







目录
- 课程 PPT
- 别人的总结
- 第一节 游戏引擎导论
- 第二节 引擎架构分层
- 第三节 如何构建游戏世界
- 第四节 引擎中的渲染实践
- 作业 1 Piccolo 编译启动
- 第五节 渲染中光和材质的数学魔法
- 第六节(上) 游戏中地形大气和云的渲染
- Real-World Landscape
- Environment Components in Games
- Simple Idea - Heightfield
- Render Terrain with Heightfield
- Adaptive Mesh Tessellation
- Two Golden Rules of Optimization
- Triangle-Based Subdivision
- QuadTree-Based Subdivision
- Solving T-Junctions among Quad Grids
- Triangulated Irregular Network (TIN)
- GPU-Based Tessellation
- Hardware Tessellation
- Mesh Shader Pipeline
- Real-Time Deformable Terrain
- Non-Heightfield Terrain
- Crazy Idea - Volumetric Representation
- Marching Cubes
- Terrain Materials
- Simple Texture Splatting
- Advanced Texture Splatting
- Advanced Texture Splatting - Biased
- Sampling from Material Texture Array
- Parallax and Displacement Mapping
- Expensive Material Blending
- Virtual Texture
- VT Implementation, DirectStorage & DMA
- Floating-point Precision Error
- Camera-Relative Rendering
- Tree Rendering
- Decorator Rendering
- Road and Decals Rendering
- Sky and Atmosphere
- Analytic Atmosphere Appearance Modeling
- Participating Media
- How Light Interacts with Participating Media Particles?
- Volume Rendering Equation (VRE)
- Real Physics in Atmosphere
- Scattering Types
- Rayleigh Scattering
- Rayleigh Scattering Equation
- Why Sky is Blue
- Mie sacttering
- Mie Scattering Equation
- Mie Scattering in Daily Life
- Variant Air Molecules Absorption
- Single Scattering vs. Multi Scattering
- Ray Marching
- Precomputed Atmospheric Scattering
- Challenges of Precomputed Atmospheric Scattering
- A Scalable and Production Ready Sky and Atmosphere Rendering Technique
- Cloud
- QA
- 第七节 游戏中渲染管线、后处理、和其他的一切
课程 PPT
https://games-cn.org/games104-slides/
别人的总结
抄了很多别人的总结,很详细……节省时间
https://zhuanlan.zhihu.com/p/500729724
第一节 游戏引擎导论
游戏引擎历史
John Carmack
《德军总部3D》
《Doom》
《Shadow Caster》
《Quake》
Quake Engine
CPU 不适合并行 出现了显卡
现代游戏引擎


什么是游戏引擎
游戏引擎是指一些已编写好的可编辑电脑游戏系统或者一些交互式实时图像应用程序的核心组件。这些系统为游戏设计者提供各种编写游戏所需的各种工具,其目的在于让游戏设计者能容易和快速地做出游戏程式而不用由零开始。大部分都支持多种操作平台,如Linux、Mac OS X、微软Windows。游戏引擎包含以下系统:渲染引擎(即“渲染器”,含二维图像引擎和三维图像引擎)、物理引擎、碰撞检测系统、音效、脚本引擎、电脑动画、人工智能、网络引擎以及场景管理。
游戏引擎内容
基础元素
引擎结构和层次
数据组织和管理
MVVM
渲染
模型,材质,着色器,材质
光源,阴影
渲染管道
天空,地形,等等
动画
动画的基础概念
动画结构与管线
物理
物理系统的基础概念
游戏表现的应用
性能优化
游戏性
事件系统
脚本系统
图表驱动
Misc 系统
特效 寻路 摄像机
工具体系
C++ 反射
数据图表
在线游戏
Lockstep 帧同步
state 状态同步
连续性
先进技术
动作匹配
程序化内容生成 PCG
面向数据编程 DOP
任务系统 Job System 方便多线程
Lumen 全局光照
Nanite 虚拟多边形几何体
第二节 引擎架构分层
分层概述
工具层(Tool Layer)
在一个现代游戏引擎中,我们最先看到的可能不是复杂的代码,而是各种各样的编辑器,利用这些编辑器,我们可以制作设计关卡、角色、动画等游戏内容,这一系列编辑器就构成了引擎最上面的一层——工具层。
功能层(Function Layer)
将一个三维虚拟世界转换为一帧一帧的二维图像的过程,我们需要用到渲染系统(Rendering);让一个个静止的模型运动起来,做出惟妙惟肖的动作,形成连续的画面,我们需要用到动画系统(Animation);物理的碰撞,各种力的作用,让物体的运动更贴近真实世界,我们需要用到物理系统(Physics);每一个游戏世界都有着自己的规则,还要有NPC来丰富游戏可玩性,这就需要用到脚本(Script)、状态机(FSM)和AI;任何一个游戏的操作都离不开人机交互,这其中又涉及一系列功能。以上的种种功能组合在一起便构成了游戏引擎的功能层。
资源层(Resource Layer)
游戏中有的不只是一行行的源代码,还有各种格式的多媒体文件,如PhotoShop的PSD文件、3DSMAX的MAX文件,加载管理这一系列的图形、图像、音频、视频文件以及其他数据,就是资源层的任务了。资源层位于功能层之下,不断为功能层提供数据,这就好像上面是一个画家在画画,而资源层在下面不断为其提供颜料。
核心层(Core Layer)
游戏引擎中最核心,最重要的一层就是核心层。核心层负责响应上面层次频繁的调用,提供各种基础功能,如内存管理、容器的分配、数据的运算、多线程的创建等等。
平台层(Platform Layer)
平台层是最容易被忽略的一层,一款游戏或者引擎可能被发布在不同的平台上,会有不同的图形接口;并且不同的用户可能使用不同的硬件设备,如键鼠和手柄。适应不同的平台,就是平台层的任务。
第三方库(Third Party Libraries)
中间件和第三方库通过SDK(Software Development Kit)的形式或文件格式进行转化。
资源层
Photohop中的PSD文件、3DSMAX中的MAX文件等一般包含工具自带信息,大量与引擎无关的数据,数据格式比较复杂, 直接使用会很大程度上降低效率。为了提高调度资源的效率,需要引擎在导入时将不同资源都转换为资产(assets)文件。例如引擎中使用贴图文件时,我们可能导入JPG、PNG格式的文件,但这两种文件的压缩算法对于GPU来说并不高效,直接在GPU中使用会浪费性能,所以其通常被转换成dds格式再存入显存中。
对于任意一个游戏人物,例如上图的小机器人,可能需要绑定对应的材质、贴图、网格、动画等资源,定义一个Composite asset文件关联这些资源,比如XML文件,并使用GUID(全局唯一标识符)进行标识管理。
实际运行时,游戏还需要用到资产管理器(Runtime Asset Manager),其根据资产的生命周期(Asset Life Cycle)对资产进行管理操作,资产的实时加载卸载、资源的分配、垃圾回收(GC)、延时加载等都包括在其中。
功能层
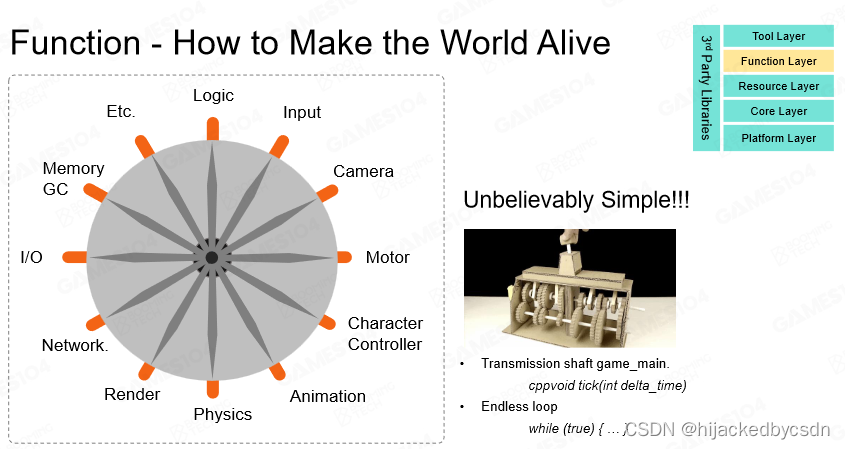
功能层的使用,使得每过一个tick时间,游戏中的虚拟世界就会前进一步。一个tick时间内,分别执行tickLogic()和tickRender()函数,其中逻辑方面的tickLogic()一般先执行,主要用于模拟游戏世界,包括输入输出的处理、相机视角位置的变换、碰撞的检测等操作;用于绘制世界的tickRender()则依据tickLogic()计算出的各资产的位置情况进行渲染绘制。
功能层非常的复杂庞大,特别是涉及到网络编程时,所以通常需要借助多线程计算。当前主流的多线程是将可以并行计算的任务拆分开来,分别放到多个线程运算,但若有不适用于并行计算的任务,其缺陷便显露出了。在未来,引擎会将每个任务划分为极小的可执行单元,将这一个个原子般的任务分配到多个线程中执行,更加高效的利用资源。
任务之间是有依赖性关系的,这是并行实现的难点
核心层
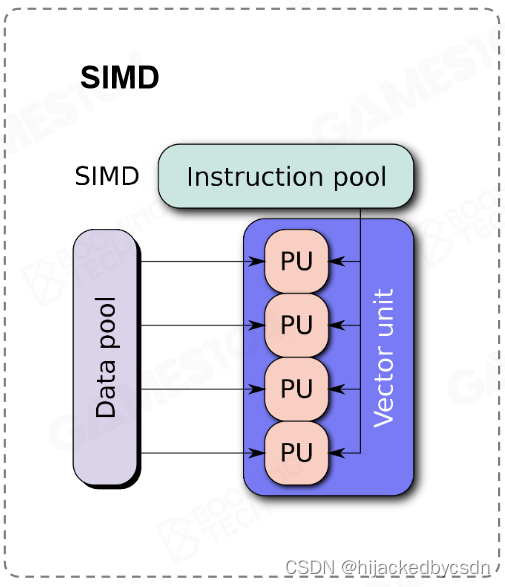
核心层为上层的所有逻辑提供一个基础,它提供数学库(如矩阵运算)、数据结构和容器(如二叉树)、内存管理等工具。因为引擎的一切都是以效率为核心的,所以在进行数学运算时,可以使用近似运算或者SIMD(单指令多数据流,以同步方式,在同一时间内执行同一条指令)提高运算效率;至于数据结构和容器,编程语言中自带的数据结构可能会出现一些问题,比如C++中的Vector在添加对象时开辟的储存空间会成倍增长,在添加大量对象后,使用的储存空间我们将无法得知,可能会产生内存空洞,而引擎中的数据结构更加方便内存的管理,提高访问效率;引擎的内存管理和操作系统很相似,核心原理可以概括为:尽可能把数据储存在一起,访问时按顺序访问,处理时批量处理。
以前在数学库还不完善的时候,使用了一个 hack 来计算 1/srqt(x)
具体是牛顿迭代法

现在 CPU 和 GPU 已经有 rsqrt 函数了
SIMD Single Instruction Multiple Data 单指令多数据
为什么不用 C++ 的 STL
因为 C++ 的 STL 在频繁增删的时候会留下许多内存碎片,并且难以管控内存使用,例如 vector 扩容的时候直接扩一倍
平台层
平台层使得游戏能够兼容如Xbox、Mac、Windows等不同平台,手柄、键鼠等不同设备。平台层通过使用Render Hardware Interface(RHI)来去除不同Graphics API(如DirectX11、DirectX12、OpenGL)之间的差异,使上层无需关心使用不同API可能会带来的问题。
工具层
工具层一般以编辑器的形式(蓝图编辑器、材质编辑器等)呈现,可以使用不同编程语言开发(C++、C#、Html5等),以开发效率优先,它需要使不同使用者能够创造游戏内容。因为很多游戏的数字资产是在不同DCC(Blender、MAYA等)中创建的,所以工具层一般包含导入、导出工具用于导入、导出游戏资源。
为什么要分层架构?
为了使游戏引擎解耦并降低复杂度,每一层都将独立完成自己的任务,底层为上层提供基础服务,上层调用底层的工具。这样的分层架构使得上层灵活,底层稳定,更有利于功能的更新和开发。
Takeaway
游戏引擎被设计为分层架构
在这一分层架构中,越往下,越稳定;越往上,越开放灵活
游戏中的虚拟世界由一系列tick时间组成
第三节 如何构建游戏世界
如何让游戏世界活起来
Dynamic Game Objects(动态游戏物体)
Static Game Objects(静态游戏物体)
Environments(环境系统)
Other Game Objects(其他游戏物体,一般都不是实物)
属性和行为基本可以描述以上所有物体。
用C++面向对象与派生、继承的特点,描述一个Game Objects。
在游戏物体日益复杂的情况下,通过继承的方法很难描述一个属性和行为复杂的游戏对象,因此现在发展成通过定义组件(Components),然后用组件组成一个需要的游戏对象的方式。这样方便自定义,以及组件复用,并且方便用户理解和使用。
从组件到游戏对象构建出游戏中的万事万物。
Tick
Object-based Tick
Component-based Tick(现代引擎常用的,类似工业流水线。把同类Component放在一起读写、处理效率更高)。
Event
发展:从hardcode 到 event。
Event在系统架构中被叫做解耦合,改变了对象、组件之间的通信方式(时间驱动,观察者模式,事件回调)。
如何管理游戏对象
Scene Management:用于通知管理GO(Game Object),通过GO的唯一ID与场景位置实现。
如何管理:
最直接简单的是所有GO依次查找位置,但当GO较多时开销大;
二是把场景划分成均匀的格子,但是当GO分布不均匀时不适合;
三是树形结构,例如Quadtree;
其他,BVH, BSP, Octree, Scene Graph。
Takeaway
任何物体
其他需要处理的复杂情况
component tick 中要考虑到 component 之间的顺序,例如先 tick 父 component,再 tick 子 component,这样,子 component 中依赖于父 component 的逻辑才会正确
tick+event产生的时序问题,循环依赖,如果处理不好会产生逻辑冲突,尤其容易在多线程中产生。
游戏的精彩回顾不是游戏储存了录屏文件,二是把游戏时的玩家数据输入存储起来,通过这些数据进行场景复现。
Pre tick()、Post tick() 函数。
QA
如果一个 tick 时间过长怎么办?
传入步长
直接执行两个 tick,比较危险
分帧处理
tick 时,渲染线程和逻辑线程怎么同步
logic 比 render 稍微早一点
空间划分怎么处理动态的游戏对象
根据游戏类型,如果很多动态物体,一般选择更新起来比较轻量的,比如 BVH
组件模式有什么缺点
效率没有 class 高,每次都要找到组件的接口
组件之间也要通讯,需要不停 require,对效率的影响比较高
event 怎么调试比较好
不停打 log
或者将所有的 event 显示到 3d 空间
物理和动画互相影响的时候怎么处理?
表现上是动画表现和物理表现之间插值,一开始是动画表现占比比较高,之后是物理表现占比比较高
第四节 引擎中的渲染实践
渲染概述
游戏渲染中的挑战:
-
游戏渲染系统非常复杂,包含大量的 game object 和不同的效果;
-
要深度适配现代硬件架构,GPU、CPU;
-
对高帧率与高分辨率越来越高的要求;
-
对 CPU 性能的有限使用,因为 CPU 除了渲染之外还要为游戏逻辑、网络、物理、ai 系统提供算力。
渲染课程大纲
-
游戏渲染基础
硬件结构
渲染数据结构
可见性
-
材质,着色器,光照
PBR(SG, MR)
着色器 permutation 排列
光照
-
点/方向 光源
-
全局光照算法 IBL/ SImple GI
-
渲染系统的对象
此部分大多为GAMES101知识点。
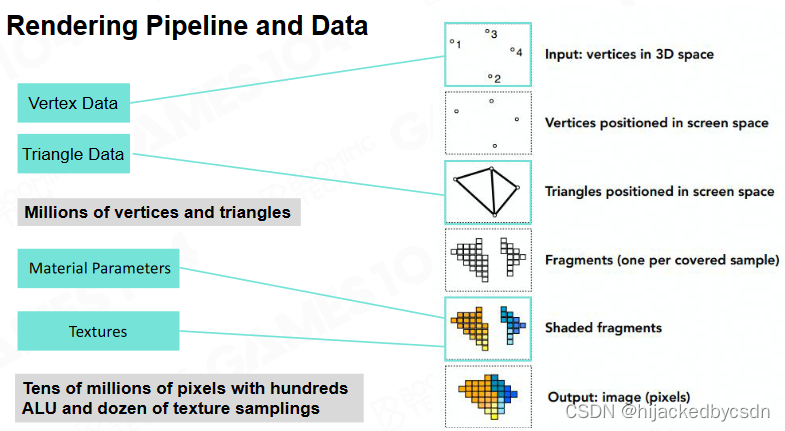
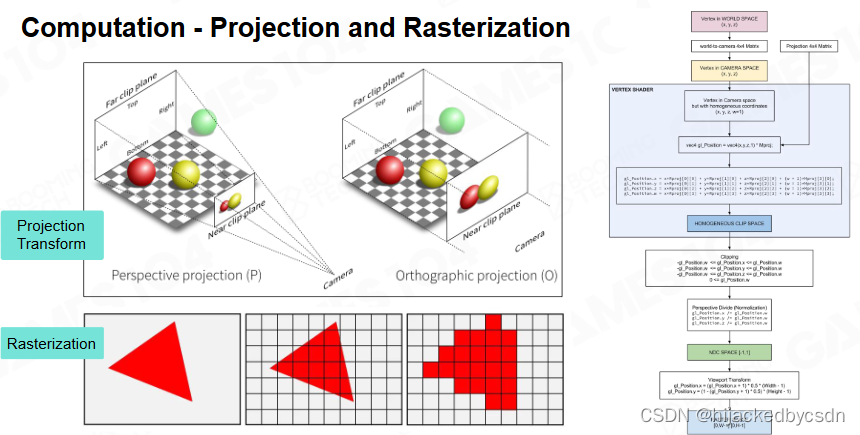
渲染管线与数据:
投影和光栅化
着色
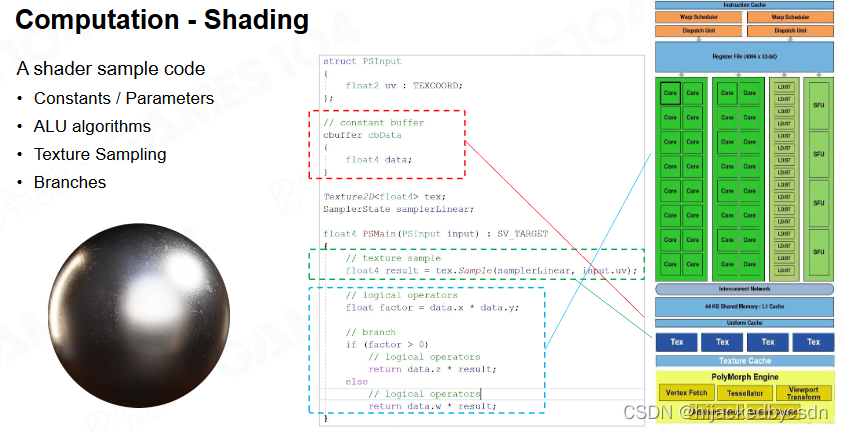
纹理采样
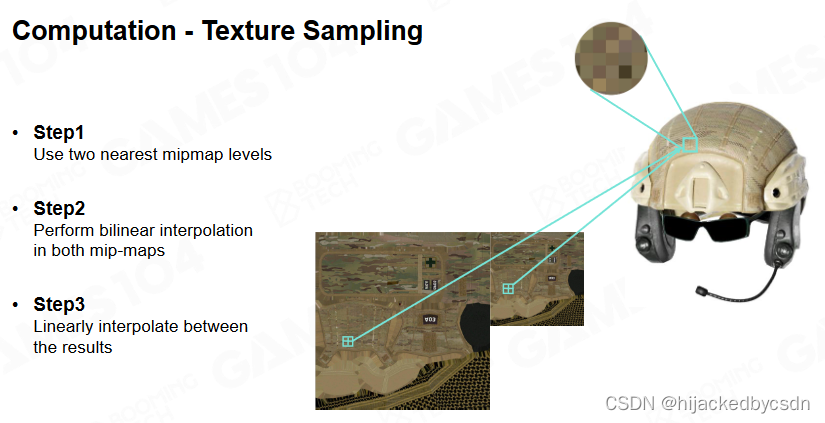
在 mipmap 上采样需要 7 次插值,一个 level 一次双线性插值需要插值 3 次,两个 level 之间插值 1 次
所以纹理采样也是比较耗时的
了解GPU
SIMD(Single Instruction Multiple Data)单指令多数据流,并发编程。例如向量运算(x,y,z),一个指令可以完成三个运算。
SIMT(Single Instruction Multiple Threads)单指令多线程,可以理解为把多个 SIMD 同时运行,SIMT+SIMD 使显卡运算量运算速度大量提升。
与 PC 不同,游戏主机的内存是共享的,被称作 UMA(Unified Memory Architecture)。
引擎的架构是和硬件架构(PC、主机、手机等都不相同)息息相关的。
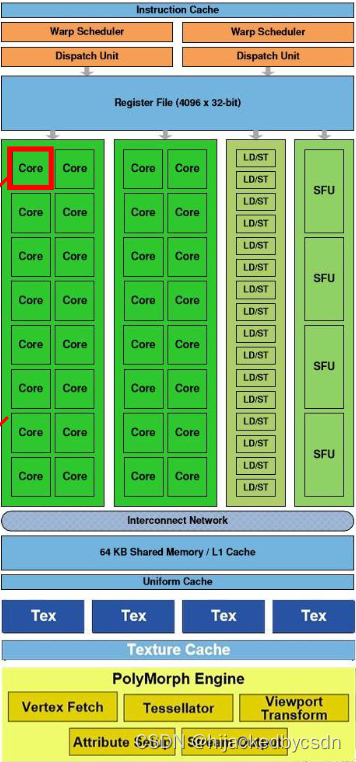
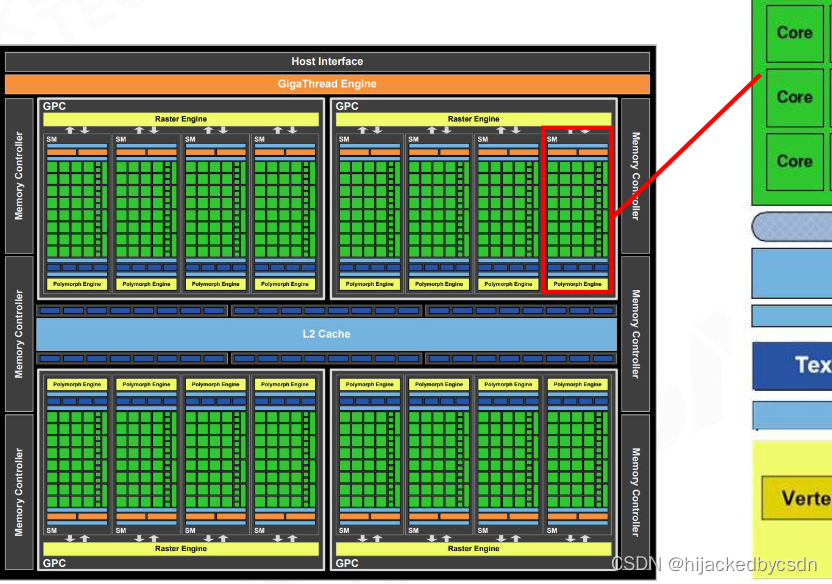
GPU Architecture
https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
有一个 Giga Thread Engine 管理所有正在进行的工作。 GPU被划分为多个GPC(Graphics Processing Cluster),每个GPC都有多个SM(Streaming Multiprocessor)和一个Raster Engine。在这个过程中有很多互连,最显着的是允许跨 GPC 或其他功能单元(如 ROP(render output unit)子系统)迁移工作的 Crossbar。
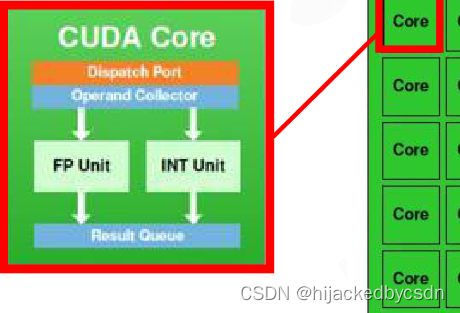
程序员认为的工作(执行着色器程序)是在 SM 上完成的。它包含许多对线程进行数学运算的Core。例如,一个thread 可以是顶点着色器或像素着色器调用。这些核心和其他单元由Warp Scheduler驱动,它们管理一组 32 个线程作为 warp 并将要执行的指令交给Dispatch Unit。代码逻辑由调度程序处理,而不是在内核本身内部,它只是从调度程序中看到类似于“寄存器 4234 与寄存器 4235 的和并存储在 4230 中”之类的内容。与核心非常智能的 CPU 相比,核心本身相当愚蠢。 GPU 将智能提升到更高的水平,它执行整个集成(或多个,如果你愿意的话)的工作。
这些单元中有多少实际上在 GPU 上(每个 GPC 有多少个 SM,多少个 GPC…)取决于芯片配置本身。
CPU 与 GPU 数据流
要尽可能降低 CPU 与 GPU 之间的数据传输,因为数据的传输较为耗时。Unity URP在这部分有明显的优化。
尽量保持 CPU 向 GPU 的单向数据传输,不要 CPU 从 GPU 中读数据,CPU 的逻辑运算和 GPU 的渲染有差异,CPU 从 GPU 取数据,相当于渲染帧需要等待逻辑帧,可能造成渲染延迟。
Cache
提高运行效率要利用好 Cache 以提高传输速度,使同批数据同时缓存在 Cache中。
GPU Bound
GPU 效率的短板称为 GPU Bound,可能是:
-
内存 Bound
-
ALU Bound
-
TMU(Texture Mapping Unit) Bound
-
BW(BandWidth) Bound
可渲染物体 Renderable
Mesh Render Component
Mesh 用来渲染
Building Blocks of Renderable
不同 Mesh
Mesh Primitive
一个 Mesh 由不同的基元 Primitive 组成
一个 Primitive 是一个数据结构,包含顶点信息,顶点也是一个数据结构
Vertex and Index Buffer
每一个基元如果直接存储顶点信息会浪费空间
因为很多顶点会被三角形共用
因此存储顶点的序号,需要的时候根据序号来找顶点信息
更狠的是把三角形顶点数据排列成一笔画的形式
也就是 v[0] v[1] v[2] 组成一个面 v[1] v[2] v[3] 组成一个面,如此下去就可以描述一个物体
这样也有连续存取的缓存命中的优势
逐顶点法线
需要给每个顶点单独存储法线,因为如果在三角面弯折处两个重合的顶点法线(从三角面获得)会不一样。
如果没有定义逐顶点的法线的话,这个顶点的实际法线就会由邻接的三角面插值出来,得到的就是光滑的样子

