的优化。另外两个基于延迟渲染的更流行(并且更高效)的拓展叫做延迟光照(Deferred Lighting)和切片式延迟着色法(Tile-based Deferred Shading)。这些方法会很大程度上提高大量光源渲染的效率,并且也能允许一个相对高效的多重采样抗锯齿(MSAA)。然而受制于这篇教程的长度,我将会在之后的教程中介绍这些优化。
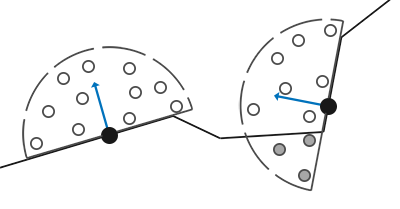
SSAO
对于铺屏四边形(Screen-filled Quad)上的每一个片段,我们都会根据周边深度值计算一个遮蔽因子(Occlusion Factor)。这个遮蔽因子之后会被用来减少或者抵消片段的环境光照分量。遮蔽因子是通过采集片段周围球型核心(Kernel)的多个深度样本,并和当前片段深度值对比而得到的。高于片段深度值样本的个数就是我们想要的遮蔽因子。
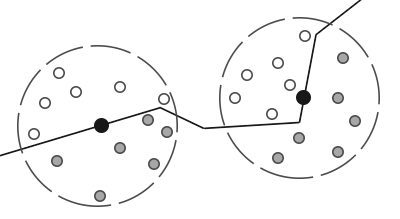
上图中在几何体内灰色的深度样本都是高于片段深度值的,他们会增加遮蔽因子;几何体内样本个数越多,片段获得的环境光照也就越少。
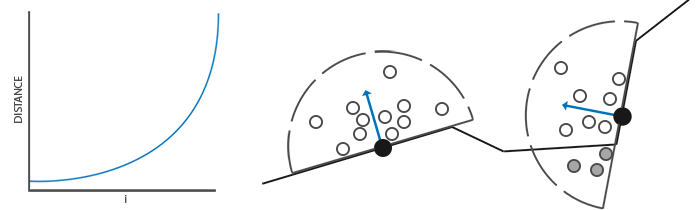
很明显,渲染效果的质量和精度与我们采样的样本数量有直接关系。如果样本数量太低,渲染的精度会急剧减少,我们会得到一种叫做波纹(Banding)的效果;如果它太高了,反而会影响性能。我们可以通过引入随机性到采样核心(Sample Kernel)的采样中从而减少样本的数目。通过随机旋转采样核心,我们能在有限样本数量中得到高质量的结果。然而这仍然会有一定的麻烦,因为随机性引入了一个很明显的噪声图案,我们将需要通过模糊结果来修复这一问题。下面这幅图片(John Chapman的佛像)展示了波纹效果还有随机性造成的效果:

Crytek公司开发的SSAO技术会产生一种特殊的视觉风格。因为使用的采样核心是一个球体,它导致平整的墙面也会显得灰蒙蒙的,因为核心中一半的样本都会在墙这个几何体上。下面这幅图展示了孤岛危机的SSAO,它清晰地展示了这种灰蒙蒙的感觉:
由于这个原因,我们将不会使用球体的采样核心,而使用一个沿着表面法向量的半球体采样核心。
通过在法向半球体(Normal-oriented Hemisphere)周围采样,我们将不会考虑到片段底部的几何体.它消除了环境光遮蔽灰蒙蒙的感觉,从而产生更真实的结果。
法向半球
它在半球里面均匀采样的方法是,现在每一个轴上均匀采样,然后归一化
std::uniform_real_distribution<GLfloat> randomFloats(0.0, 1.0); // 随机浮点数,范围0.0 - 1.0
std::default_random_engine generator;
std::vector<glm::vec3> ssaoKernel;
for (GLuint i = 0; i < 64; ++i)
{
glm::vec3 sample(
randomFloats(generator) * 2.0 - 1.0,
randomFloats(generator) * 2.0 - 1.0,
randomFloats(generator)
);
sample = glm::normalize(sample);
sample *= randomFloats(generator);
GLfloat scale = GLfloat(i) / 64.0;
ssaoKernel.push_back(sample);
}
我怎么记得这种方法是没办法得到球内的均匀分布的
我们更愿意将更多的注意放在靠近真正片段的遮蔽上,也就是将核心样本靠近原点分布。我们可以用一个加速插值函数实现它:
...[接上函数]
scale = lerp(0.1f, 1.0f, scale * scale);
sample *= scale;
ssaoKernel.push_back(sample);
}
这里的 lerp 定义还有点不太一样
GLfloat lerp(GLfloat a, GLfloat b, GLfloat f)
{
return a + f * (b - a);
}
我的感觉是,虽然从正方形到半球,得到的不是半球内的均匀分布,但是因为之后做了一个缩放处理,希望越靠近原点,采样点越密,所以我们并不强求前面的得到的是不是均匀分布,只要最后能够满足“越靠近原点,采样点越密”就好了
随机核心转动
通过引入一些随机性到采样核心上,我们可以大大减少获得不错结果所需的样本数量。我们可以对场景中每一个片段创建一个随机旋转向量,但这会很快将内存耗尽。所以,更好的方法是创建一个小的随机旋转向量纹理平铺在屏幕上。
我们创建一个4x4朝向切线空间平面法线的随机旋转向量数组:
std::vector<glm::vec3> ssaoNoise;
for (GLuint i = 0; i < 16; i++)
{
glm::vec3 noise(
randomFloats(generator) * 2.0 - 1.0,
randomFloats(generator) * 2.0 - 1.0,
0.0f);
ssaoNoise.push_back(noise);
}
由于采样核心是沿着正z方向在切线空间内旋转,我们设定z分量为0.0,从而围绕z轴旋转。
我们接下来创建一个包含随机旋转向量的4x4纹理;记得设定它的封装方法为GL_REPEAT,从而保证它合适地平铺在屏幕上。
GLuint noiseTexture;
glGenTextures(1, &noiseTexture);
glBindTexture(GL_TEXTURE_2D, noiseTexture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB16F, 4, 4, 0, GL_RGB, GL_FLOAT, &ssaoNoise[0]);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
我在想为什么不在片元着色器里面实现一个随机数算法
不过看到它才创建一个 4 * 4 的纹理,而不是满屏尺寸的纹理,他的意思应该是,需要一点随机,但是不需要那么多随机?
SSAO着色器
感觉都直接看原文就好了

















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









