






一:灵感问题(需求)
首先简单介绍一下ass文件大致内容:ass字幕文件主要包括[Script Info]、[V4+ Styles]、[Events]头部信息等,其中[Script Info]通常包含有关字幕文件的一般信息,比如标题、作者、描述等;[V4+ Styles]这部分定义了字幕的样式信息,包括字体、大小、颜色、对齐方式等;[Events]主要包括核心的字幕(对话)内容以及字幕的出现和消失时间,以及其包含的特效或动画效果等等。
这里我们选取的是一段来自网上的动漫中日双语字幕文件,我们需要的主要是它的[Events]中的内容,同时由于字幕文件中中日字幕是分别独立展示(如下图),我们需要做的就是利用python从ass文件中提取出想要的[Events]信息并将双语字幕对应在一块一起展示,便于阅读。

二:代码实现
1)读取ass文件
利用记事本和excel均可打开ass文件(猜测是打开过程中存在不合理格式的强制转换),尝试利用pd.read_csv方法后发现难以正确解析ass字幕文件,我们改用open函数来解析ass文件;
# import the ass_subtitle_file
file_path = "D://pycharm//Shirokuma Cafe.ass"
with open(file_path, "r", encoding="utf-8") as file:
# 或使用"utf-8-sig"编码,它会自动处理编码中的BOM,并且适用于大多数ass文件2)提取想要的字幕内容
首先我们可以在关键词with和open函数下利用for循环逐行打印ass文件中的内容进行大致的阅读了解,当然,我们也可以利用记事本或excel等来直观的查看ass文件内容,但利用python可以让我们更加方便去获取想要的字幕内容的行标签,便于后续的数据处理;
with open(file_path, "r", encoding="utf-8") as file:
# 或使用"utf-8-sig"编码,它会自动处理编码中的BOM,并且适用于大多数ass文件
for line_number, line in enumerate(file, 0): # 调用enumerate函数返回索引和值的元组
print(f"Line{line_number}:{line}") # f"string"
逐行打印大致结果如下:我们发现每一行字幕展示后都存在空行,这其实与我们利用记事本或excel直观看到的字幕内容有别,最初不清楚原因但影响不大;通过逐行打印,我们在打印结果中找到我们想要的字幕行标签,其中第32行为我们需要的字幕格式信息,第81至184行为所需的日文字幕,第489至592行为所需的中文字幕,对此进行下一步处理;
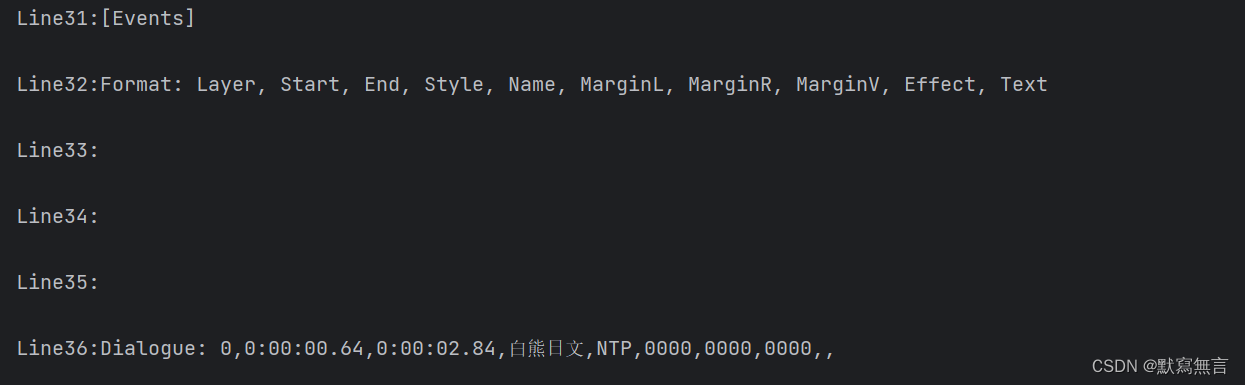
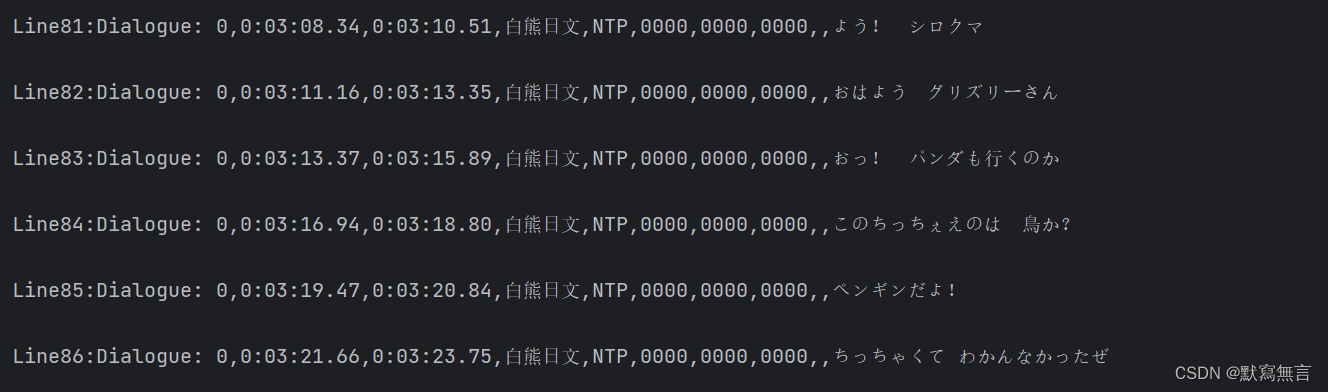
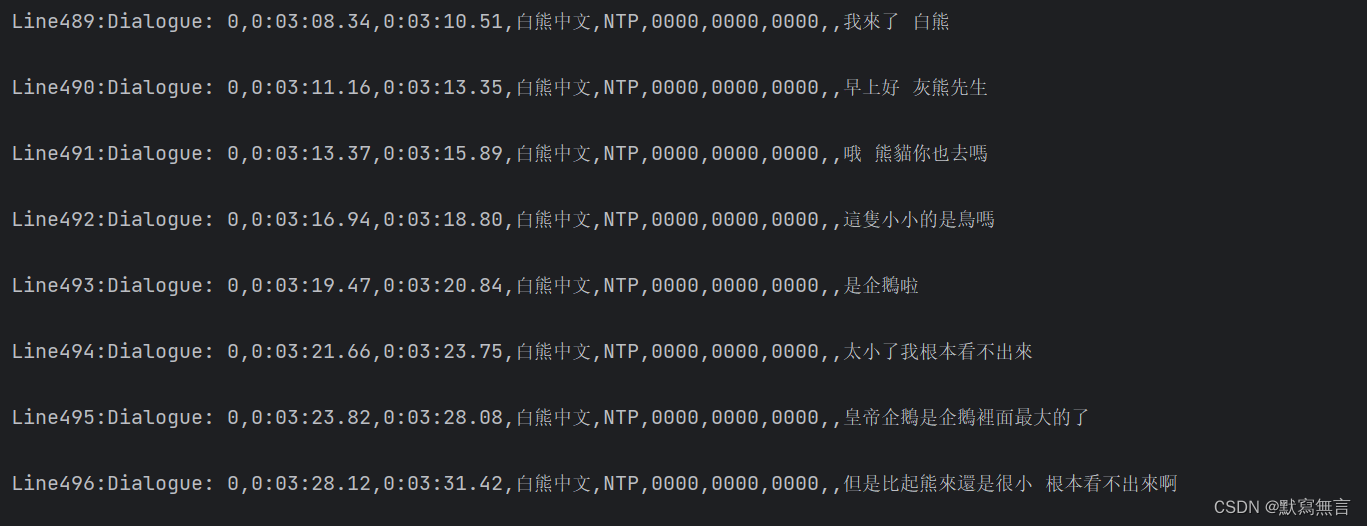
这里我们打算将字幕信息存储在DataFrame中进行阅读和处理,其中字幕的Line作为df行标签,字幕格式信息作为df列索引,具体的字幕信息作为df数据信息;
3)df列索引df.columns
在for循环下利用if条件判断选择第32行-字幕格式信息,进行分割后作为df列索引:
if line_number == 32: # 选择需要的字幕
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df_column = line.split(":")[1].split(",") # 分割
# df = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], columns=df_column) # data要用双[]
df = pd.DataFrame(columns=df_column) # 只有列名的空df 这里我们在最后将df打印出来看看操作结果:print("df:", df) 
结果是一个空的df,仅包含列索引,但我们发现在columns的打印结果最后有一个非常奇怪的换行,将df.columns打印出来进一步寻找问题:print("df.columns:", df.columns)