材质 Materials
Phong
PBR
Subsurface
纹理 Textures
着色器 Shader
Render Objects in Engine
Coordinate System and Transformation
Object with Many Materials
变换之后,提交 Mesh 和 Material
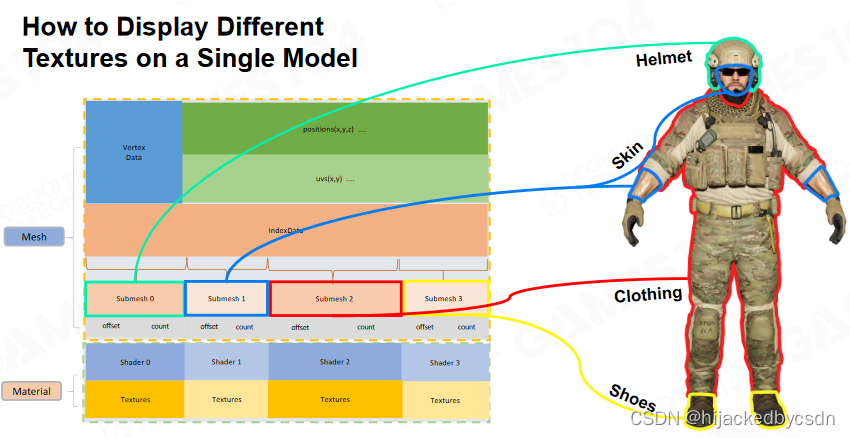
How to Display Different Textures on a Single Model
每一个 Submesh 有自己的材质
但是基础的顶点信息是 Submesh 共用的
所以 Submesh 只需要定义自己使用的顶点序号的偏移量 offset 和数量 count
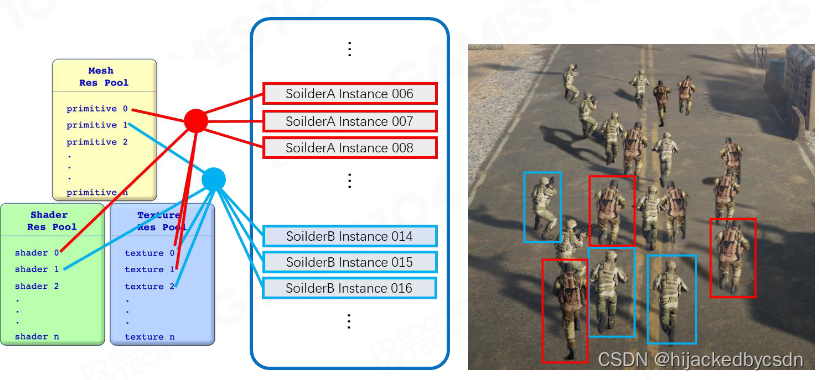
Resource Pool
有很多游戏对象,他们的 Mesh,Texture,Shader 可能都是相同的
因此是可以复用的
如果我每一个对象都有自己的一套 Mesh,Texture,Shader 就会造成浪费
因此我是用一个 Pool 来存放 Mesh,Texture,Shader
渲染物体的时候,在 Pool 中寻找要使用的 Mesh,Texture,Shader
Instance: Use Handle to Reuse Resources
Instance:引擎中的实例化,例如场景中多个相同物体其实是一个 Game Object 的实例。也就是说,场景中的 mesh、shader、texture 都是存储在各自的资源池内,场景渲染时通过索引值去调用资源,这样可以实现场景中相同资源的复用,降低存储空间。是现代游戏引擎中的重要概念。
Sort by Material
游戏引擎在运行时会把场景中的GO按照材质进行分类排序,即把材质相同的SubMesh放在一起,这样可以避免材质参数的频繁改动,提高GPU的利用效率。

GPU Batch Rendering
GPU Batch Rendering:提高场景中相同mesh、material的GO运算效率,提升drawcall 的速度,把更多的计算从CPU中转移到GPU中实现。

可见性裁剪
Using the Simplest Bound to Create Culling
使用包围盒来判断是否裁剪
Hierarchical View Frustum Culling
使用 BVH 来裁剪
Construction and Insertion of BVH in Game Engine
BVH 的建立与插入,时间花销需要小
PVS (Potential Visibility Set)
PVS (Potential Visibility Set)可以理解为透过房间的门和窗最多能看到的房间。该方法也可以用于资源的加载。
BSP-Tree 划分空间
portal 表示门窗
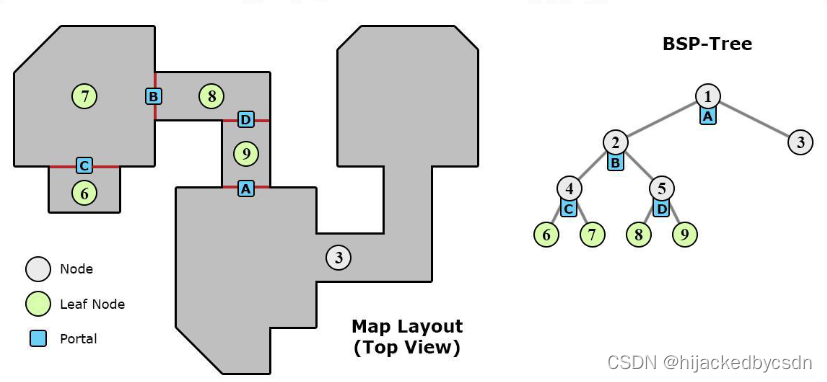
PVS 的计算

The Idea of Using PVS in Stand-alone Games
现代游戏可能不直接使用 PVS
但是也会使用类似 PVS 的思想
将场景划分为几个 zone
这样资源就可以分区域加载
GPU Culling
以前是使用算法来做 Culling
现在也可以交给 GPU 来算
想要自定义 Culling 算法,也可以在 GPU 上定义数据结构
跟 Z-Buffer 类似
纹理压缩
传统的图片压缩格式(JPG、PNG)
-
压缩率高
-
随机访问性能差
游戏中的纹理压缩算法:
-
编解码速度快
-
随机访问强
-
压缩率和视觉效果都有保证
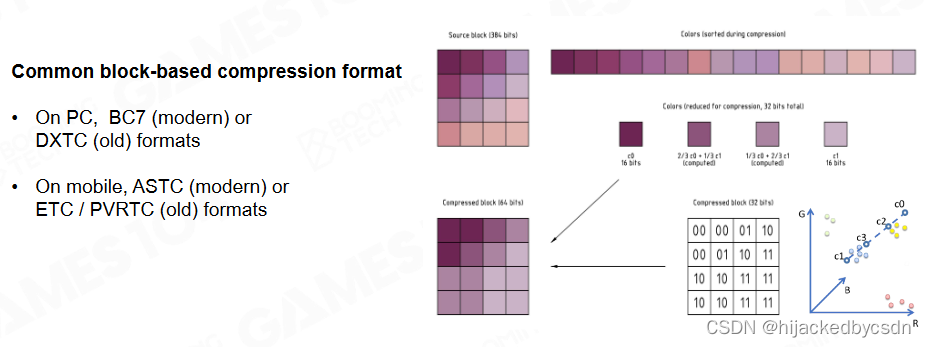
常用的纹理压缩算法:
一种经典算法是基于4*4的块进行压缩:
-
先根据明暗度排序
-
记录下最亮和最暗的像素颜色信息
-
压缩后只记录了每个像素的明度级别
-
最后通过最亮和最暗像素的插值来还原颜色
建模工具
多面体建模工具——3dsMax MAYA Blender
雕刻工具(更为灵活自由)——ZBrush
扫描工具
程序生成建模工具(结合AI)——Houdini、Unreal
基于簇的模型管线——Cluster-Based Mesh Pipeline
两个重要的idea:
一是把mesh面片按照一个数量进行分组,根据距离的远近呈现不同面片细分度的mesh模型,这个功能大多数可以通过代码自动化生成;
二是根据摄像机的方向和距离动态剔除模型不需要被渲染的面片。UE5的Nanite可以理解为在Cluster-Based Mesh Pipeline基础上的优化。
Programmable Mesh Pipeline
可编程的网格管线
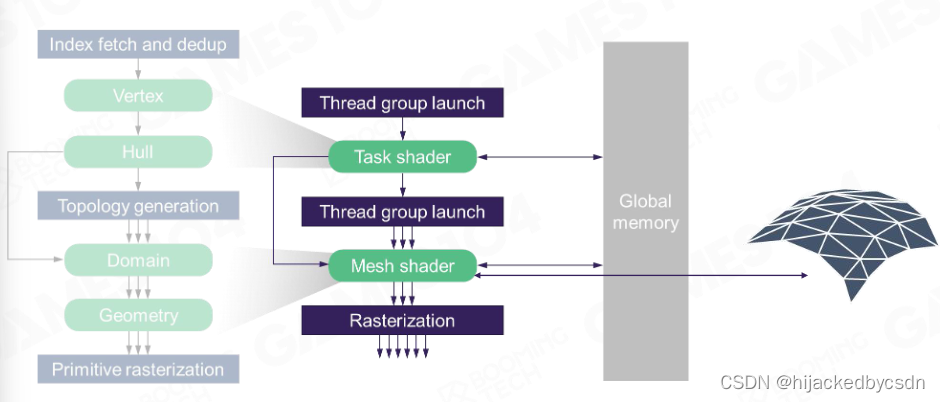
经典的管线
VS
PS
Hull Domain Geometry
把放进的三角形无限的细化
Task Mesh Shader
基于一个算法无限生成
根据距离选择精度
有点没懂
GPU Culling in Cluster-Based Mesh
网格簇渲染:每次drawcall生成随机数量的网格,GPU每次对簇进行排序,按照簇的边缘进行裁剪
几何渲染管线架构(2021)
渲染单元按如下方式划分:
Batch: 一次drawcall由多个surfs组成
Surf: 基于材质的子网格,包含很多clusters
每个Cluster由64个三角形组成
UE——Nanite
像素级的网格渲染,基于以下技术实现:
带有连续边界的分级LOD(多层次细节,降低不重要GO的细节和面数)
无需硬件支持,通过GPU的计算着色器线程(而非任务着色器)预先计算的BVH树实现分级cluster culling
Takeaway
游戏引擎设计和硬件架构设计紧密相关
子网格常用于带有多个材质的模型
使用裁剪算法尽量减少绘制的GO
GPU快速发展,使得大量工作转向GPU,称之为GPU-Driven
QA
Mesh shader 或者 clustered mesh 未来会怎么发展
世界整个并行化
引擎有必要自己写渲染管线吗
尽可能符合主流
图形代码怎么 debug
代码分为一个个小步
作业 1 Piccolo 编译启动
vulkan 报错
我在 VS2019 中以 Debug 模式启动时出现了如下报错
Assertion failed: instance != VK_NULL_HANDLE, file ..\Piccolo-main\engine\3rdparty\glfw\src\vulkan.c, line 305
[error] [Piccolo::VulkanRHI::createInstance] vk create instance
[error] [Piccolo::VulkanRHI::initializeDebugMessenger] failed to set up debug messenger!
..\Piccolo-main\build\engine\source\editor\Debug\PiccoloEditor.exe (进程 21256)已退出,代码为 3。
具体在代码的哪里报错它也没有跳转
我搜了一下别人的做法,装了最新版的 vulkan sdk 和 n 卡驱动就好了
n 卡驱动有两个版本,gameplay 和 studio,我不知道有啥区别,装了 gameplay 就好了
第五节 渲染中光和材质的数学魔法
渲染计算中的元素
-
光照
光子发射,反弹,吸收,透射
-
材质
对光子的反应行为
-
Shader 着色器
渲染方程
L o ( x , w o ) = L e ( x , w o ) + ∫ H 2 f r ( x , w o , w i ) L i ( x , w i ) cos θ i d w i L_o(x,w_o) = L_e(x,w_o) + \int_{H^2}f_r(x,w_o,w_i)L_i(x,w_i)\cos\theta_i\mathrm d w_i Lo(x,wo)=Le(x,wo)+∫H2fr(x,wo,wi)Li(x,wi)cosθidwi
Games101 中细讲过
渲染的挑战
-
光的可见性,阴影怎么做的好
-
光源本身的复杂度
点光源,锥形光源,面光源
-
半球的积分怎么做
-
每个点都可以是光源
这也导致方程本身是递归的。一个例子是,别人的 L i L_i Li 进来,自己的 L o L_o Lo 出去,然后这个反射光再经过其他物体反射回来成为入射的 L i L_i Li
简易光照解决方案
简化光源
使用环境贴图
简化着色: Blinn-Phong
Diffuse reflection:漫反射(均匀反射),粗糙物体表面向各个方向反射光线。(视线与法线的夹角)
Specular highlights:高光部分(完全反射),可以理解为光线的镜面反色。
Ambient lighting:环境光(间接光照)物体某些点不会被光线直接照到,但我们仍然能够看到颜色,这部分区域是通过周围环境的漫反射获得的光照。通常会使用一个固定常量。
这个模型体现了光学的可叠加性,使用简单易用。但经验模型的能量可能会溢出(射入<射出),如果需要做多次漫反射计算时,迭代的颜色可能会越来越亮(不收敛)。
简化 Shadow:ShadowMap
渲染中的阴影有很多处理方式,但游戏引擎中最常见的处理方式是ShadowMap。阴影可以理解为光线无法直接到达的区域,ShadowMap 的思想很聪明:在光源处放一个 Camera,获取此 Camera 的拍摄的场景物体深度图(ShadowMap)。当我们处理着色时,可以将 Cmaera Shading 中的顶点转换到 Light Camera 空间下的投影空间,对 ShadowMap 进行采样,判断深度是否符合要求。
ShadowMap 虽然易用,但问题也很明显:渲染 Camera 区域对 ShadowMap 进行采样,两者精度是不同的,因此很容易出现走样问题。最常见的就是自遮挡问题

综合得到的光照简化处理方案
简单光源 + 环境贴图
Blinn-Phong 材质
Shadow Map 做阴影
基于预计算的全局光照
傅里叶变换
在中学的时候,我们学过最小二分法将离散数据拟合为多项式方程。傅里叶变换和拟合的思想很像,只不过拟合对象变为了连续函数,拟合的基函数变为了三角函数:将任意数学函数拟合为三角函数的权重组合。(由此也引出了频域的概念)
卷积定理
时域上的卷积 = 频域上的乘积
时域上的乘积 = 频域上的卷积
LightMap
实时计算全局光照太过困难,因此我们想要预先计算全局光照的结果,以内存换时间。最直观的处理方式是将场景投影到一个球体纹理中,这样当我们需要间接光时,只需要根据某个方向进行纹理采样,就可以获取光照信息,避免实时的光照计算。其中生成的纹理,我们称为LightMap,其优缺点如下:
优点:(1)实时运行高效;(2)提供了许多光照细节。缺点:(1)烘焙十分耗时;(2)只能处理静态光源与物体;(3)占用空间很大
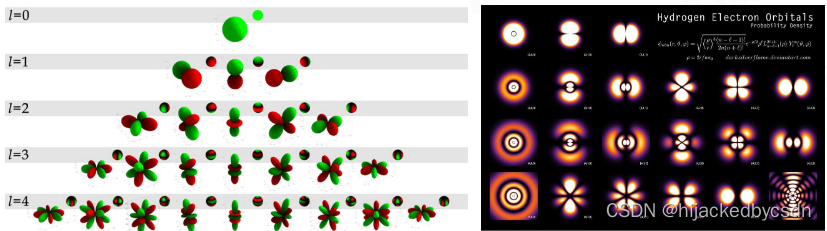
球谐函数 Spherical Harmonics
球谐函数对场景光照数据进行编码,以极小的存储空间替代高精度原始数据,在运行时对像素点反编码出光照数据。
球谐函数利用傅里叶变换的特性,将球面数据映射到相互正交三维方向上。球面上两个函数的卷积,可以简化为其分别投影到球谐函数上的参数系数卷积。球谐函数有以下特性:
是一组 sin cos 的函数集
一阶是在球面上的加权平均
二阶是 y z x
这里是真的没听懂,老师没讲清楚
感觉就是用来拟合球面上面的函数的基函数
因为球面上的函数可以表示为 f ( θ , ϕ ) f(\theta,\phi) f(θ,ϕ)
然后他把球面上的基函数记为 Y l m ( θ , ϕ ) = N l m P l m ( cos θ ) e I m ϕ Y_{lm}(\theta,\phi) = N_{lm}P_{lm} (\cos \theta)e^{Im \phi} Ylm(θ,ϕ)=NlmPlm(cosθ)eImϕ

