







《Ten Years of Pedestrian Detection, What Have We Learned?》发表在ECCV2014 Workshops,Benenson整理了在Caltech测试基准上公布结果的40多种行人检测算法(截至2014年7月),并从多个角度进行了分析,是一篇了解行人检测发展现状的好文章。
本文是一篇读书笔记,根据个人理解进行了整理。
行人检测数据集
行人检测常用的数据集有INRIA、ETH、TUD-Brussels、Daimler(Daimler stereo)、Caltech-USA和KITTI。
INRIA是最早的数据集,相对其他数据集包含的图片较少。INRIA的优势在于高质量的标注和丰富的背景(城市、海滩、高山等),经常被用来训练。
ETH和TUD-Brussels是中型的视频数据集。
Daimler全部是灰度图,缺少色彩通道,一般不被使用。
目前Caltech-USA和KITTI是行人检测的主要测试基准。两个数据都比较大并且具有挑战。Caltech-USA的使用更频繁,已经有大量的方法在上面进行评估,而KITTI的优势在于它的测试集更多样化一点。
Daimler、ETH和KITTI提供三维信息。除了INRIA外,所有的数据集都是从视频中得到的,因此可以使用光流作为附加线索。
关于数据集更详细的讨论请查阅
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2012)
Dollar, P., Wojek, C., Schiele, B., Perona, P.: Pedestrian detection: An evaluation of the state of the art. TPAMI (2011)
行人检测算法整理
Benenson整理了在Caltech测试基准上公布结果的40多种行人检测算法(截至2014年7月),其中约有三分之一的算法是在2013年公布的。类似的,KITTI数据集上有一半的行人检测结果是在2014年提交的。这反映了人们重新激起对行人检测的兴趣。
