









The process of renaming, assuming dispatch bound operand fetching
假设我们基本上还是用之前的core,但是使用dispatch bound operand fetching,rename process如下图所示:
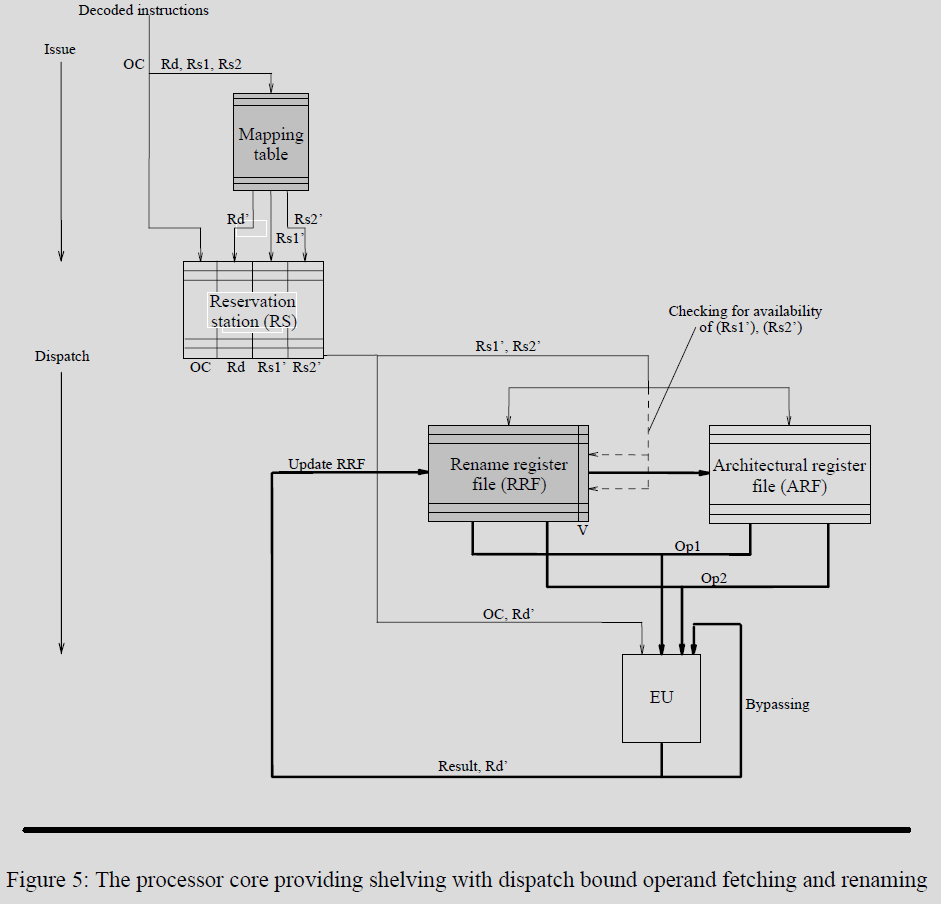
(i) 在instruction issue时,目标寄存器(Rd)和源寄存器(Rs1和Rs2)与issue bound operand fetching相同的方式rename。renamed register value(Rd‘,Rs1’ 和Rs2‘)和操作码(OC)一同写入RS.
(ii) 在dispatching期间,需要完成两个任务:
(a) RS中的最后一项的指令需要检查是否可以执行,以及是否EU是free的;如果都是,那么指令可以被发送的到EX单元执行;
(b) 在forwarding指令期间,它的操作数需要从RRF或者ARF中读取(和issue bound operation相同的方式)
(iii) EU完成了操作时,产生的结果需要更新RRF。更新操作是通过将结果写入allocated rename register,使用Rd‘作为写入RRF的索引,并且将对应的valid bit设置上;
(iv) 最终,如果处理器完成了指令,那么在associated rename register中暂存的临时值需要被写入destination register对应的architectural register。
唯一还需要完成的任务就是需要收回completed instruction对应的rename register。然而,这个操作比issue boudn operand fetching的该操作要复杂得多。注意:如果指令是在issue bound读取的,那么发射的指令可以立刻访问它的操作数,缺失的操作数可以从EU直接forwarded到RS中等待该操作数的指令。因此,在issue bound case中,在指令completion之后,该指令分配的rename register可以立刻被回收。
然而, 如果操作数是在dispatching期间读取操作数的,那么RS不会自动的被执行单元产生的结果更新。因此,在指令完成之后,RS中的指令中的操作数可能还会指向之前已经完成的指令对应的renamed register。因此,指令完成时,它们的allocated rename register不能立刻被回收。
为了解决这个问题,一个解决方法就是为每一个allocated rename register维护一个计数器,用来追踪后续读取该操作数的指令的数目。如果后续的指令访问该寄存器,那么计数器递增;如果需要读取该寄存器的指令被dispatched,并且读取了操作数,那么计数器递减。如果所有对应该寄存器的outstanding fetch request都已经完成了,即此时计数器为0,对应的指令已经完成了,那么该allocated register可以释放。
第一眼看上去,这个复杂的回收寄存器过程可以避免,如果在completion时,搜索RS中所有的分配给正在完成的指令(Rd’)的renamed source operand idetifiers(Rs1’, Rs2‘),如果匹配,就把寄存器重新映射到Rd。然而,这个idea行不通,因为无法保证对应的架构寄存器在需要Rs1,Rs2寄存器的指令被dispatch时,不被新的相同目的寄存器的指令改写。具体case如下图所示:
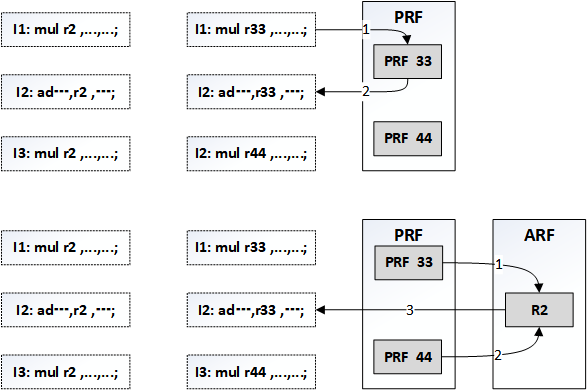
如上图所示,如果指令I1和I3要写入相同的架构寄存器R2,分别被重命名到r33和r44。如果在I1完成之后,将I2的寄存器从PRF33改为R2,那么可能在R2执行之前,I3完成,更新了R2,导致I2后面读取到的实际上是I3的计算结果。当然,这个idea还存在的问题就是不能在completion时就更改architecture状态,在retire时才可以。
在重命名期间,重命名寄存器和状态转换和Figure 4中的转换相同。唯一的不同在于,rename register的回收的条件不同。
需要强调的是,还有其他的寄存器重命名方式,主要是两方面:
(i) processor在其他结构中保存renamed value,而不是rename register file
(ii) processor可以使用不同的方式来重命名架构寄存器到rename register。
此外,处理器应该可以每周期rename多条指令。
欢迎关注我的公众号《处理器与AI芯片》

















 2406
2406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