球面上的基函数的性质:
正交性:任意两个不同的归一化的球谐函数在球面上的积分为0。
旋转不变性:光源旋转后,对世界空间传入的数据进行同样的旋转旋转变换,可以得到同样的光照数据。
球谐基函数二阶导数为0。也就是函数的变化是光滑的。
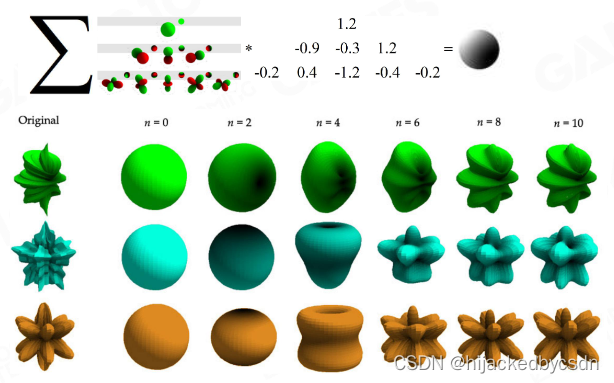
以 n=1 时为例,此时球谐函数由 4 个基函数组成(记录 4 个系数),每个点的光照信息由RGB组成因此一共需要记录 3*4=12 个数据。虽然每个通道都有 4 个参数,但其权重是不一样的
对于球谐函数的 n = 0 阶的参数使用 HDR 的处理方式,剩下的 n = 1 n = 2 使用 LDR 压缩。这样一个光场只需要用 32Bit 就可以进行表达。
这 32 Bit 可以存在颜色贴图的 alpha 通道
记得归一化
总之就是要记得两个函数的卷积等于他们球谐参数的卷积
优点:(1)弥补LightMap无法处理动态物体;(2)十分高效;(3)可以引用与漫反射和高光
缺点:(1)手动场景编辑十分麻烦,需要自动化生成算法;(2)采样率不足导致光照细节不够;
SH Lightmap: Precomputed GI
-
将所有场景参数化到一个 2d 的光照贴图 atlas 中
-
使用离线的光场去计算所有表面点的 irradiance probe
-
将这些 irradiance probe 压缩成球谐参数
-
将球谐参数存到 2d 的光照贴图 atlas 中
Lightmap: UV Atlas
把三维空间的复杂几何投影到 2d 空间
因为一般的三维空间的几何形体比较复杂,所以要先简化
这样得到的 UV 岛也比较少
同时我们希望不同的复杂几何投影得到的贴图的精度是类似的
这样更少有纹理的存储空间会被浪费
Lightmap: Lighting
将光照贴图从代理投射到物体的各级 LOD 上
添加网格细节
使用 HBAO 添加小范围内,高频的光照细节
Lightmap: Lighting + Direct Lighting
动态计算直接光照
Final Shading with Materials
与材质结合
Light Probe
上述的 LightMap 方案是提前计算好的数据,如果动态物体也想要接收这类光照数据,通常的做法在物体周维添加Probe用于实时收集并生成光照数据。
Light Probe 是场景空间中的点,运行时采样整个光场。当采样区域有物体移动时,就对周边光场进行差值计算实时光照信息。
Reflecttion Probe
当需要处理实时的镜面反射是,使用 Reflecttion Probe 来对周围光场采样。只不过 Reflecttion Probe 的采样密度很小,精度很高。
但我们之所以使用 LightMap,就是为了优化获取光照数据的时间,而 Probe 需要实时更新光场数据,如果生成 LightMap 的处理方式,开销是难以接受的
Light Probes + Reflection Probes
在实际做动态更新的时候,可以隔几帧更新,也就是延迟更新,为了保证帧率
优点:(1)弥补 LightMap 无法处理动态物体;(2)十分高效;(3)可以引用与漫反射和高光
缺点:(1)手动场景编辑十分麻烦,需要自动化生成算法;(2)采样率不足导致光照细节不够;
Physical-Based Material
Microfacet Theory
微平面理论认为,物体表面是由许多方向不同的平面组成的。当物体微平面方向较为一致时,其表现为金属材质较为清晰的反射(反射方向一致);反之则很粗糙(反射方向朝向各个方向)
基于微平面的 BRDF 反射模型
渲染方程中,使用BRDF模型来处理物体反射效果。其中反射分为漫反射(diffuse)和高光(spectual)。
金属物体可以捕获光子,而非金属没有能力捕获光子,会朝向四周反射,这就是漫反射和高光的思想:金属度(roughness)越高,漫反射能力越差,高光越明显。
处理高光部分时使用了 CookTorrance 模型来处理高光,其中核心为 DFG 模型:D(Normal Distribution)表示法线分布,F(Fresnel)表示菲尼尔现象,G(Geometric attenuation term)表示微表面之间的内部遮挡,光线射入到人眼接收到的高光能量比例。
游戏引擎中通常使用 GGX 模型模拟 DFG 模型 D\G 项计算,一方面能够简化计算,另一方面 GGX 模型高频和低频都有更好的效果。高频信息衰减得足够快,低频部分衰减得足够慢,也就是满足“高音要脆,低音要沉”。比如高光过渡很柔和。
在计算时,我们只需要设置 roughness 就可以得到这两个参数结果。
在算 G 的时候,先算一遍光线打到微表面的遮挡,再算一遍光线从微表面到眼睛的遮挡,这两个遮挡系数乘起来,就是总的 G
G 的计算的妙处在于,它复用了 D 的推导时的 粗糙度 roughness,使得我控制一个参数就能得到两个函数
F 是菲涅尔
菲尼尔现象:视线与平面的夹角约大,人眼接收到的反射约弱。反射效果越弱,水体看起来越透明,像空气;反射效果越强,水体看起来越光滑,像镜子。因此,当你的视线与水平面接近时,此时就会产生很强的镜面效果。这样CookTorrance模型就可以通过roughness以及fresnel参数就可以进行模拟。
MERL BRDF
上述方程虽然已经能够表达物理世界的效果,但是现实世界的物体仍然很复杂,想要通过艺术家手动调参的方式来实现仍然有一定难度。MERL BRDF数据库,对大量现实中的物体进行采样,提供个各种材质对应的BRDF参数。
迪斯尼BRDF原则
物理材质的每个参数需要容易明白
要尽量使用较少的参数
参数要尽量在 0~1 之间,需要一些特殊效果时可以超出
所有参数的组合不会出现诡异的结果
主流PBR材质
基于上述的原则,现代游戏引擎中常用的PBR模型有以下两种:
- PBR Specular Glossiness
这个模型中参数多以纹理来处理。Diffuse处理漫反射部分,Specular处理菲尼尔项,Glossiness控制材质的光滑程度。虽然这种处理方式已经极大简化了材质处理,但对于高光部分还是很容易出现问题。业内使用Metallic Roughness材质来优化高光项,避免出现奇怪的效果。
菲涅尔是具有颜色的
- PBR Metallic Roughness
MR材质相比SG材质,使用金属度(metalic)来关联diffuse和菲尼尔部分,这样就避免了两个参数冲突问题。本质上MR材质还是使用SG材质,只不过对参数做了一些限制。
Image-Based Lighting(IBL)
光照方程中存在积分项,我们在运行时要如何处理这些积分项呢?IBL的思想是提前将公式中需要的积分项预计算,以空间换时间。
微表面的 BRDF 函数

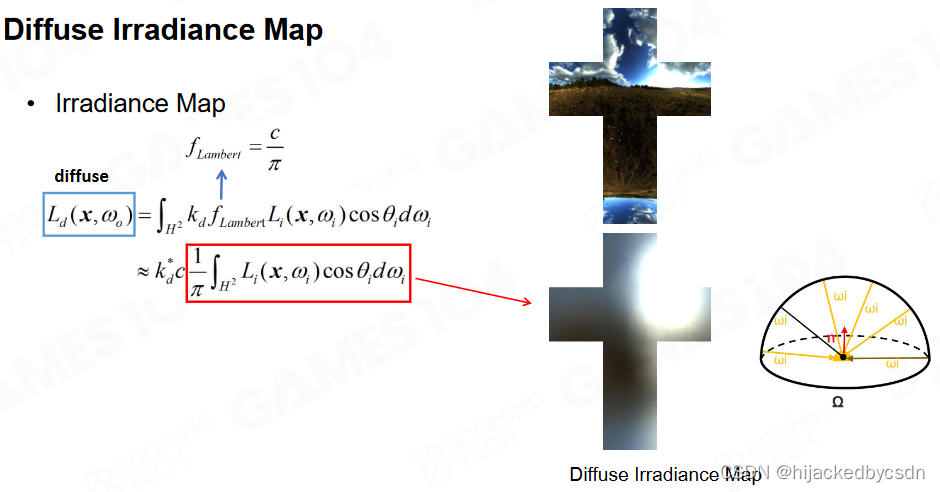
Diffuse Irradiance Map
漫反射部分的光照,是球面对点的积分,可以将这部分数据存储到Irradiance Map中。
Specular Approximation
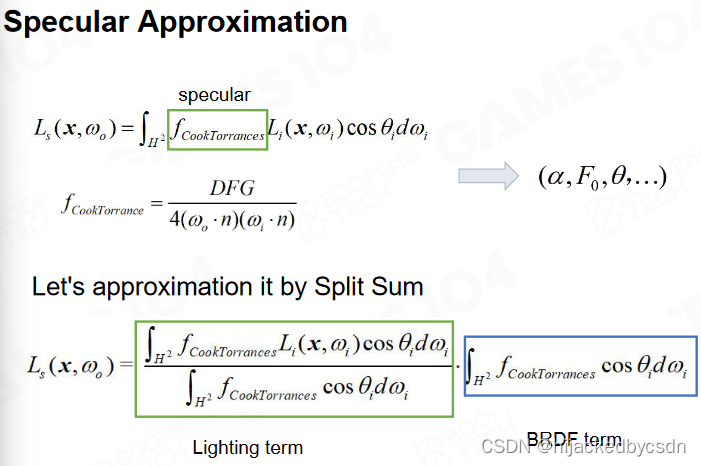
对于高光部分,可近似分解为Lighting term和BRDF term两部分的乘积(乘积的积分与积分的乘积并不等价,看起来对就行吧~)。
变成了三个积分的乘法
把不同粗糙度的结果放到 mipmap
粗糙度越高,对光照的敏感度越低,就是越低频的数据,就可以放到 mipmap 的低级
Lighting term部分通过roughness来确定使用哪一个层级的Environment Map。BRDF term根据roughness和入射光方向与法线的夹角来查找积分值。
这里一堆公式没听过,应该还是要看专门的 202?

Shadow
Shadow Map
Shadow 的通常处理方式是Shadow Map,Shadow Map 原理:在光源处放置一台摄像机,生成一张深度图(Shadow Map),在渲染接收阴影的物体时,将像素点转换到光源空间中,与 Shadow Map 的深度对比。若位置处于 ShadowMap 记录深度前方,则不处于阴影中;反之则处于阴影中。
但Shadow Map最大的问题是精度不足。当我们的视线范围教大时,所需的阴影精度可能较低;但当我们的视野范围缩小时,就需要较高精度的阴影,而我们的Shadow的采样区域和分辨率是相对固定的。并且在距离人眼比较近的位置,阴影更加清晰,远离人眼的阴影相对模糊。
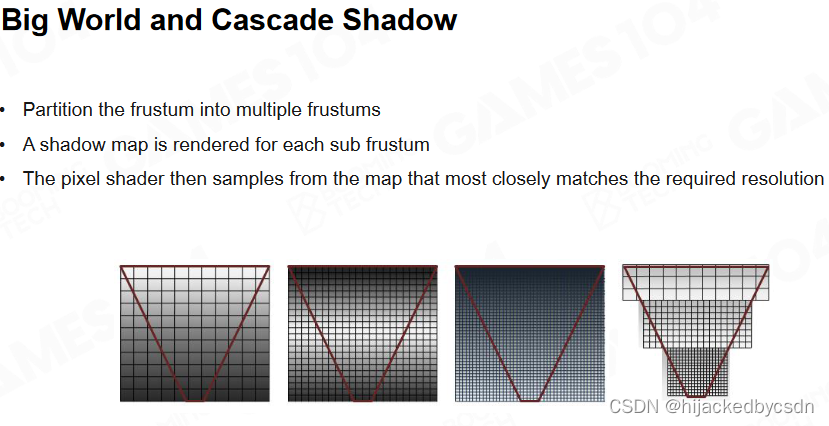
Cascade Shadow
为了解决上述问题,使用 Cascade Shadow 对阴影进行分级处理。在距离人眼比较近的位置,使用高精度纹理采样,远离人眼的阴影使用低精度纹理采样。CSM 将视锥由近到远分割成若干个子视锥,接近摄像机的区域,精度高。之所以要分级是为了减少内存开销,这符合透视原理。
不同层级之间需要处理,否则会有一些奇怪现象

优点:(1)有效抗锯齿;(2)计算快速
缺点:(1)几乎无法生成高精度的 Shadow;(2)Shadow 是没有色彩的
Soft Shadow
PCF - Percentage Closer Filter
1、PCF解决了什么问题
SSM生成的阴影会出现锯齿(shadow map的精度问题),没有AA。PCF实现了对shadowmap的AA
2、PCF如何实现AA
解决锯齿问题的方法有好多,其中最简单的就是在锯齿附近添加黑白之间的灰色,PCF就是实现了这一种方法。
在SSM算法中,物体的实际深度将会与shadowmap的深度进行比较,如果比shadowmap的深度小,则出现阴影。
这里有个问题,就是这种比较结果永远只有两种可能0或者1,这个导致SSM无法进行AA。
PCF利用采样的方法,对shadowmap的特定像素附近的像素进行采样,并取其平均值,这样就可以得到一个0~1的数,也就实现了AA
3、PCF的缺点:
1、无法提前做预处理,一旦做预处理(blur,插值),都会导致shadowmap的特定像素的深度出现误差,由于最后的结果是根据各个像素进行均值,所以这会导致最终阴影也出现误差
2、传统的PCF每一次采样过滤耗费很大(每次都要遍历附近的几个点,虽然用了泊松分布,但还是不可避免),PCSS算法的出现基本解决了该问题(通过动态计算采样范围,使用FindBlocker剔除非阴影点,额….在下面的PCF算法其实也基本实现了这两个)
————————————————
版权声明:本文为CSDN博主「kevin_dust」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kevin_dust/article/details/51903099
Percentage Closer Soft Shadows (PCSS)
将前面的PCF进行推广,如果filter变得特别大那么阴影就变成了软阴影!但是filter到底要如何变大,那一部分变大,变大到那种程度上才能得到最真实的效果?
软阴影的产生就是因为有半影区域的存在,生活中光源不会是一个点,都是有面积的,哪怕是一个灯泡也是有一个小的球面,这也是为什么生活中基本不会有硬阴影的存在,基本都是软阴影。半影区域越大,则阴影约软,反之则约硬。半影区域与光源大小和光源到障碍物的距离关系定义如下: 作者:Oitron-打杂的 https://www.bilibili.com/read/cv15724613 出处:bilibili
阴影距离投射物越近越接近硬阴影,阴影距离投射物越远越接近软阴影。
所以要做软阴影,需要在物体阴影的不同位置上有不同大小的filtering-size,filtering-size与遮挡物与阴影的距离blocker distance有关.
得到了窗口尺寸,那接下来所做的事就和PCF一模一样了。
但是问题也随之而来,因为更大的窗口意味着对于每个着色点,计算量直接飙升并且是以N^2的形式飙升,尽管效果理论上应该不错,但是基本不可能达到实时的要求。
一种简单的处理方式就是进行稀疏采样,即只随机选取窗口内一定数量的值进行计算来代表全局,类似蒙特卡洛采样。同样问题也随之而来,即噪点。如上图,每个窗口只选取20个样本进行计算,尽管20已经算比较大的采样数了,毕竟帧率已经下降到了30.8FPS,但是噪点依旧比较严重。于是乎,VSSM出现了,用以加速PCSS的过程,并且降低噪声。 作者:Oitron-打杂的 https://www.bilibili.com/read/cv15724613 出处:bilibili
Variance Soft Shadow Map
VSSM 的核心思想就是对滤波区域的深度值的分布进行估计,这样就不用具体知道所有区域内具体的深度便能快速的获得分布内的积分即概率。此处的概率即为我们前面提到的可见程度。
最为直接的就是将分布估计成高斯分布,确实也是最常见的一种形式。为了构建高斯分布,我们需要均值和方差。
a. Compute filter’s area mean
为了快速计算滤波区域内的均值(经常刷leetcode的大佬可能已经想到了)可以使用一种常见的数据结构,就是前缀和。二维的情况即是前缀和表,Summed Area Tables(SAT)。所以根据我们的深度图,我们需要生成一张一样大小的SAT,用于快速计算某一区域内的均值。
这时你可能还是会发现一个问题,就是虽然根据SAT得到均值的复杂度为O(1),但是构建SAT的过程复杂度不还是O(N2)。确实,但是我们可以利用GPU强大的并行计算能力使得复杂度从O(N2)降低到O(log(N)),准确说是O(2log(N))。毕竟实时渲染不相信复杂度(闫老说的),所以咋们还是把常数项加上。也就是说,构建一张1024x1024的SAT,原本需要 10241024 = 1048576 次计算,但得益于GPU强大的并行能力可以将计算次数缩减到 10+10 = 20 次。详情可以具体了解一下 compute shader,可以阅读一下OpenGL圣经的第10章,里面就有使用 compute shader 计算 SAT 的范例。链接:
OpenGL Super-Bible: Comprehensive Tutorial and Reference, Chapter 10
https://theswissbay.ch/pdf/Gentoomen%20Library/Game%20Development/Programming/OpenGL%20SuperBible%204th%20Edition.pdf
b. Compute filter’s area variance
均值有了,还需要的就是方差。方差我们也可以很方便的通过均值得到:
均值的平方通过SAT就能很快的获取,但是值平方的均值如何获取?这需要一点小技巧,就是在生成 shadow map(深度图) 的同时生成 square shadow map (深度值平方图), 如果是存储在纹理中,我们可以使用R通道存储shadow map, 用G通道存储square shadow map。一旦有了深度值平方图,同样使用SAT就能快速得到值平方的均值。
c. Compute shade’s area (CDF estimation)
有了均值和方差,意味着能够模拟高斯分布,但是如何计算积分?没有解析解,可以打表,就跟做题一样,但这不但需要额外的存储开销也非常麻烦。所以直接使用切比雪夫不等式进行估计。
切比雪夫不等式
使用切比雪夫进行概率估计
虽然是不等式,但是直接拿来当等式用,毕竟已经做了那么多估计了,也不差这点了。确实会有一些问题,但是问题不大。后面细说。
d. Estimate average blocker depth
但是还有一个问题没有解决,就是PCSS中的第一步。PCSS中的第一步,需要估计d_Blocker,即遮挡物的平均深度。现在虽然能快速获取滤波区域内的均值,但由于不知道哪些像素属于遮挡物,也就无法计算均值。如果还是需要判断每个像素是否是遮挡物,此处还是无法加速。所以根据以下公式继续大胆假设 doge…
计算 Z_occ
我们需要计算的d_Blocker即是公式中的Z_occ。两项均值前的系数均可以通过切比雪夫得到,滤波范围内所有深度的均值也可以通过SAT得到。唯一不知道的就是非遮挡物深度的均值。但是这就死锁了,想要知道非遮挡物的平均深度需要知道遮挡物的平均深度,想要知道
遮挡物的平均深度需要知道非遮挡物的平均深度。实在没招了,继续假设。假设所有非遮挡物的深度都和当前shading point (着色点)的深度相同(这是基于接收投影面在大多数情况都是平面的基础上进行的假设)。如此一来也就能得到 d_Blocker了。
若当前的shading point的深度为 7(此图出自GAMES202课程)
Results:
不同阴影渲染方法的效果和其帧率(最高60)
但是当仔细看VSSM的渲染效果时能发现,当有复数遮挡物重叠的时候,阴影会有漏光的现象。这是由于当有复数遮挡物在一个滤波区域时,真实深度值的分布和高斯分布相差甚远。真实的分布应该更像是复数的冲激,而不是平滑的曲线。而当我们继续使用切比雪夫进行估计的时候,会比真实值大很多,这就导致遮挡物的概率下降,使得阴影比真实值浅。所以看上去就像“漏光”了一样。
3A 级渲染的总结
5 到 10 年前的技术
灯光 Lightmap + Lightprobe
材质 PBR + IBL
阴影 Cascade shadow + VSSM
前沿技术
Shader Model
Compute shader
Mesh shader
Ray-tracing shader
实时光线追踪(Real-Time Ray-Tracing)
对于一个 Ray,如果 Hit 到,可以触发一个回调函数,如果没有 Hit 到,可以触发另一个回调函数
上面讲到的GI算法,其实都不是真实的实时光照处理,它们都有一定的预计算或者很多非常规假设。但在新一代硬件支持下,实时光线追踪的处理方式出现了,虽然现在还没有能够大规模普及,但这项技术已经在突破的边缘。
2018年NVIDIA宣布了可加速硬件中光线追踪速度的新架构Turing,以及搭载实时光线追踪技术的RTX系列显卡。同年,第一款搭载RTX实时混合光线追踪技术的游戏《战地5(Battlefield V)》正式面世
实时GI(Real-Time Global Illumination)
Screen-space GI
SDF Based GI
Voxel-Based GI(SVOGI/VXGI)
RSM/RTX GI
更多复杂材质