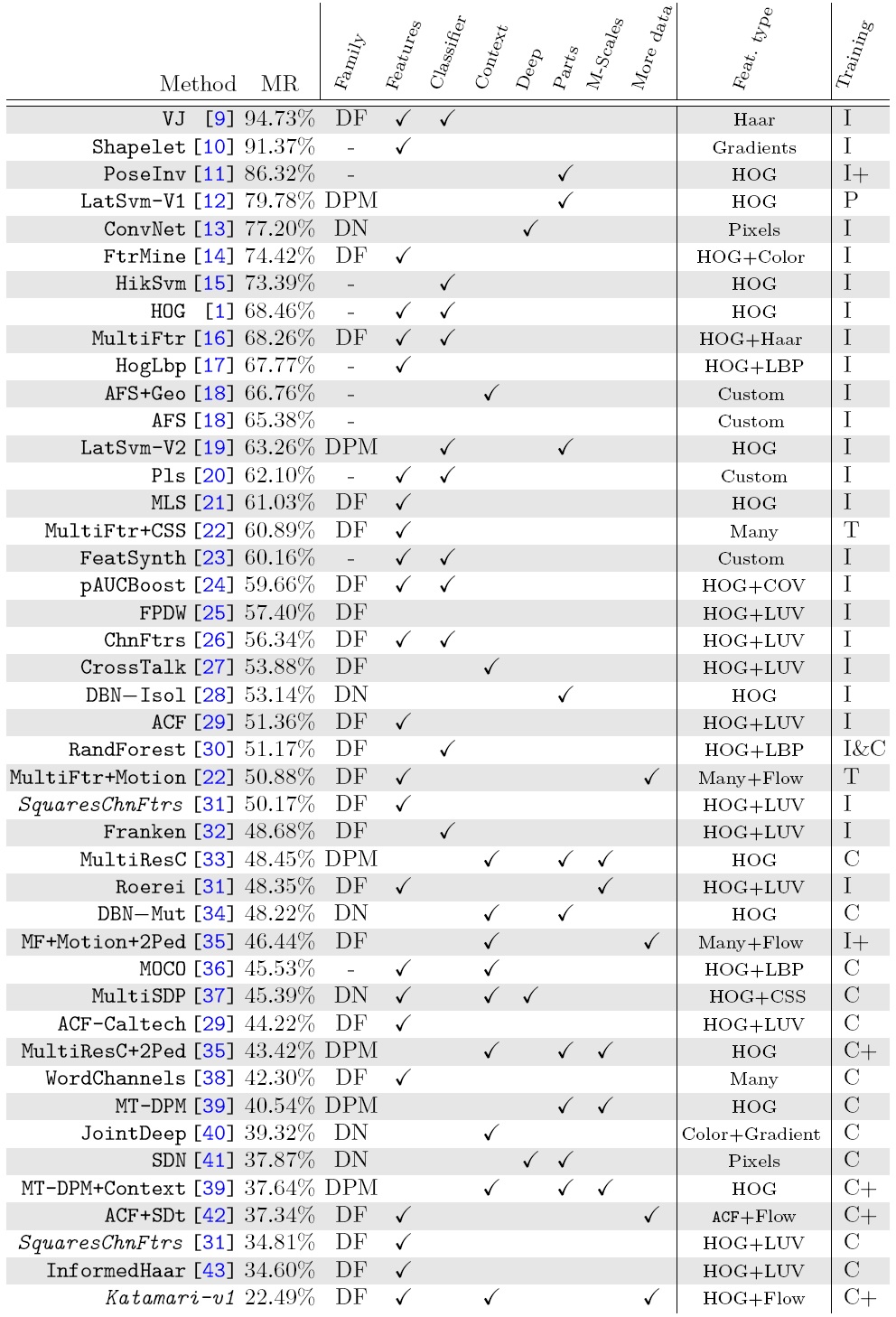
根据机器学习方法的不同,这40多种算法大体上可以分为3类:DPM算法、深度学习和决策森林。目前这三类算法都在行人检测上取得了最好的效果(Caltech上37%左右的MR),并没有明显差异。表中的算法按照丢失率的对数平均值进行排列,MR越低越好。
提高检测效果的因素
根据Benenson的分析,提高行人检测算法效果的因素主要有:更好的特征、附加信息(光流)和上下文信息等。这里按照提升的效果分别进行介绍。
更好的特征
提高检测效果最流行的方法就是增加或者改变特征,在这40多种方法中,约有30%是通过这种方法提高的。通过使用更丰富和更高维的表达方式,分类任务在某种程度上变的更简单了,从而提高结果。
附加信息
一些算法已经尝试利用附加信息在训练和测试时提高检测效果。目前考虑的附加信息有:立体图像、光流、跟踪或其他传感器得到的数据。
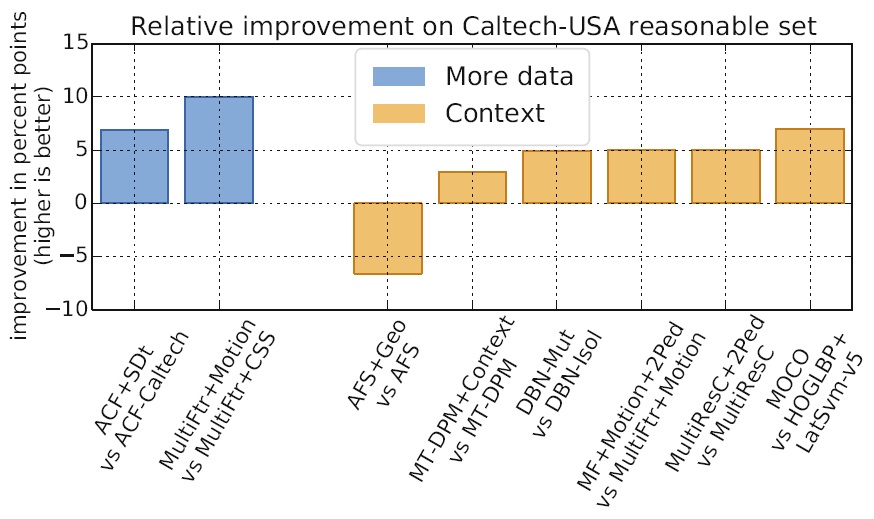
从图中可以看到,利用光流信息可以带来明显的提升。对于单目的算法,目前还不清楚跟踪能带来多大的提升。
使用附加数据能够带来明显的提升,但是目前数据集中的立体信息和光流信息还没有被充分利用。
利用上下文
滑动窗口的检测器在检测中只使用了检测窗口内的信息,利用检测窗口的上下文信息,例如窗口周围的内容,能够提高检测效果。利用上下文信息的策略包括:地平面约束、其他种类检测器和人与人的模型。
上图显示了合并上下文信息带来的效果提升。整体上MR的提升在3~7百分点。AFS-Geo的下降是由于评价方法的改变导致的。
多尺度模型
一般的检测算法,高分辨率和低分辨率的候选窗口都要重新采样到一个统一的尺寸再提取特征。最近一些研究表明为不同的分辨率训练不同的模型一般MR会提高1~2个百分点。多尺度模型虽然能稳定提高检测效果,但是其贡献相当有限。