Virtual Shadow Maps
Virtual Shadow Maps和Virtual Texture原理很像。Virtual Texture是将游戏中需要用到的所有纹理Pack到一张纹理中,需要使用时就加载调用,不需要时就进行卸载。
Virtual Shadow Maps首先计算哪些地方需要Shadow Map,然后在一个完整虚拟的Shadow Map中去分配空间,每小块得生成Shadow Maps。在计算Shadow时,反向去取小格数据。这种处理方式可以更有效利用存储空间。
Uber Shader
先写一个大的 Shader,然后通过宏定义不同情况下的Shader组合,在编译时生成大量独立的Shader代码
这些编译出的 Shader 都是 Uber Shader 的一个组合
这就是所谓Uber Shader(类似Unity中的Shader变体概念)。这样的好处是,当Shader发生变化时,只需修改组合Shader后重新编译。

因为 GPU 不喜欢分支,SIMD 的架构意味着同一批指令同一时间执行完毕,如果有分支,就要等待那个最晚的分支
所以要把这个分支铺开,也就是生成组合
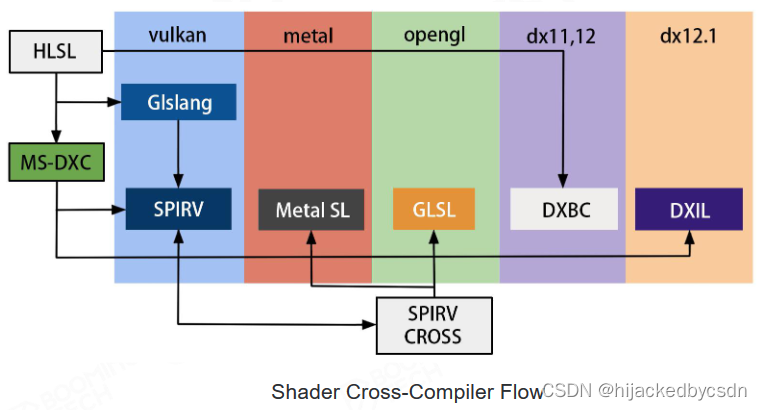
Cross Platform Shader Compile
SPIRV CROSS 提供了跨平台的编译
在写 Shader 的时候
GI 未来会怎么发展
云渲染能不能 kajiya 的问题
十个人在一个地方一个角度去看同一场景,看到的效果是类似的
所以如果能够统一渲染的话就会省
动态日夜光照
不同维度不同高度是不一样的
天球光照是具有分布的
第六节(上) 游戏中地形大气和云的渲染
Real-World Landscape
真实世界在空间上很大,在地形上很丰富
Vegetation 植被
Rivers 河流
Undulating peaks 起伏的山峰
Alpine snow 高山上的雪
如果还要用传统的 Mesh + Material 的思路来做的话就会很难
Environment Components in Games
天空和云
植被
地形
Simple Idea - Heightfield
使用高度图表示地形
地形可以用分形表示
Render Terrain with Heightfield
Adaptive Mesh Tessellation
对于大地图,想要使用高度图对一个很大的 Mesh 变形就不太现实
使用高度图对 Mesh 变形是一个方法,但是如果 Mesh 很大的话,性能就不会好
一般的方法是切分网格,然后使用 LOD
LOD 只是一个大概的说法,具体怎么做也有讲究
一种方法是,只细分 FOV 里面的网格,不细分 FOV 之外的网格
毕竟 FOV 外的网格是我们看不到的
FOV 是可以变化的,而我们是可以保证不管 FOV 怎么变化,FOV 里面的网格的密度是一致的
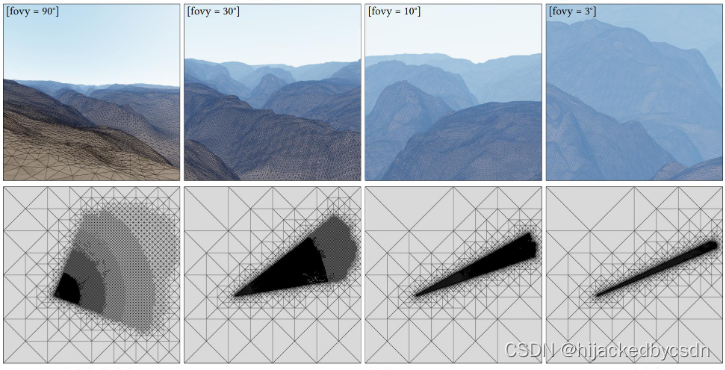
为什么要考虑这个 FOV 的变化?
一般我们在做视角变化,例如望远镜的时候,我们不是真的做了一个望远镜,而只是把 FOV 调小了而已,这样,在屏幕空间看到的物体会变大,但是视场会变小
Two Golden Rules of Optimization
两个优化的黄金准则
1.依赖于摄像机的误差界限
距离一个地方比较近的时候,高度图的误差 0.1m 可能会被看出来
距离一个地方比较远的时候,高度图的误差 0.1m 可能根本看不出
所以误差要求是随着摄像机变化的
具体来说,是依赖于到摄像机的距离以及摄像机的 FOV
Triangle-Based Subdivision
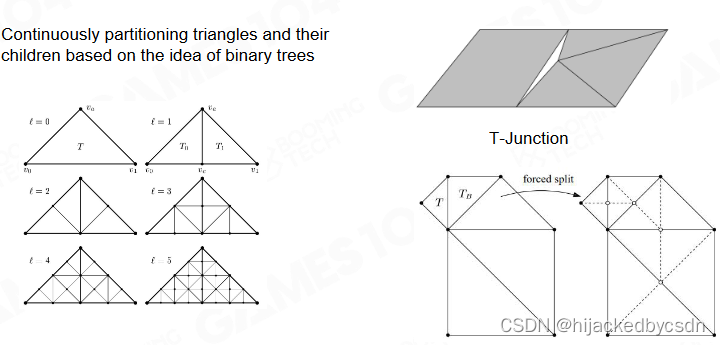
算法思路: 首先将地形分为若干等腰直角三角形,对于精度不够的地形区在等腰三角形的中线位置处一分为二,变为两个等腰直角三角形。(二叉树结构)
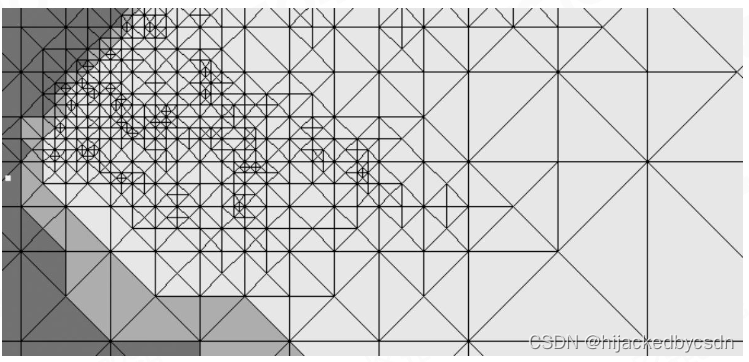
在使用本算法中会出现 T-Junctions 问题,在无穷远处出现白边
就是 T 形结
他这里说的会产生裂缝,意思应该是
T 形结就是多个多边形汇聚在一个多边形的一个边上,这个问题的本质就是在于,多个多边形的交点在一个多边形的边上,这个点的高度和这个边的高度是不一致的,为什么会不一致?边的高度说到底也是这个边的两个端点的高度,这两个端点和那个公共交点是没有关系的
一个直觉是,这个边上似乎有三个节点,但是中间那个公共节点是不属于这个边的
解决方法就是,在这个边的另一边继续切,切到满足这个边也共享这个公共节点为止
但本方法对地形数据的管理,地形的制作方面效果不佳。
它与地形管理的直觉不符,我们一般还是习惯四四方方的
QuadTree-Based Subdivision
一种很直觉的地形表达方式,将地形变为四叉树结构
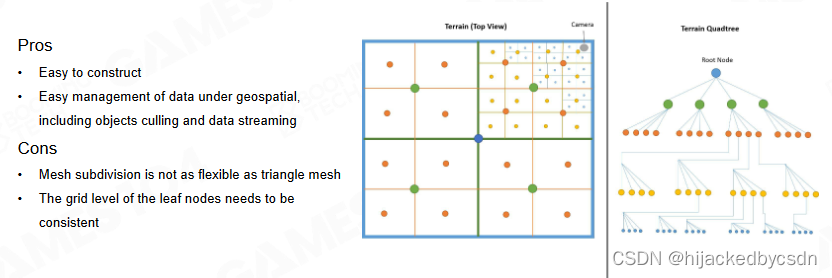
这里也暗含了资源管理的方法,例如 VT
Solving T-Junctions among Quad Grids
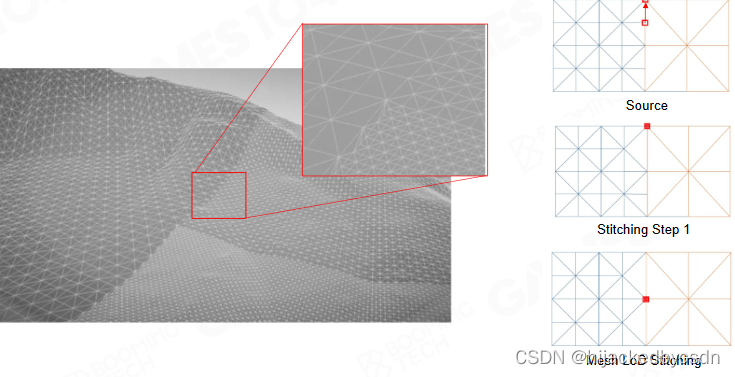
在正方形网格中,解决 T 节点的方法就不像基于三角形的网格中的那样了
因为增加节点就要修改拓扑结构,比较麻烦
它采用一种吸附的方法,把 T 节点中的那个公共节点吸附到边的端点上
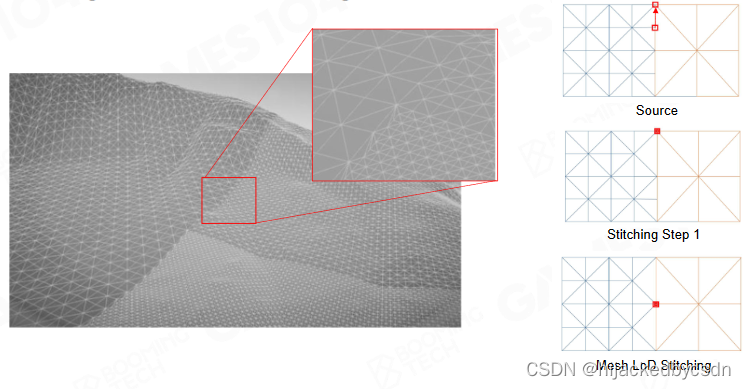
但是我有点不懂的是在复杂的网格会怎么样

我猜可能会这样缩
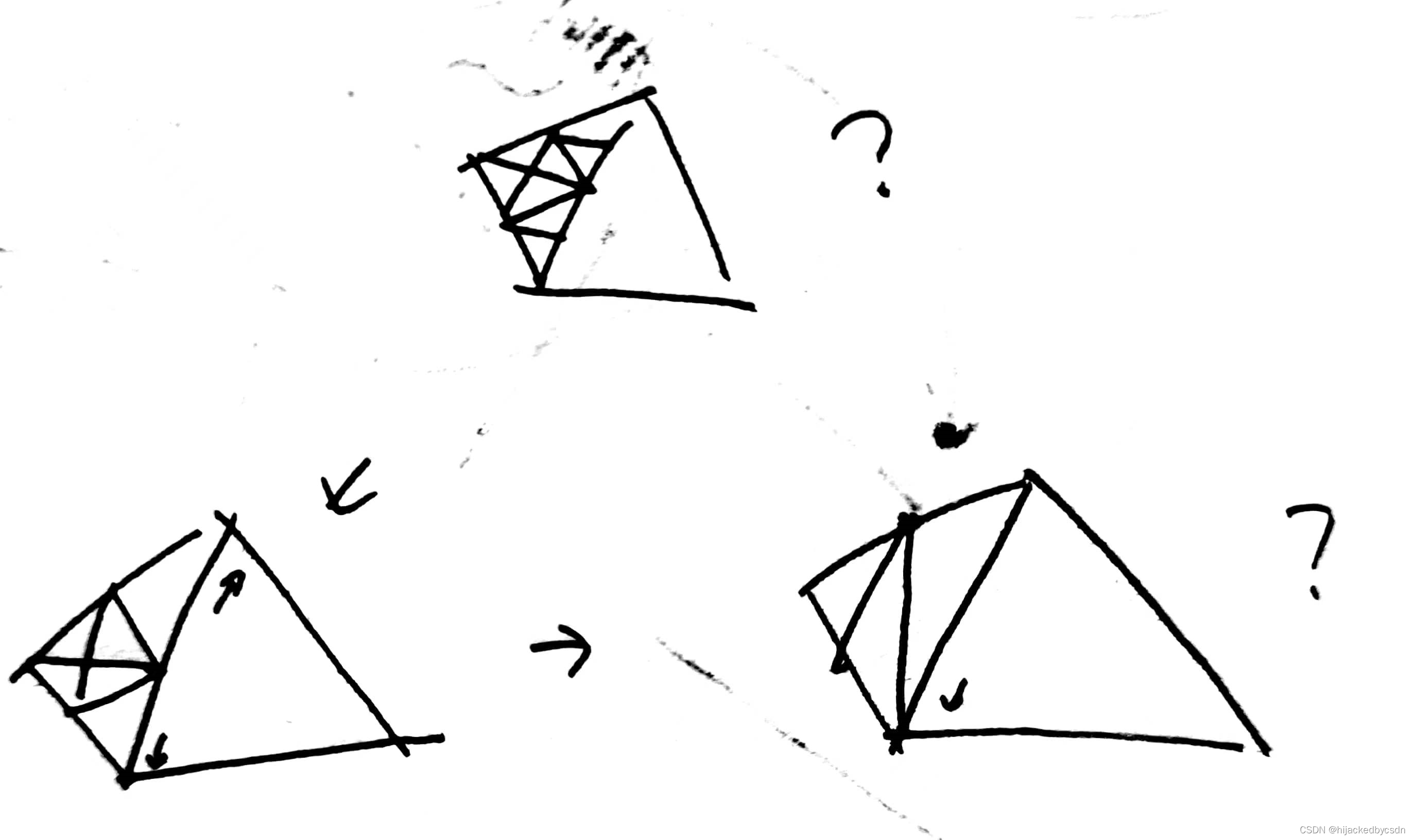
但是这个东西……每一次缩都可能涉及到多个边的合并,这个似乎可以办到……如果能够根据一个点查询这个点的邻边
哦,然后老师说这样不是删除,而是得到了面积为 0 的三角形
弹幕说是,删除节点也要改拓扑结构,也会麻烦,所以干脆就留着这个面积为 0 的三角形
然后也不知道为什么这样缩一定能得到三角面
Triangulated Irregular Network (TIN)
面片简化的思想,这是一种预简化的思想。常用于有大面积平坦区域的地方
优点
1.易于实时渲染
2.在某些地形中运用三角形数量较少
缺点:
1.需要预处理
2.可用性低
为什么自适应细分的网格数量比 TIN 的多?
可以理解为均匀采样与非均匀采样,或者说重要性采样的区别
我感觉肯定有一个方法是可以自动地重要性采样的……?
GPU-Based Tessellation
使用 GPU 来做细分
Hardware Tessellation
以 DirectX11 为例
1)Hull Shader: 生成细分输出面片的顶点,更新所有逐顶点或逐面片的属性值; 设置细分层次因数,以控制生成图元的属性值。
2)Tessellator: 对整个图元几何区域创建采样模式,并根据采样模式生成细分的面片图元。
3)Domain Shader: 对每个域采样计算生成的顶点数据,从而使得细分图元能够接入到流水线的下一步。
————————————————
版权声明:本文为CSDN博主「wowodadai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ifenghua135792468/article/details/106851708/

Mesh Shader Pipeline
DirectX12
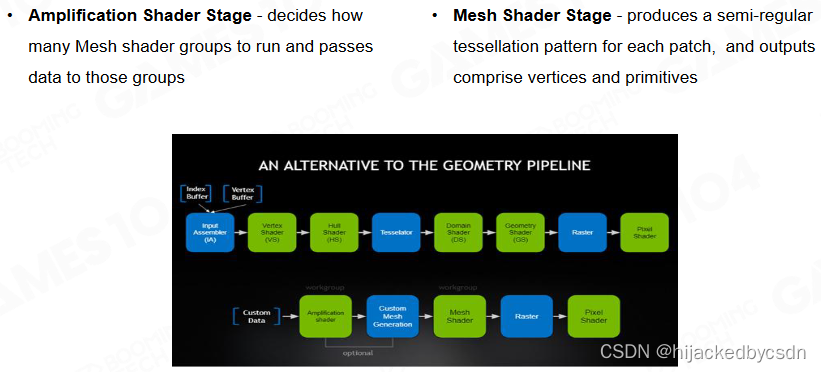
介绍 https://zhuanlan.zhihu.com/p/376856121
Real-Time Deformable Terrain
有多种实现方式
一种实现方式是把地形视为很多个弹簧
一种实现方式是记录一个变形 Texture,在 Shader 中读取这个变形 Texture 作为变形高度
Non-Heightfield Terrain

在地形高度图的顶点上做 NaN 的标记
根据这个高度图生成地形的时候,发现 NaN 的顶点,就会删去与这个 NaN 的顶点相连的所有顶点
点多个 NaN 点会有锯齿状的空洞带
美术在这个空洞带里放置做好的隧道模型
Crazy Idea - Volumetric Representation
如果高度图是三维体素的,就可以不用特殊处理就能生成空洞了
Marching Cubes
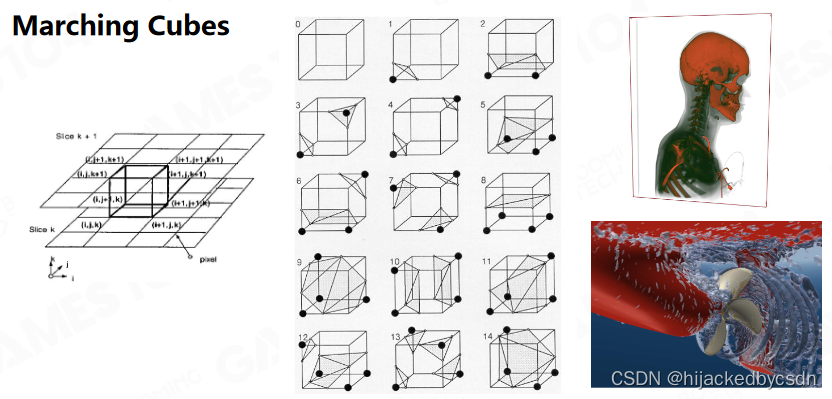
一个介绍 https://blog.csdn.net/AndrewFan/article/details/103440792
一个正方形八个顶点,每一个顶点有两种可能的情况,实点或者虚点
根据实点或者虚点的分布情况,可以找到一个等高面,这个登高面位于实点和虚点之间
八个顶点,每个顶点 0 1 两种情况,总共 2^8 = 256 种情况,这 256 种情况可以由 15 个情况经过旋转,对称变换等操作转变而成
用一个 256 行的表表示三角形的配置情况,直接查表
Terrain Materials
Simple Texture Splatting
简单的材质混合,是连续的但是不真实的

像右图这样的真实场景才是对的
Advanced Texture Splatting
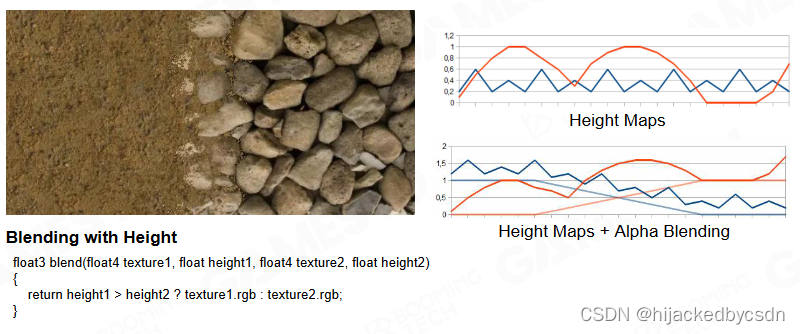
基于真实场景的这种混合,提出了一种基于高度的 hack
如果你的高度比较高,那么你的权重下降得就慢,如果你的高度低,那么你的权重下降得就快
这样就能实现那种沙子入侵到石头缝,但是又不会长在石头上的效果
Advanced Texture Splatting - Biased
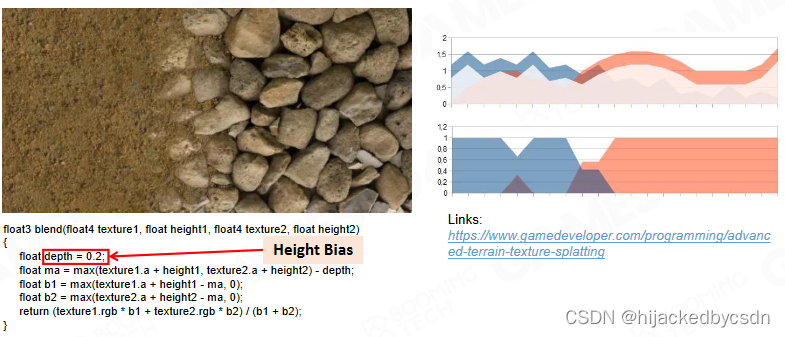
但是基于高度比较的 0 1 判断没有过渡,在摄像机移动的时候可能发生抖动
所以又是一个 hack,在高度判断的时候加一个 bias
假设 texture1.a + height1 < texture2.a + height2
ma = texture2.a + height2 - bias
b1 = max(texture1.a + height1 - (texture2.a + height2 - bias), 0)
b2 = bias
这个时候又要判断
假设 texture1.a + height1 < texture2.a + height2 - bias
那么 b1 = 0, return texture2.rgb
如果 texture1.a + height1 > texture2.a + height2 - bias
那么 b1 = texture1.a + height1 - (texture2.a + height2 - bias)
return 的就是两个纹理的混合
那么其实这种情况就是 texture2.a + height2 - bias < texture1.a + height1 < texture2.a + height2
也就是 texture1.a + height1 与 texture2.a + height2 在一个范围内比较接近的话,就能够发生混合,这个范围就用 bias 来确定
而如果 texture1.a + height1 与 texture2.a + height2 在一个范围内都不接近,那就退化为基于高度比较的 0 1 判断
这也就是把混合和 0 1 判断两种方法混合了起来
Sampling from Material Texture Array
前面说的是两个材质混合的情况
实际游戏中可能出现,在同一个点,有多个材质混合的情况
这个时候要索引到多个材质,每个材质又有自己的贴图,就要用到 Material Texture Array
Texture Array 与 3D 纹理不同,3D 纹理在 Mipmap 采样的时候,在某一个 level 是需要采样上下左右前后,六个点采样
啊不不不,其实是八个点采样
这个所谓上下左右前后不是那种坐标轴的意思……只是老师说是这么说,实际上指的是正方形八个顶点,所以是八个点采样
采样之后怎么插值?一种方法是,先沿着 X 轴插值,有四条边,插值四次,然后沿着 Y 轴插值,有两条边,插值两次,然后再沿着 Z 轴插值,有一条边,插值一次
所以总共是 4 + 2 + 1 = 7 次插值

这叫三线性插值
三线性插值的结果与沿三个轴的插值步骤的顺序无关
Texture Array 层与层之间按照 index 索引,是没有关系的
Parallax and Displacement Mapping

Parallax Mapping
这里粗糙的红线代表高度贴图中的数值的立体表达,向量V代表观察方向。如果平面进行实际位移,观察者会在点B看到表面。然而我们的平面没有实际上进行位移,观察方向将在点A与平面接触。视差贴图的目的是,在A位置上的fragment不再使用点A的纹理坐标而是使用点B的。随后我们用点B的纹理坐标采样,观察者就像看到了点B一样。
https://zhuanlan.zhihu.com/p/164754522
Displacement Mapping
根据置换贴图改变顶点的位置
displacement mapping 实际修改表面的几何信息,而 bump mapping 只影响表面法向量
Expensive Material Blending
对一个 Texture Array 采样确实耗时,但是在早期真的就这么干
因为在 Texture Array 之间跳转,还是需要跳跃地寻址,一会要 1 号材质,一会要 7 号材质等,所以会慢
Virtual Texture
你的包体很大,但是某一个时间你要用到的部分很少,但是你为了用这个很少的部分,就把你整个包体都装入内存,这就很昂贵
这里简单阐述下方案:绘制两遍,第一遍把需要用的的贴图的tile以及自身的UV等等信息输出到rendertarget上,CPU根据RT的数据将资源送到GPU,第二遍绘制才是真正的渲染
大家都说这就是操作系统里面的虚拟内存管理,还是 FIFO 的
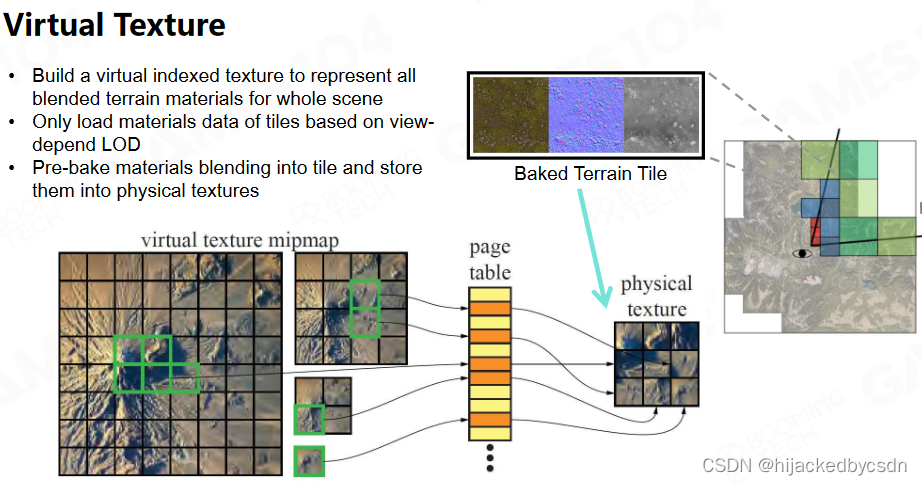
在MegaTexture的基础上,id Software进一步提出了Virtual Texture的概念,这个概念取自于Virtual Memory,与虚拟内存类似的是,一个很大的Texture将不会全部加载到内存中,而是根据实际需求,将需要的部分加载。与虚拟内存不同的是,它不会阻塞执行,可以使用更高的mipmap来暂时显示,它对基于block的压缩贴图有很好的支持。 基本思路是,会将纹理的mipmap chain分割为相同大小的tile或page,这里的纹理叫虚纹理,然后通过某种映射,映射到一张内存中存在的纹理,这里的纹理是物理纹理,在游戏视野发生变化的时候,一部分物理纹理会被替换出去,一部分物理纹理会被加载。
https://zhuanlan.zhihu.com/p/138484024
这里的被存取的 VT 好像是已经烘培好的贴图
VT Implementation, DirectStorage & DMA
VT 的实现,实际上是在硬盘,内存,显存之间调度数据
中间存在一个管理算法,也就是 FIFO 之类的
DirectStorage 将数据从硬盘拿出来,到内存中只是过一下,在内存中是一个压缩的数据,到了显存中解压
这样的好处是,从硬盘到内存到显卡都是传输一个压缩的数据格式,这样的传输效率会高
还有一个技术 DMA,直接从硬盘向显卡写数据
其实计算机组成原理里面也有讲,这个 DMA 当初是直接从硬盘写入 CPU,现在只是直接从硬盘写入 GPU
所以在写逻辑之前可以检测一下有没有 DMA,有就可以用了
Floating-point Precision Error
浮点数本身是有误差的
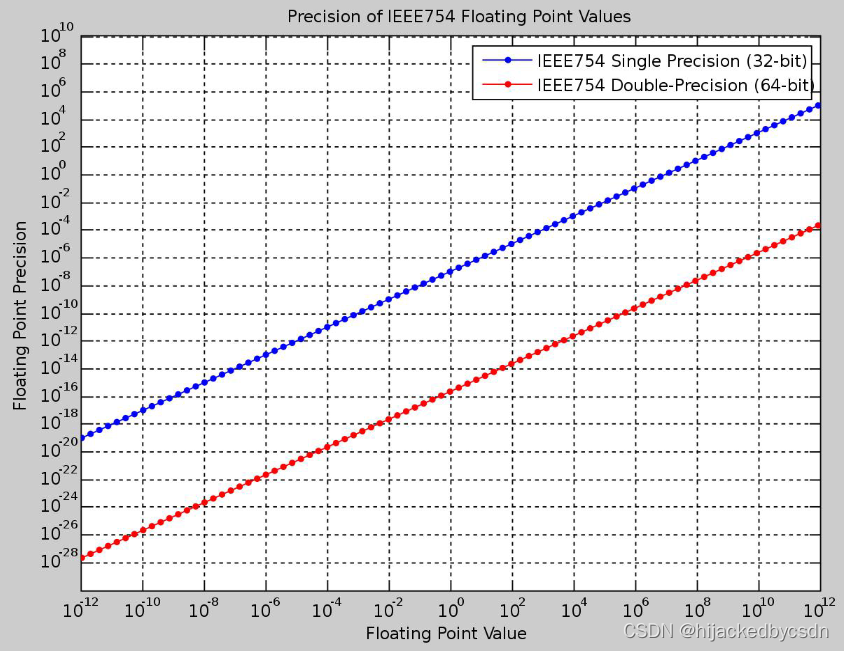
如果我们将相机空间先转化为世界空间坐标下,浮点数精度可能会溢出。
所以我们由此提出以摄像机为准的渲染
Camera-Relative Rendering
先将所有物体的坐标都设置为相对于摄像机的坐标
然后再将摄像机的坐标设为 0,然后再进行投影变换

Tree Rendering
一开始是很多面片,远处就变成 Billboard
Decorator Rendering
Road and Decals Rendering
道路常常使用样条来做
道路做出来了之后,地形需要根据道路来改变,也就是高度场需要改变
Decal 贴花
对于 VT 的话,贴花直接就 Bake 进 VT 里面了
Sky and Atmosphere
Analytic Atmosphere Appearance Modeling

类似 Blinn-Phong 模型,由视角分别到天顶和太阳的两个夹角决定
好处:计算简单
坏处:
-
只能在地表看
-
环境参数不能改
Participating Media
空气的组成介质
各种七题、气溶胶(例如灰尘)
How Light Interacts with Participating Media Particles?
光与大气怎么交互?
吸收,散射,自发光(火焰,闪电)、来自四面八方的光
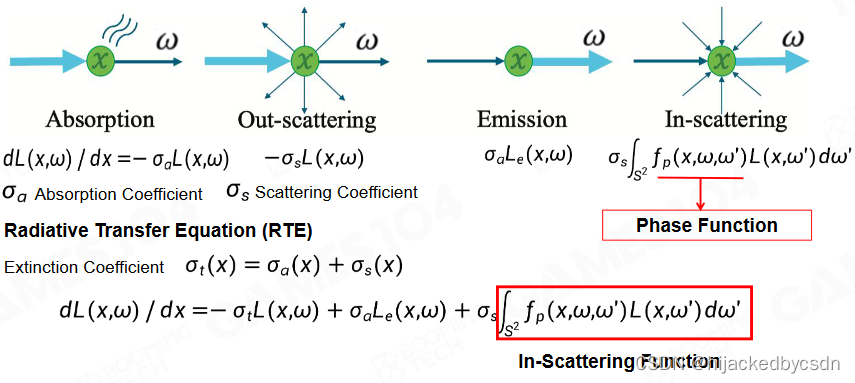
这只是一维方程,在三维空间是梯度方程
Volume Rendering Equation (VRE)
通透度,也就是我在 M 点看到的东西,有多少会保留到我在 P 点看到的东西,这是一个路径积分的结果
scattering part 从 M 点到 P 点的时候,叠加了沿途的所有粒子散射的光
RTE 是一个梯度,RTE 这个梯度的积分就是 VRE
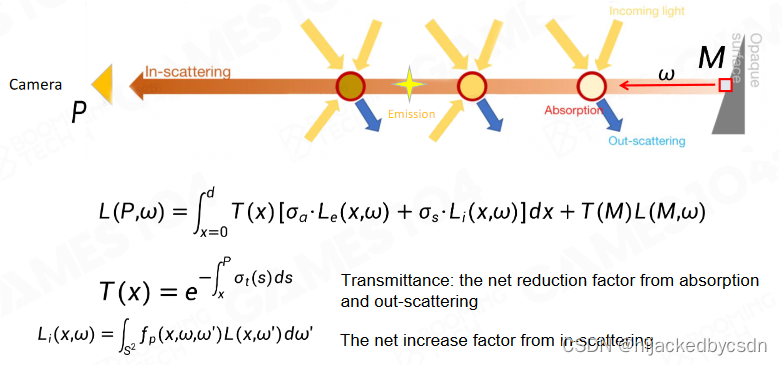
Real Physics in Atmosphere
太阳光是由不同波长的光组成
大气中两类主要组成成分,一类是气体分子,波长小于光的波长,一类是气溶胶,接近于光的波长
Scattering Types
抄的别人的总结 https://blog.csdn.net/qq_33064771/article/details/128489370
两种散射模型
1.Rayleigh Scattering:瑞利散射
空气中介质尺寸远小于波长,几乎四面八方均匀散射
(波长短的散射厉害,波长长的散射越小)
公式和海拔高度,空气密度,入射角有关系
2.Mie sacttering:米散射
接近或者大于波长,就会有一定的方向性
它的散射对光的波长不敏感
Rayleigh Scattering
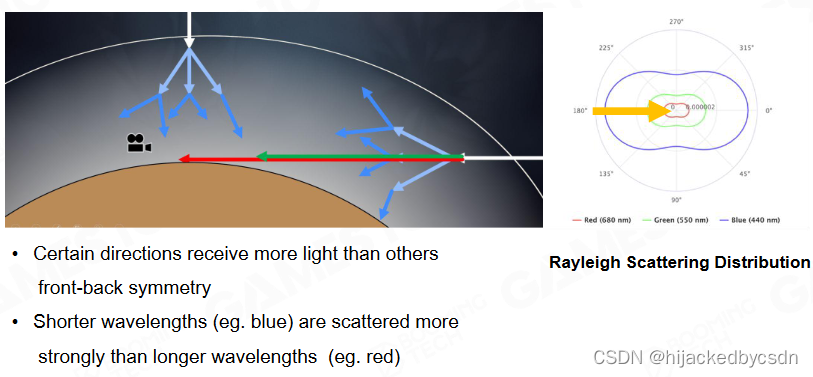
Rayleigh Scattering Equation
这个形状主要就是 1 + cos 2 θ 1 + \cos^2\theta 1+cos2θ
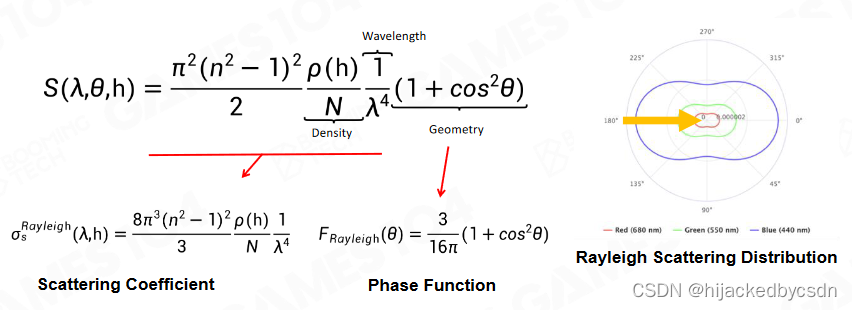
1
/
λ
4
1/\lambda^4
1/λ4 表示波长越短,散射越高
h h h 是海拔高度,大气密度 ρ ( h ) \rho(h) ρ(h) 是随着海拔高度的增大而减小的
Why Sky is Blue
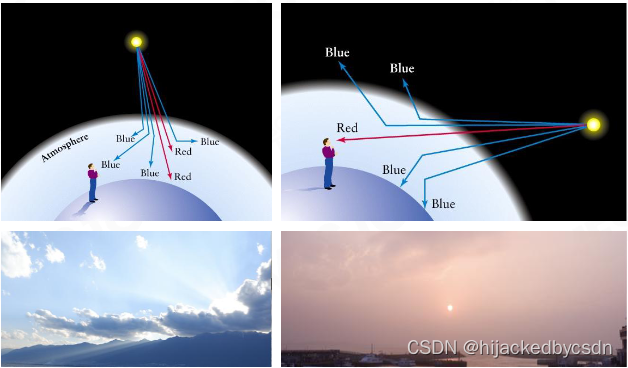
瑞利散射可以解释为啥天空是蓝色的。
白天时,太阳光从天向下照射的时候
蓝光的波长短,散射的厉害,人是水平方向,蓝光光可以入射眼睛
红光波长长,散射的弱,基本上就是垂直落下,人看不见
晚上时,太阳光从前方照射,红光不散射,直接入射眼睛
Mie sacttering
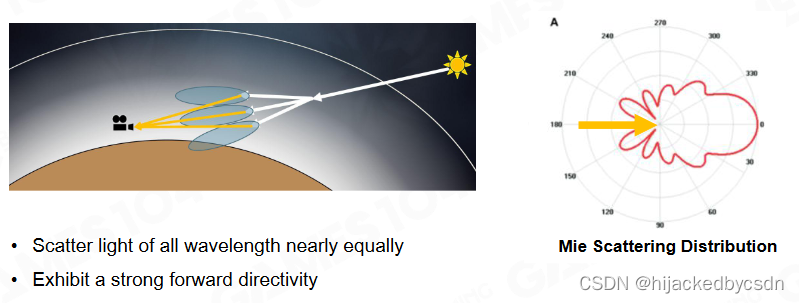
Mie Scattering Equation
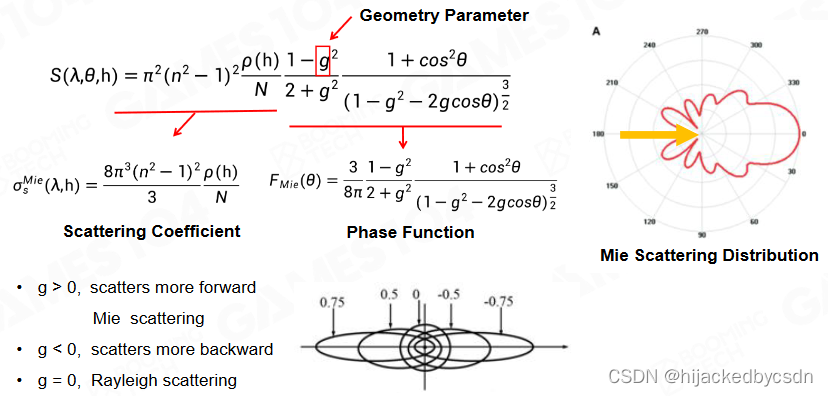
g 是一个控制形状的参数,g = 0 时退化为瑞利散射
Mie Scattering in Daily Life
雾是白色,因为太阳光投射下来,经过米氏散射,所有波长的光都无差别地散射
傍晚看到的太阳光的光晕有一定形状,也是因为米氏散射

Variant Air Molecules Absorption
臭氧吸收长波,过滤掉红色、橙色、黄色光
甲烷会吸收红光
海王星有一层甲烷,吸收了红光,所以看着是蓝色的
实际计算的时候,我们认为臭氧和甲烷是均匀地分布在球面上的,方便计算
Single Scattering vs. Multi Scattering
实际看 VRE 的时候会看到两重积分
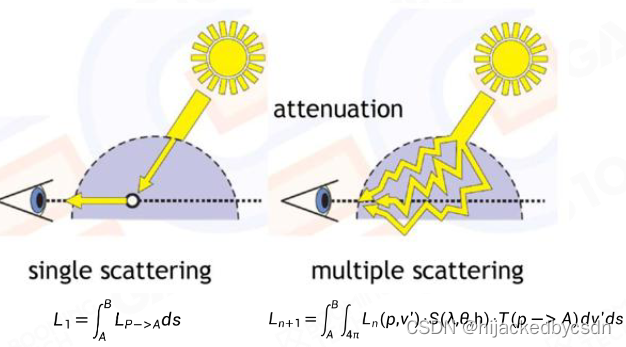
如果是一重散射,也就是光路只有一条路径,也就是单次积分
但是实际上在大气中有多重散射,对多个路径积分,总共就是双重积分