其他影响因素
训练数据
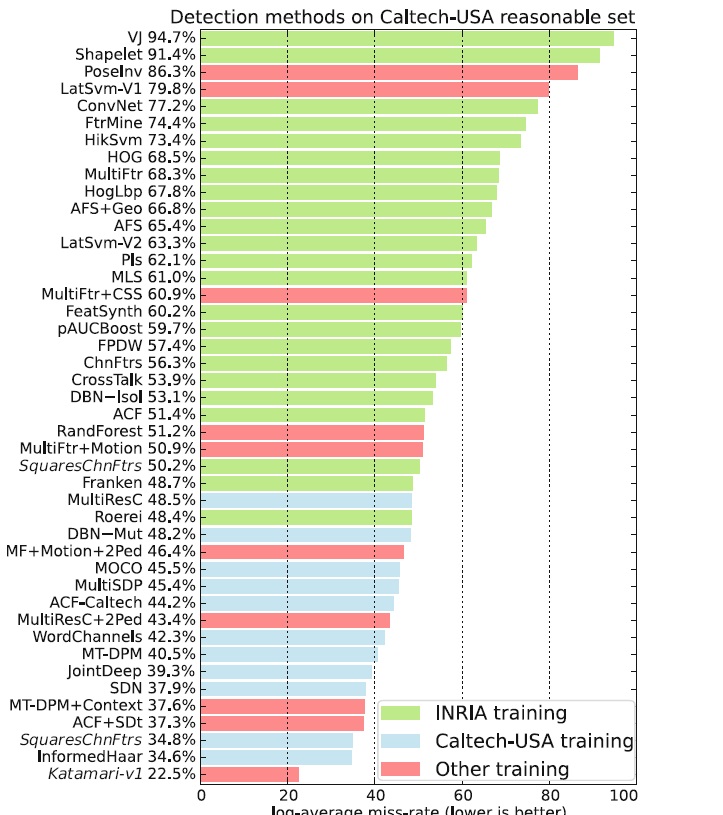
下图显示了采用不同训练数据的算法在Caltech上的检测结果。意料之中,由于测试集是Caltech,在Caltech上训练的算法整体上比在INRIA上训练的效果要好。
分类器
对于行人检测这一问题,没有足够证据表明非线性核比线性核效果好很多。同样,目前还不清楚是否某一分类器(例如,SVM或者决策森林)更适合做行人检测。
可变性部件
DPM算法及其变种算法一般优于使用单一模板和没有部件的算法。然而这并不能说明对部件建模的必要性,目前已经有一些方法在尝试从整体上获得形变信息,而不使用部件。
深层网络结构
目前已经有一些应用深度学习的方法。ConvNet使用卷积神经网络直接从原始像素中学习特征,在INRIA、ETH和TUD-Brussels上都取得了不错的效果。还有一类方法用深层网络结构联合模型部件和遮挡(如DBN−Isol[28], DBN−Mut[34], JointDeep[40], and SDN[41]),MR的提升在1.5~14个百分点。然而这些方法并没有从原始像素中提取特征,而是在边缘和颜色特征上进行学习的。目前还没有方法使用ImageNet预训练的特征。
实验
Benenson还做了一些实验,得到一些有趣的结论。作者将一些特征组合,获得了更好的效果。之后,作者将比较好的特征组合(HOG+LUV+DCT)再加上光流和上下文信息(人与人的相互作用),得到的算法在Caltech上达到了最好的效果。最后作者说明了目前的算法还没有达到过拟合,并对算法在不同数据集的泛化能力进行了测试。结果显示效果好的算法都是不依赖数据集的。同时训练时少量不同的行人(INRIA)要优于大量相似的行人(Caltech/KIITI)。















 4494
4494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