对多个路径积分还是有必要的,例如山的背面的颜色
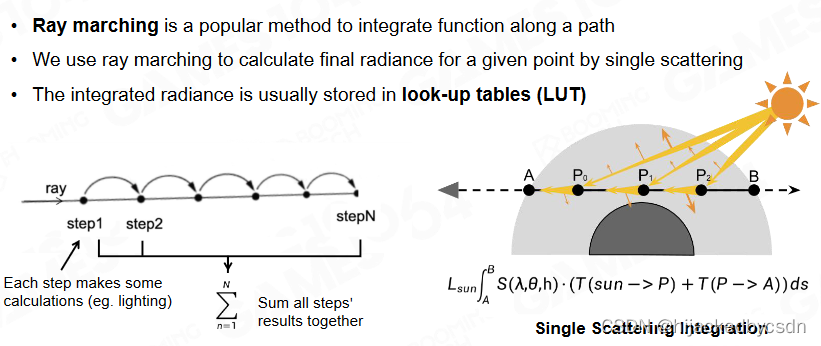
Ray Marching
沿着一条视线,均匀采点,一步一步积分
Precomputed Atmospheric Scattering
把地球表面的任何一个点,计算海拔高度
1.视线和天顶的夹角
2.眼睛和介质一路走到地图边界
优化:空间换时间
算出通透度
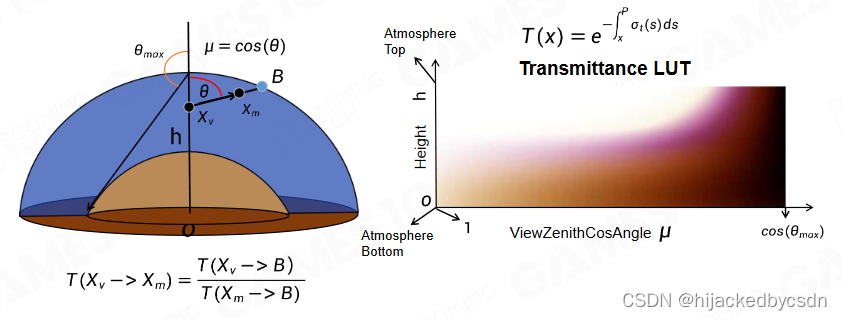
算出通透度之后,就可以使用这个通透度算 Single Scattering
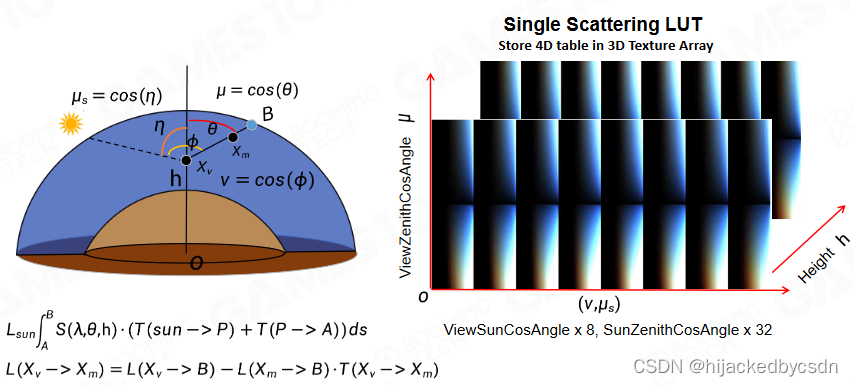
参数化表达
沿着高度 h
-
视线到天顶的角
-
太阳到天顶的角
-
视线到太阳的角
只要天空是齐次的,也就是说旋转变换是齐次的话,那么只需要这三个角就可以表示天空
因为是三个角,所以用 3D Texture,然后不同高度的采样结果对应不同的 3D Texture,非采样点高度就在相邻的两个采样点高度的 3D Texture 的三线性插值的结果之间线性插值
信号是低频的,所以插值没有问题
那高频信号就不能插值?这个可以记一下,不懂
远处的雾效还有一个点是
我先算我看到的大气层的边缘的,散射的能量
从远处的物体过一点的散射的能量
能量又被通透度减弱
这两个能量的差值,就能得到山接收到了多少的天光到我的眼睛
这里完全没听懂……天空这里完全没听懂……
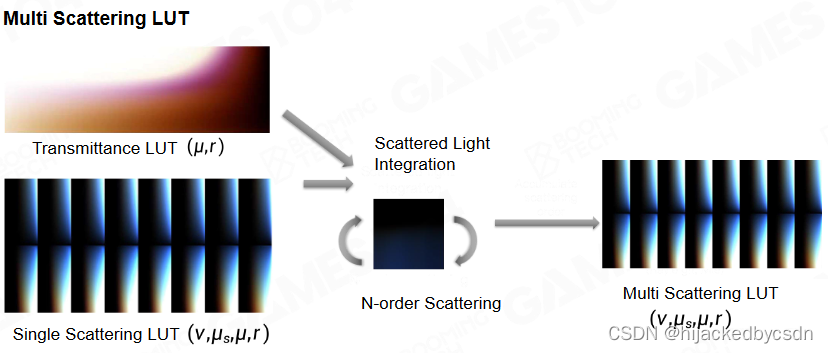
有了通透度的表和一次散射的表,再积分 n 次就能得到多重散射的表
阶数越高,带来的影响就是稍微亮了一点,但是影响会越来越小
Challenges of Precomputed Atmospheric Scattering
计算耗时
因为要查四维的表,插值费时
艺术家说我需要不同的天空的过渡
这就意味着我每一帧都需要查两个天空的表,还要插值
预计算的天空表也不方便艺术家随时调整参数
A Scalable and Production Ready Sky and Atmosphere Rendering Technique
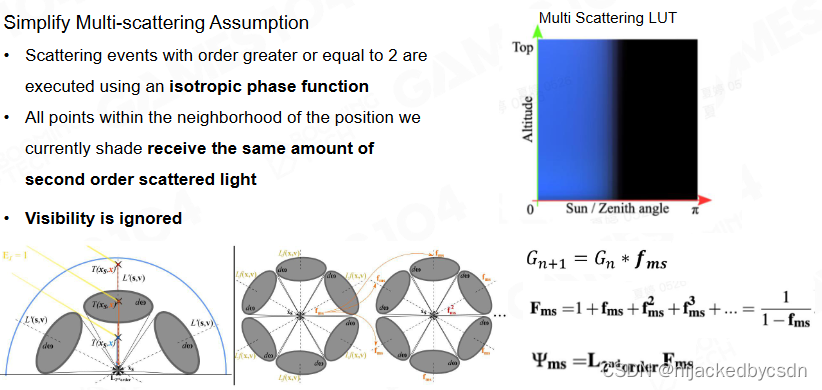
散射近似认为是均匀的,再散射回来就是百分比的衰减,再往上就是,n 次散射就是一个数的指数
在渲染 LUT 的时候,不考虑海拔高度和太阳夹角这两个维度
(但是这样不会降低画面表现吗?)

去掉这两个维度之后,再加上一个距离摄像机的维度,来营造一种空气的透视感
感觉可以类比 2d 中的平行视差层

优点:效率很高,大部分引擎都用这个
在散射很浓的时候误差会大,甚至可能出现色偏
Cloud
Cloud Type
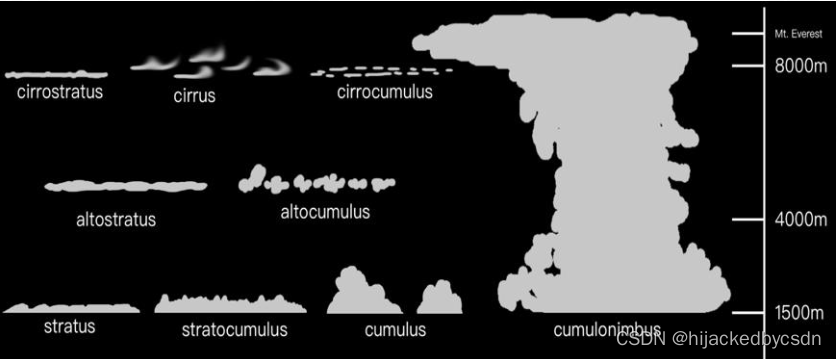
cirrostratus 卷层云
cirrus 卷云
cirrocumulus 卷积云
altostratus 高层云
altocumulus 高积云
stratus 层云
stratocumulus 层积云
cumulus 积云
cumulonimbus 积雨云
Mesh-Based Cloud Modeling
用网格来表达
优点:质量很高
缺点:很昂贵,不支持动态天气

Billboard Cloud
放一些 billboard 贴图
优点:快
缺点:视觉效果稍差
Volumetric Cloud Modeling

全动态用 GPU 生成的,效果好
但是有点昂贵
Weather Texture

一个 texture 加一个厚度,就能表达不同高度,也就是不同厚度的云
云要变化的时候,对 Weather Texture 做平移,云就会飘动,对 Weather Texture 做扰动,云就会变化
Noise Functions
最常用的两个方程
1.PerlinNoise
2.WorleyNoise:空间分隔

用 Weather Texture 确定云的分布,用低频 Noise 确定大概的云的形体,用高频 Noise 添加细节
Rendering Cloud by Ray Marching
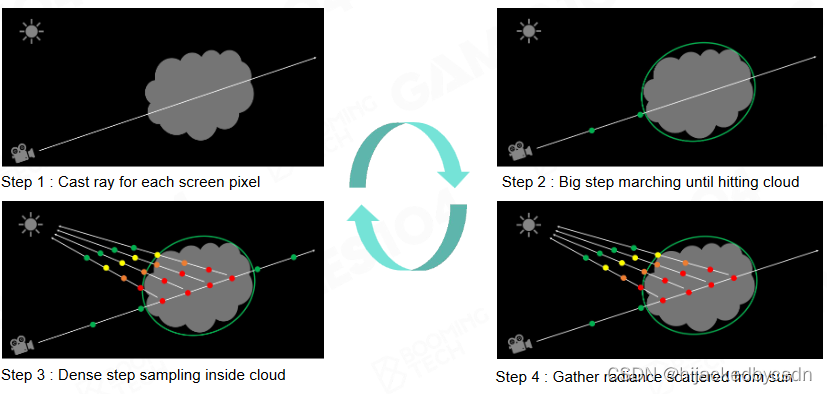
云不会真的形成面片
从屏幕像素点发出射线
一开始的步骤是比较大的,达到第一个云的时候,缩小步骤,在云内的每一个点,算大气的通透和 multi-scattering,这里的 multi-scattering 比较简单,因为云的通透比较低,所以可以做很多假设去化简
QA
地形的四叉树和物体的四叉树可以共用吗
可以
体积云的渲染会不会耗时
是的
是对每一个光线做的运算
对屏幕降采样,或者用 DLSS 也可以减少一点用时
大气散射计算的中止条件是什么
硬性的计算阶数限制,散射几次就行了
第七节 游戏中渲染管线、后处理、和其他的一切
环境光遮蔽
环境光遮蔽概述
在真实世界中,我们常常看到的物体,即使在同样的光照情况下,越突出的物体,他往往看起来就更靓,越坍缩越在深处的物体,它往往看起来就更暗。这非常符合渲染方程的定义。
但是往往在计算机图形处理渲染的过程中,我们无法精确的去表达这个效果。所以提出环境光遮蔽。这个方法。使暗部的物体变得更暗,使亮部的物体变得更亮,让整个画面的明暗关系出现对比,增强立体感。
(在这方面我的理解是,由于人眼对明暗关系的捕捉对尤其对暗部的细节更加敏感。而渲染出来的画面往往在颜色分布中的曲线是线性的,要想更加真实需要去将它变为一条曲线)

环境光遮蔽的原理
(类似于BRDF中的自遮挡项)
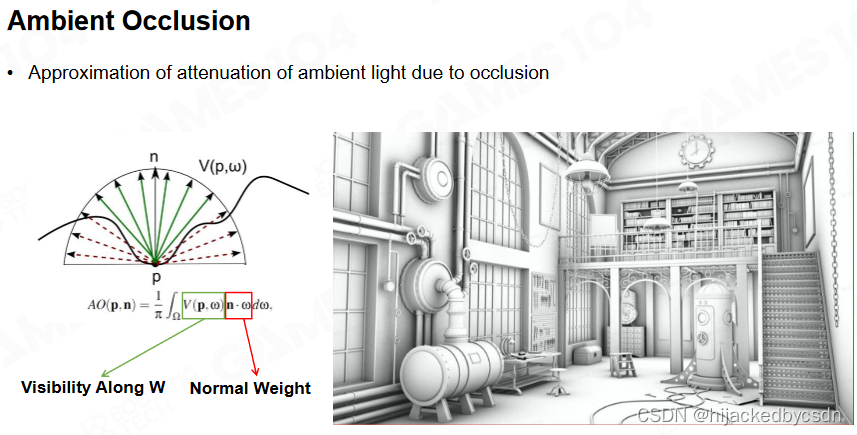
尺度都是相对的,距离地比较远的话,AO 看上去就像 BRDF 中的自遮挡项
Precomputed AO

Screen Space Ambient Occlusion (SSAO)
屏幕空间环境光遮蔽。当我们在渲染的过程中,我们如果进行渲染(深度测试)就会有三维图像的深度缓存信息。其实深度缓存信息就是一张高度图。有了这张高度图,我们就可以根据高度图去计算其自遮挡的信息。
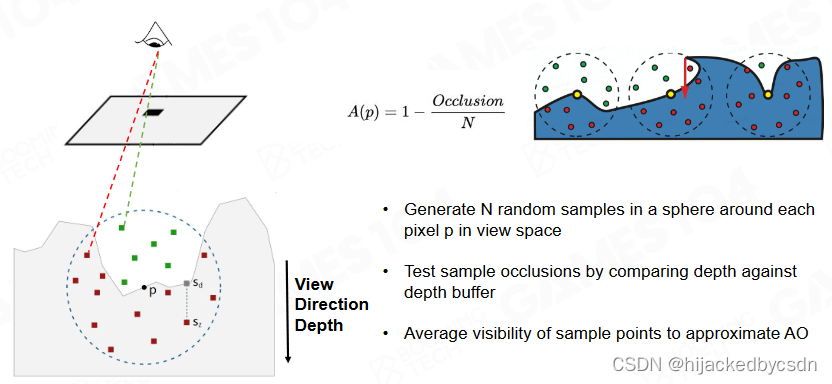
屏幕空间环境光遮蔽的基本原理
首先我们对于空间中的一个点(物体)。以这个点为中心做一个半径为R的圆圈,我们在圆圈里随机放置N个点。再将屏幕空间到我们放置的一个点的距离与获得的高度图的一个深度信息做比较。
A ( p ) = 1 − O c c l u s i o n / N A(p) = 1 - Occlusion/N A(p)=1−Occlusion/N
以上只是空间环境光遮蔽的一个最基本的想法,该想法其实有很多地方有错误,比如:我们是在一个以中心点为半径为 R 的圆圈里随机放置的点,而我们其实要去放置的点是以这个点为中心的一个半球面。如果我们在渲染一个平面的时候。(显而易见的是平面并没有任何环境光遮蔽的因素),但是我们如果按照上述方法去做了平面的一个环境光遮蔽的话,就会发现的自遮挡率始终为 0.5. 但是实际上他应该没有任何的自遮挡。
SSAO+
根据以上提出的问题,我们提出了SSAO+。即我们沿着该点的法向为其中心的向量去做半球面。
https://zhuanlan.zhihu.com/p/46633896
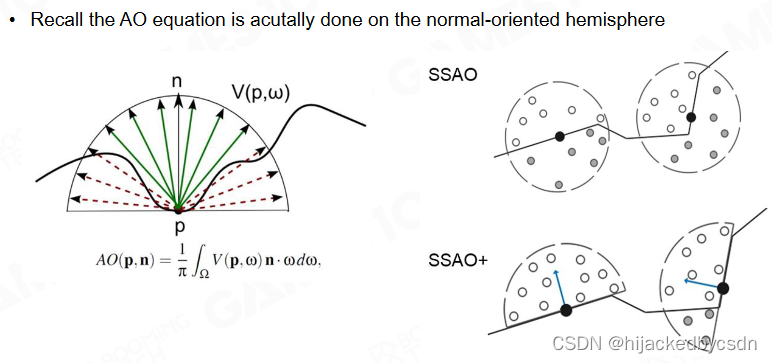
SSAO 的重影
SSAO 的重影是指,物体在距离另外一个较远的物体的地方,本来不该出现遮挡,但是 SSAO 却计算出来有遮挡,造成了不该出现的阴影

HBAO
从一个方向看,仰角要多高才能越过阻挡
在半球 360 度都找这个仰角,最终在半球上可以得到一个遮挡图
最终可以发现,在这个半球上,有多少天顶面积是可见的,有多少面积是不可见的
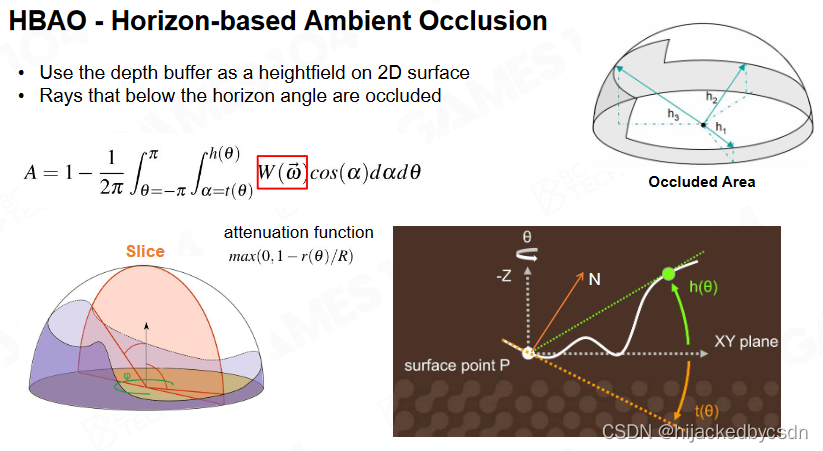
在某一个方向计算仰角的时候,如果击中点距离着色点很远,就认为仰角为 0,这就避免了 SSAO 中的重影的问题
HBAO Implementation
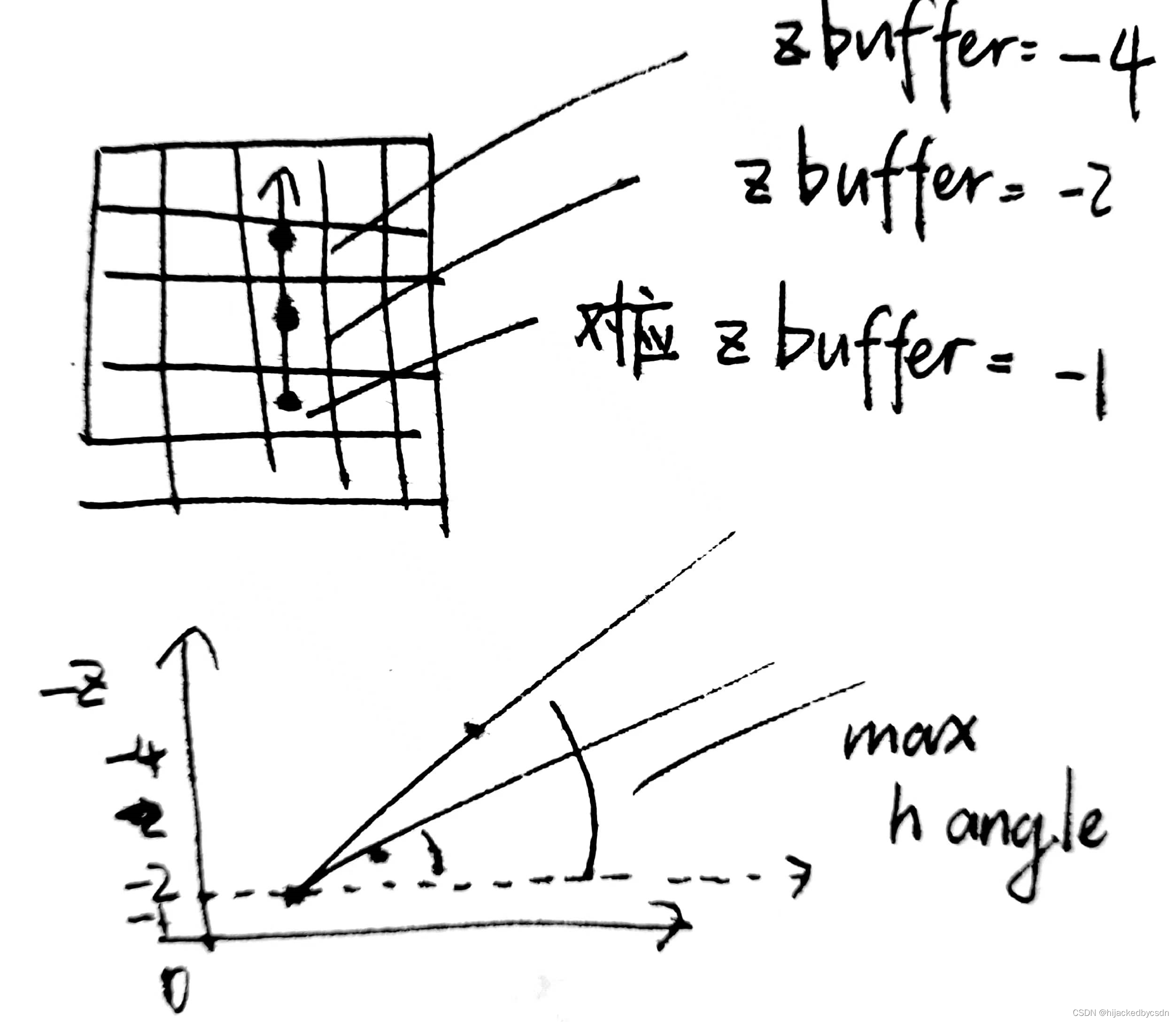
用 Z-Buffer 来判断仰角 horizon angle
在屏幕空间上,从待求点开始,随机取角度,这个角度对应的射线上随机取步长采样,采样点的 Z-Buffer 与出发点的 Z-Buffer 作差,得到的若干个采样点中的最大的 horizon angle
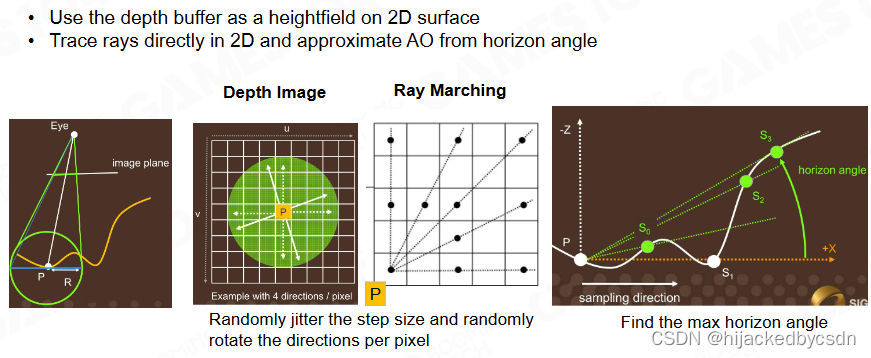
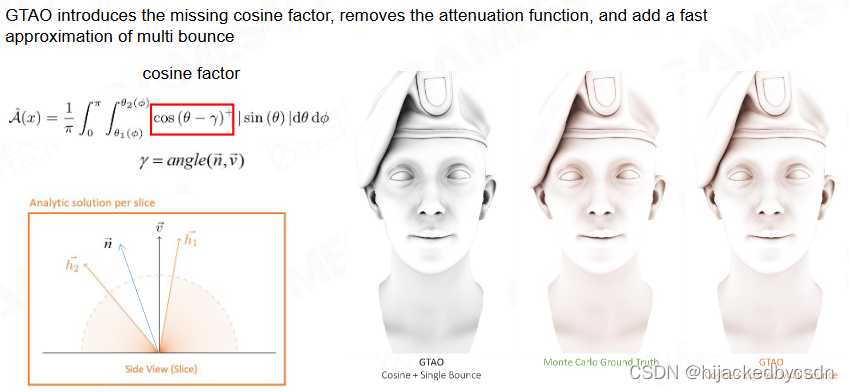
GTAO - Ground Truth-based Ambient Occlusion
如果是垂直击中着色面的光,着色面会百分百散射
但如果是倾斜击中着色面的光,着色面散射的入射光的部分是入射光垂直于着色面的部分
也就是对入射光需要乘以一个 NoL N点乘L
SSAO 和 HBAO 都没有考虑这点
GTAO 基于 HBAO,在 HBAO 中添加与法向相关的因子
根据 AO 值,我还可以猜测光线多次弹射之后得到的结果
他是用机器学习猜出一个多项式
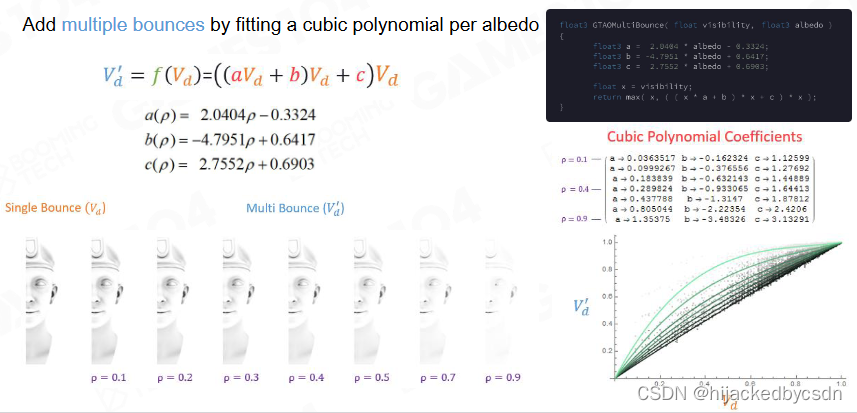
这里的 AO 值也比较像微表面模型中的 Roughness,所以这两者肯定是有关联的
但是我主要是不知道这个多次弹射的光照……他说是能够变成由彩色有色相的 AO,但是我具体也不懂是怎么实现的
他应该指的是,光线在具有颜色的临近表面多次弹射,我只要知道临近表面的颜色,还有多次弹射的光线的光强,就能得到弹射的颜色……
Ray-Tracing Ambient Occlusion
GPU 能够快速做 Ray Casting,那么你就可以用光线相交判断遮挡了
在每一帧,从几个像素射出 Ray
在时序上收集结果
Fog
Depth Fog

用指数平方的效果比较好
Height Fog
空气中的气溶胶会沉淀在底部,所以 Fog 与高度有关是很正常的
因为 Fog 不是匀质的,所以我从一点看向 Fog 一点,视线上各点的 Fog 的密度是不同的
那就只能 Ray Marching,一步步积分
为了简化,认为 Fog 的强度与透明度是线性相关的,所以我只需要对 Fog 的浓度做线性积分就好了
积分得到的结果是一个解析式,当然这个过程中做了简化才能得到解析式
所以现在我看向某一点的时候,我就不用积分了,我直接代入解析式得到值就好了

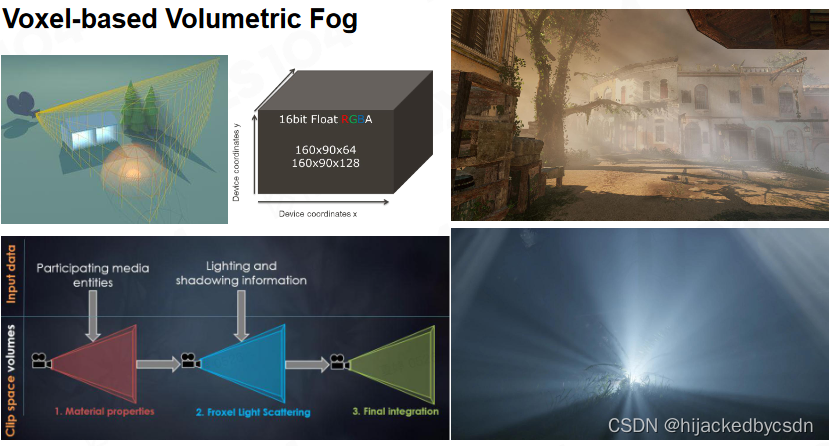
Voxel-based Volumetric Fog
体素化的 Fog
对视锥体做一个不均匀的切分
与算云的方法类似
Anti-aliasing
走样:采样率跟不上信号的变化频率
场景:
几何采样,材质采样,高光采样(物体移动时高光变化很快)
Anti-aliasing
常用的抗锯齿方法是模糊
101 讲过
Super-sample AA (SSAA) and Multi-sample AA (MSAA)
都以四倍为例
SSAA 4 倍的子像素采样,平均四个子像素的颜色
MSAA 虽然还是 4 倍的子像素采样,但是会先判断这四个子像素是不是都在图元中,如果都在就直接是百分百的图元颜色,如果不是再平均四个子像素的颜色
SSAA MSAA 都需要 4 倍的 framebuffer,只是 MSAA 会去掉一些不需要的颜色计算
但是一般复杂场景中的三角形数量会超过你看到的像素的数量
这时 MSAA 会彻底失效,因为所谓的判断子像素是否在图元中,这是在屏幕空间中发生的,也就是每一个三角形占比还不到一个像素,然后它再对四个子像素采样,这四个子像素必定不在原来那个三角形所占的位置上,也就是 MSAA 完全避免不了颜色的平均计算
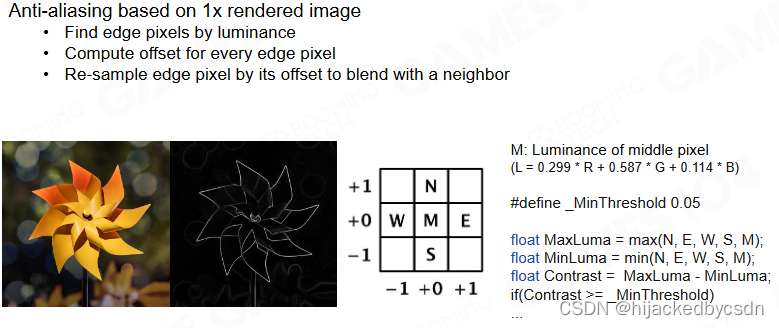
FXAA (Fast Approximate Anti-aliasing)
边缘检测
检测之前先把图片转换到亮度空间
亮度的公式是 RGB 按照一定比例混合
这个比例是经验数值
Compute Offset Direction
根据上下左右点的色差来判断
具体如右侧代码
找到可能为边缘的点
找到这个点之后,需要知道这个点的颜色到底是竖向的变化多还是横向的变化多
因为反走样的目的是自身与那个与自身差别很大的像素混合
于是竖向做一个卷积,横向做一个卷积,得到两个绝对值
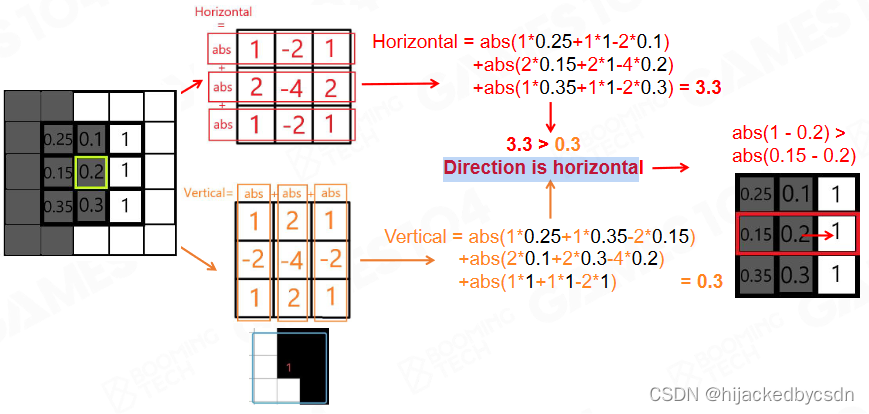
这里假设得到的是横向的卷积的绝对值比较大, 那么再看中心点与左右邻居之间的差异
假设与右邻居之间的差异比较大,那么就得到一个朝向,我应该与右邻居混合
巧妙的一点是,对于一点,我已经只要他要与某一个邻居混合,但是我不着急确定混合比例,我根据这条边的其他部分确定这个边上每一个点的混合比例
怎么让某一个点知道这条边其他点的情况呢?
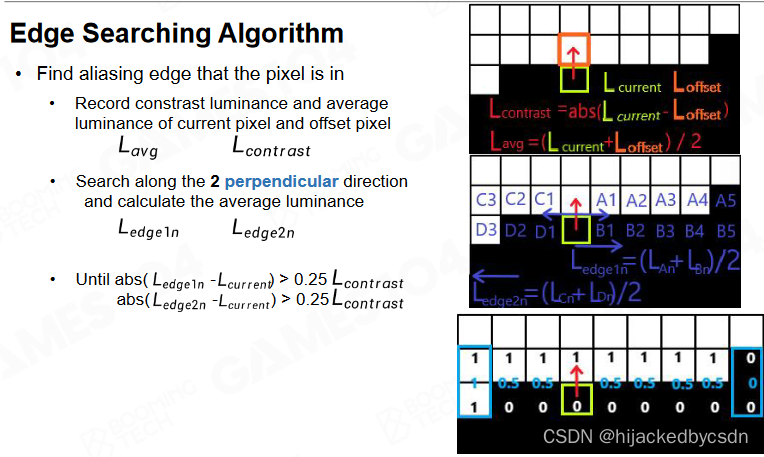
Edge Searching Algorithm
从某一点开始,沿着与该点的混合方向垂直的方向,向这个方向的两端找相同混合方向的点
一直找到颜色变化与该点不同的位置
例如我向上混合,那么我往左右找,找我左手边第一个像素,查看他与他上方的像素的颜色变化是怎么样的,右手边第一个像素同理
例如找到白色的点上方是白色的点,它们之间的颜色变化 = 0,找到黑色的点上方是黑色的点,它们之间的颜色变化 = 0
这时我们就找到了边的两个端点
Calculate Blend Coefficient
然后就可以求出待求点与混合方向的那个点之间的混合系数了
比较左端点到待求点的长度,右端点到待求点的长度
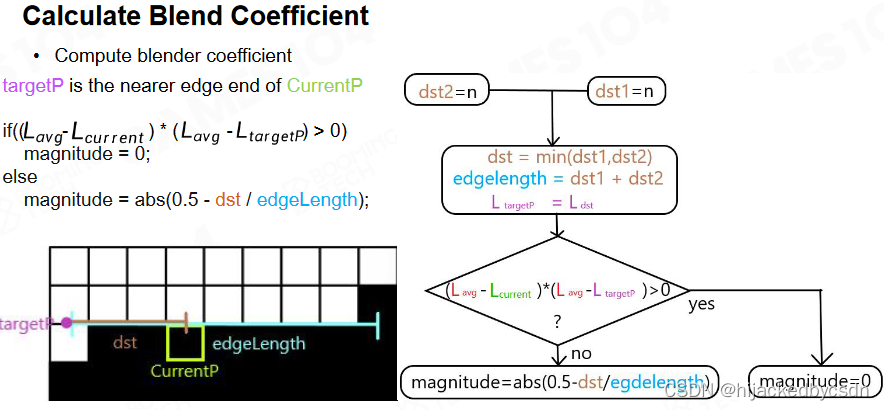
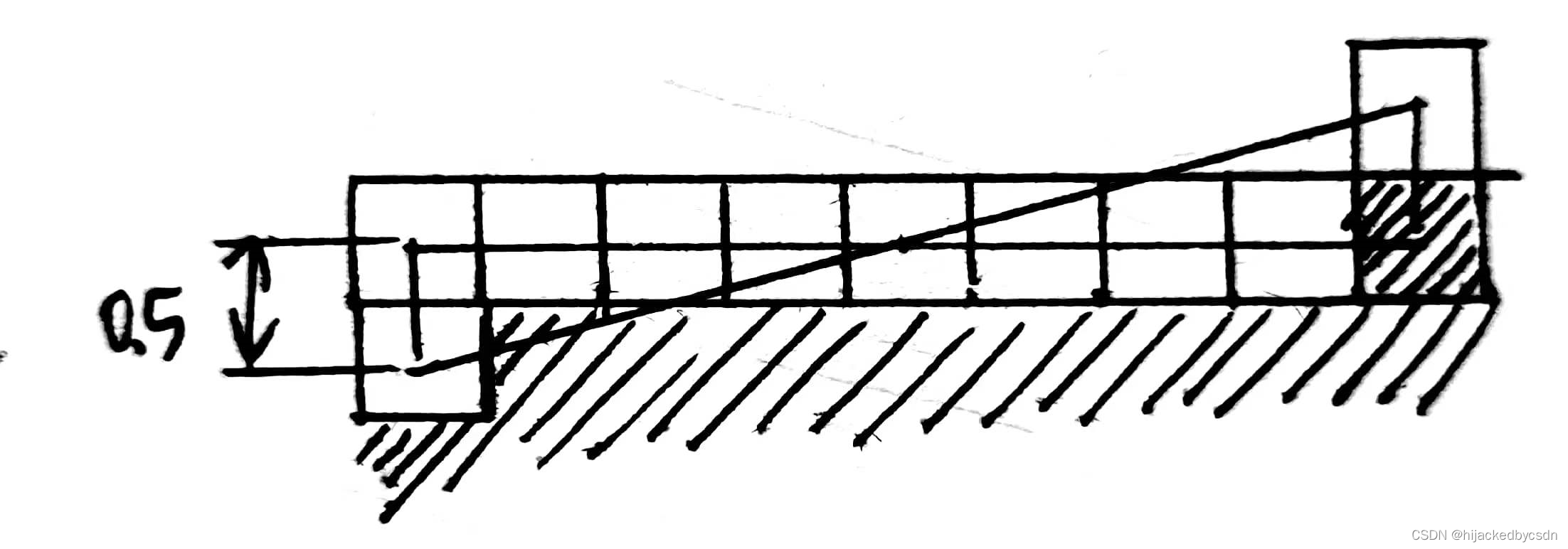
如果这两个向量不是同向的,说明待求点在两个端点之内,那么待求点的混合系数可以通过相似三角形来求
而默认区间的两个端点的混合度是 0.5,那么相似三角形就得到了
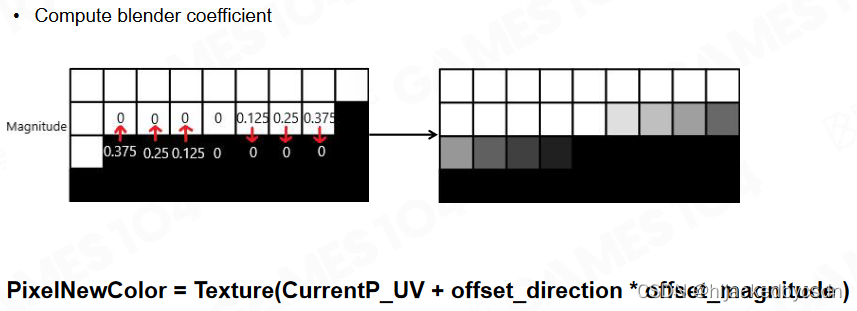
Blend Nearby Pixels
TAA (Temporal Anti-aliasing)
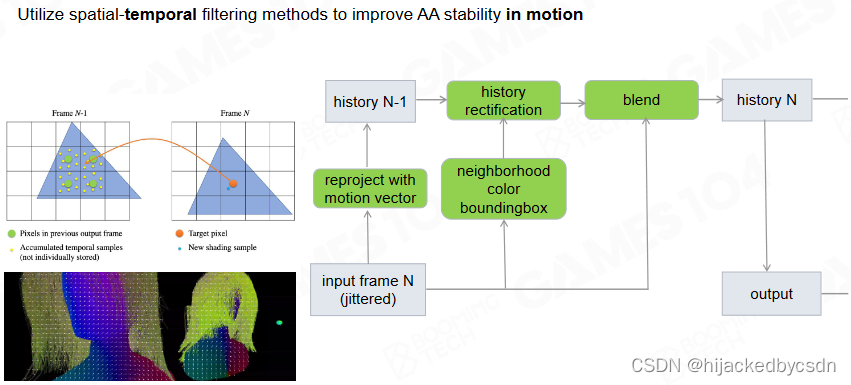
TAA基本原理如下:
1.采样多帧:为了实现更加平滑的效果,TAA需要从多个连续的帧中采样像素信息。通常情况下,它会从前一帧、当前帧和随机帧中进行采样。
2.计算像素偏移量:对于每个像素,TAA会计算其在前一帧和当前帧之间的偏移量,即像素的运动向量。这些向量将用于将前一帧中的像素信息转移到当前帧中。
3.应用运动模糊:为了在前一帧和当前帧之间平滑地过渡,TAA会应用一定程度的运动模糊。这将导致图像变得更加模糊,但是可以通过后续步骤进行修复。
4.重建像素信息:使用前一帧中的像素信息和当前帧中的偏移量,TAA可以重建当前帧中的像素信息。这可以通过对前一帧中的像素信息进行采样和插值来实现。
5.去除运动模糊:由于前一帧和当前帧之间的运动模糊,重建的像素信息通常会显得比较模糊。为了消除这种模糊,TAA会应用一些后处理技术,如锐化和对比度增强。
6.输出最终图像:经过上述处理后,TAA会输出一张更加平滑的图像,其中锯齿和图像抖动现象已经被消除或大大降低。
————————————————
版权声明:本文为CSDN博主「TS.Wang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/GQiqiang/article/details/130450948
但是具体是怎么计算运动向量的我还不懂……
Post-process
Bloom
Tone Mapping
Color Grading
光晕,正确曝光,风格化表达
Bloom Effect
可能的原因
1.人眼不是一个完美的小孔相机,成像不能完美成像到焦平面上
2.光线经过气溶胶,发生了有极向的散射
Detect Bright Area by Threshold
首先取出那些亮度超过阈值的部分

Gaussian Blur
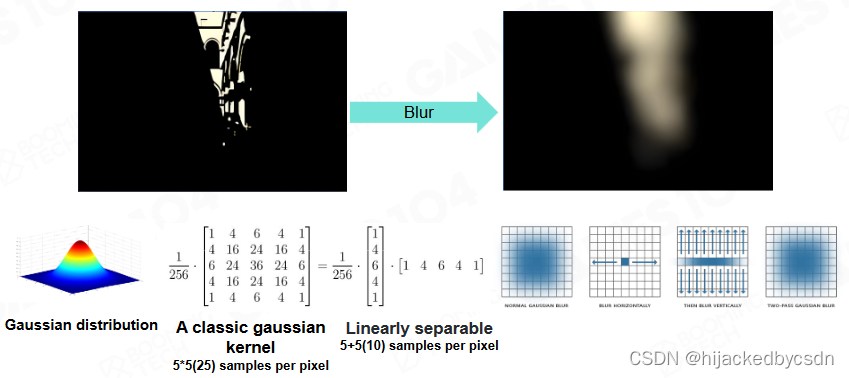
水平模糊一遍
再竖直模糊一遍
得到的就是正方形范围内的高斯模糊
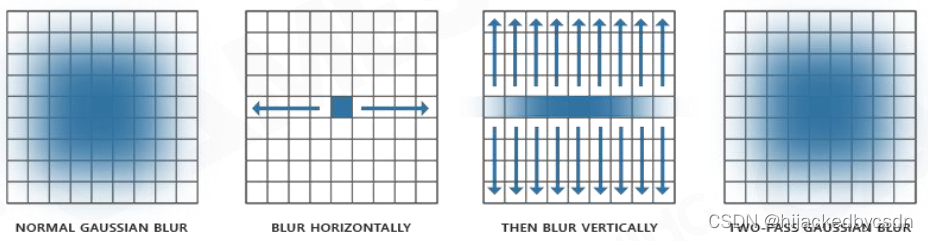
假设原来是以 9 为直径的正方形,原来要卷 81 个数值,现在我只需要卷 19 个数值
说实话没搞懂怎么算的
Pyramid Guassian Blur
先将原图降采样到比较小,然后再做高斯模糊
然后再缩放回原来的大小,在对这个模糊的图放大时,每放大一层,就与同分辨率下的原图相加,得到结果再放大
这样就能得到一个模糊的图,计算也不复杂
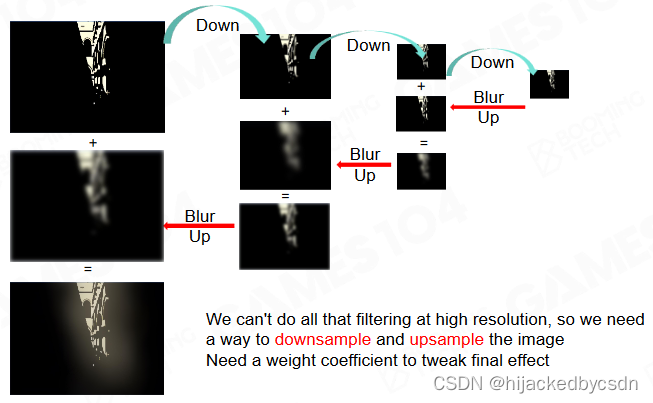
这种类似 mipmap 节省计算复杂度的计算方法也是比较常见
Tone Mapping
没有办法在 SDR 设备中使用 HDR 图像
所以 Tone Mapping 的目的是将 HDR 图像映射到 SDR 空间
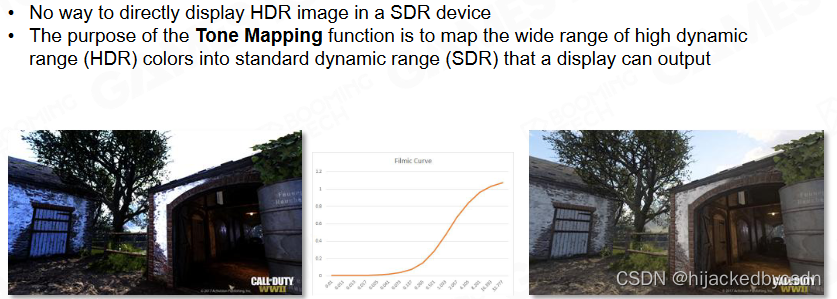
直接使用 HDR 如左图,天空过曝,而暗处出现色偏
出现色偏是因为 RGB 之中有部分值超过了 1,而截断到 1,那么颜色就会出现偏差
映射的思想是,使用一条曲线,将 0 到 40 的值映射到 0 到 1 的值
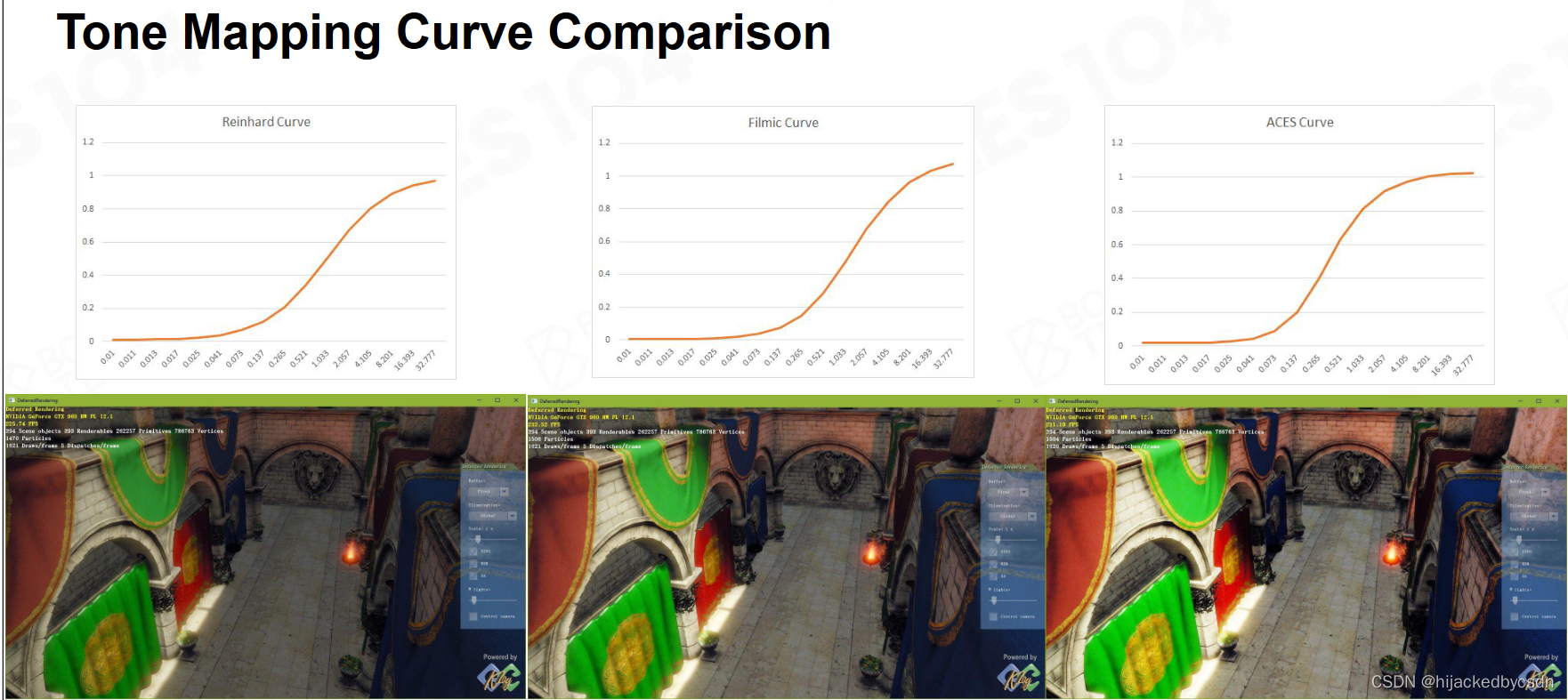
Tone Mapping Curve
1.Filmic s-curve
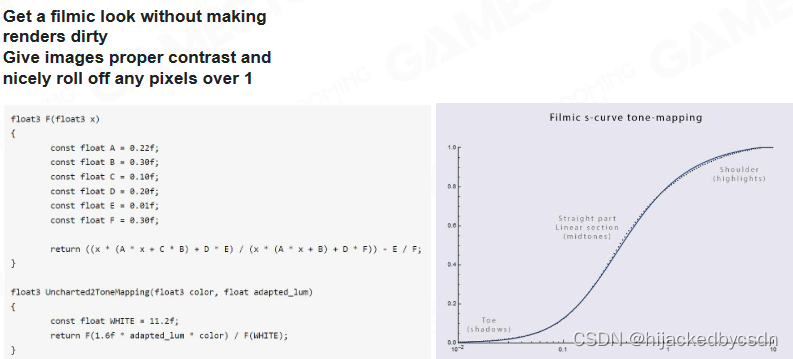
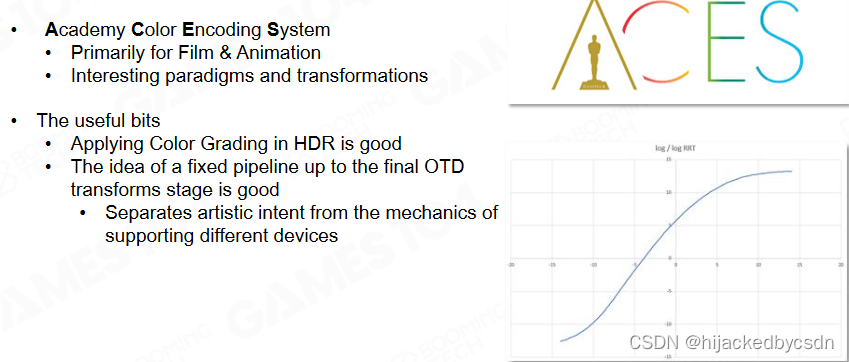
2.ACES
ACES是目前最被认可的颜色曲线,能够有效得在各种终端有稳定的显示效果。
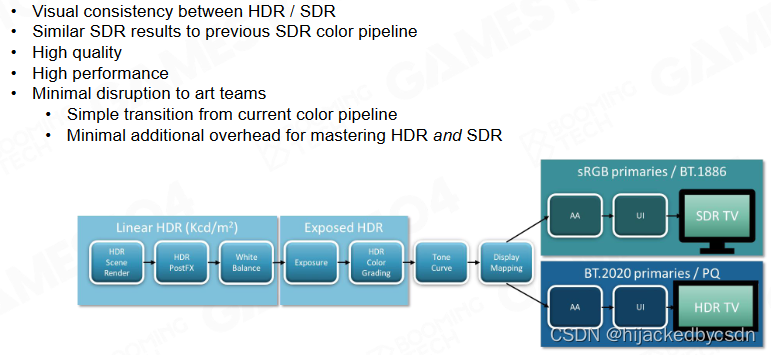
HDR and SDR Pipeline
Tone Mapping Curve Comparison
Color Grading
Lookup Table (LUT)
原始的色彩空间到我想要的色彩空间的映射
LUT 3D or 2D
但是颜色空间有三个维度
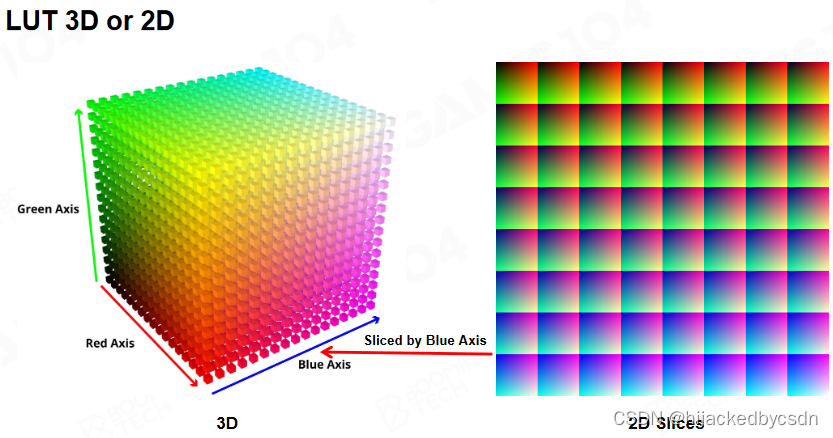
所以 LUT 可以是 3D 的
但是不一定需要 256 * 256 * 256 可以只用 16 * 16 * 16 或者 32 * 32 * 32
因为颜色是连续的,只需要知道大概的颜色,进行插值就行了
Artist Friendly Tools
艺术家在 PS 中拿着原图和调色过的图,就能用 PS 生成 LUT
Rendering Pipeline
这么多算法,需要有一个先后顺序的规则
最简单的
先算 shadow map,把物体放进入 shading,再进行后处理,做 bloom,tone mapping, color grading
Forward Rendering
for n meshes
for m lights
color += shading(mesh, light)
有些物体是透明的,必须要最后绘制
不透明物体挡在透明物体前面,那么透明物体被挡住的部分就不需要绘制
透明物体之间的绘制顺序也需要排序
两个透明物体放在一起,需要先画后面的透明物体,前面的透明物体的才能画对
例如这张图,经典,
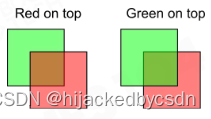
但是有些时候,透明物体之间的排序是解不了的

我记得 101 拿这个做例子,说的是按照像素的 Z-Buffer 来算遮挡关系,而不是对整个物体排序
不知道这里会不会这么做
我也看到了有的研究岗位是与顺序无关的透明物体绘制,好像是在网易看到的
Deferred Rendering
现代游戏有很多光照,所以我们提出延迟渲染的思想。延迟渲染机在渲染的过程中将渲染过程放置在深度测试之后面。我们仅仅需要对摄像机可以看得到的部分进行渲染。
for each object
write G-Buffer
for each pixel
gbuffer = readGBuffer(G-Buffer)
for each light
computeShading(gbuffer, light)
我对每个物体,我先不 Shading,先把每个物体,获得法线深度等等信息写到 G-Buffer 里面,不渲染物体与光之间的关系,然后再对 G-Buffer Shading
好处:
光源只对
容易 Debug
坏处:
G-Buffer 很费
Tile-based Rendering
为了去解决移动端发热问题,又提出了Tile-based Rendering。因为移动端发热的原因是主要来源于存储芯片的消耗。
所以我们在主板上会设置DRAM,DRAM的存储空间比较大,但是在它上面存取数据的速度比较慢,同时存取数据的消耗能量也比较大,但是我们在他的chip里边去做一个SRAM,SRAM的特点是它的存储空间比较小,但是存储数据的速度跟消耗能量都比较低,我们去将整个手机的画面去切分成小块一小块的。虽然画面我们每次只渲染出一小块的区域,最后将它们结合在一块。
也就是为了快速读写,把画面拆成小块
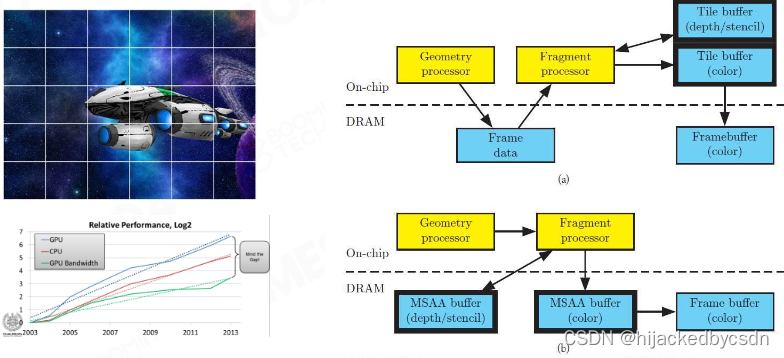
Light Culling by Tiles
分割画面成一小块一小块还有一个好处是
我可以知道每一个 Tile 里面有多少光源
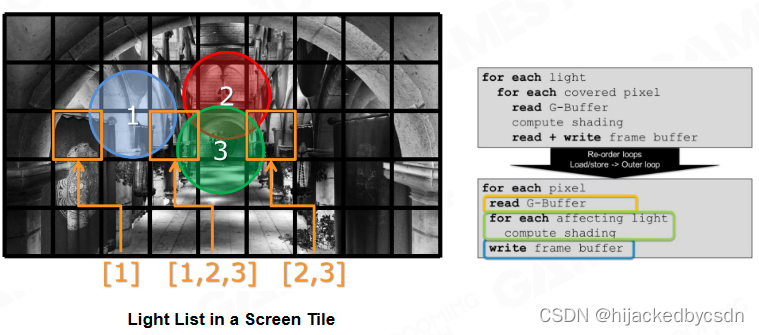
Depth Range Optimization
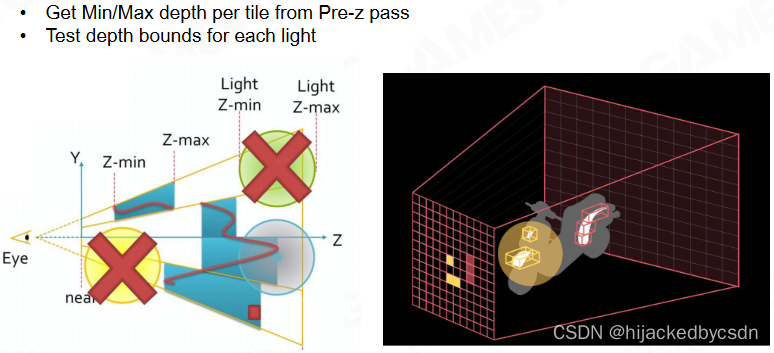
分割画面成一小块一小块还有一个好处是
我可以知道每一个 Tile 里面最远和最近在哪里
又因为我知道每一个 Tile 可能会被几个光源照到
所以我就可以根据 Tile 的 Zmin 和 Zmax 来判断,自己虽然在某个 light 的覆盖范围内,但是从深度来看,我可以判断自己实际上是否会被这个 light 照到
Forward+ (Tile-based Forward) Rendering
虽然是 Forward Rendering,但是是 Tile-based
对移动端特别友好
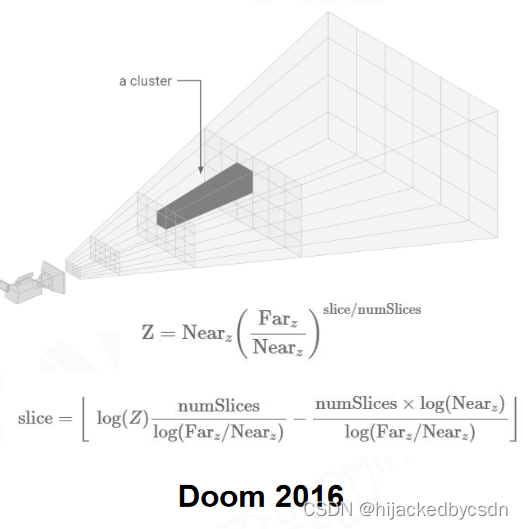
Cluster-based Rendering
将视图空间划分为多个四棱锥(Cluster),每个Tile单独计算Light的可见性。
一个 Tile 一个 Tile 去算可见性
Visibility Buffer
G-Buffer 本质是用一个巨大的 Buffer 存材质信息
但是随着硬件的发展,我们意识到,我们可以把几何信息与材质信息分开了
V-Buffer 存深度,存三角形 ID,存重心坐标,这些几何信息配合材质信息就可以做 Shading
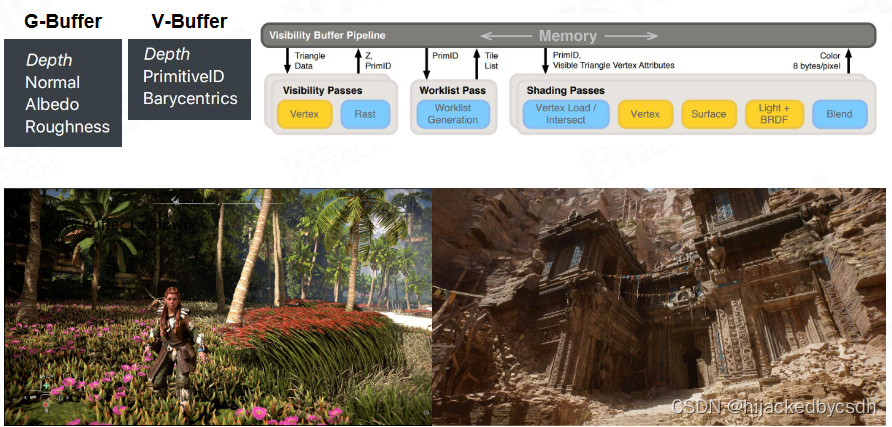
这个变化主要是因为,以前以为材质是复杂的,几何是简单的
但是现在是几何密度大于像素
以前硬件光栅化的时候,硬件一批批取几何的顶点信息,然后 Shading,现在发现,我在 GPU 里面编程,人为写 V-Buffer,速度不比硬件取几何的顶点信息慢
还有一个原因,如果只有一个 G-Buffer,那么在查询材质的时候很费
但是有了 V-Buffer 之后,知道 V-Buffer 中的 id,或者说 vd(我猜的……?视频中也没讲 vd 是什么),根据这个 vd 再去查 primitiveID,就会很快(具体是查什么我也不知道,但是我觉得是这个意思?)
用了 V-Buffer 也可以支持更多的材质,而使用 G-Buffer 一般假设材质是一致的

unreal_schematics
Unreal 给出的知识路线图
https://github.com/drstreit/unreal_schematics
挑战
引擎的不同模块怎么搭配
内存怎么管理。小模块里面方便管理,但是当管线变得复杂的时候就很难管理了
新一代的图形 API 把底层硬件的功能开放出来,这个内存也要自己管理,也要自己加锁,也要防死锁
复杂的并行工作需要与复杂的资源依赖性同步
大量生命周期小于一帧的瞬态资源
复杂资源状态管理
不需要大量的用户低级知识,就可以利用新暴露的 GPU 特性
Frame Graph
使用一个有向无环图,定义好依赖与输出,来管理模块
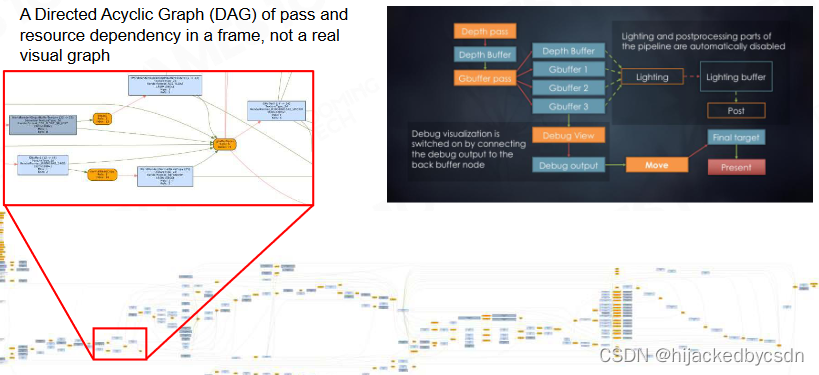
Render to Monitor
Screen Tearing
显示器刷新的频率是一定的,但是游戏的渲染帧率不一定稳定
所以如果写到一半才刷新的话,渲染帧又慢了的话,就可能导致画面撕裂
V-Sync Technology
用垂直刷新同步缓冲区交换
但帧率降低,鼠标延迟和 stuttuer 卡顿会破坏游戏体验
Variable Refresh Rate
显示器的更新频率可变,跟随游戏的渲染频率
QA
在开放世界中 cluster 怎么划分呢
世界锥
frame graph 是一个高层的功能还是底层的功能
底层的
中间层,管理依赖的,管理资源的依赖性与拓展性也是需要保证的
TAA 怎么去除鬼影
运动向量太远了,或者颜色差别太大了,就暂时不执行

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