最后我们发现在每一行字幕信息的最后都存在一个换行符,利用str.strip()去除换行符:
import pandas as pd
file_path = "D://pycharm//practice//Shirokuma Cafe.ass"
with open(file_path, "r", encoding="utf-8") as file:
# 或使用"utf-8-sig"编码,它会自动处理编码中的BOM,并且适用于大多数ass文件
for line_number, line in enumerate(file, 0): # 记起始行为0行
line = line.strip() # str.strip()去除字符串两段空白字符(空格、制表符、换行符等)
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
if line_number == 32: # 选择需要的字幕
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df_column = line.split(":")[1].split(",") # 分割
# df = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], columns=df_column) # data要用双[]
df = pd.DataFrame(columns=df_column) # 只有列名的空df
运行后发现之前的每一行字幕打印后都存在空行的小问题也得到了解决。
4)df值df.values和df行索引df.index
利用for循环结构和if条件判断依此选择第81至184行所需的日文字幕,第489至592行所需的中文字幕,进行分割后作为df.values,同时使用默认的df.index:
with open(file_path, "r", encoding="utf-8") as file:
# 或使用"utf-8-sig"编码,它会自动处理编码中的BOM,并且适用于大多数ass文件
i = 0
j = 1 # 打印行计数
for line_number, line in enumerate(file, 0): # 记起始行为0行
# if line_number % 100 == 0:
line = line.strip() # str.strip()去除字符串两端空白字符(空格、制表符、换行符等)
if line_number == 32: # 选择需要的字幕
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df_column = line.split(":")[1].split(",") # 分割
# df = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], columns=df_column) # data要用双[]
df = pd.DataFrame(columns=df_column) # 只有列名的空df
if 80 < line_number < 185:
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df.loc[i] = line.split(": ")[1].split(",")
i += 2
if 489 <= line_number <= 592:
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df.loc[j] = line.split(": ")[1].split(",")
j += 2
df = df.sort_index()
pd.set_option("display.max_columns", None) # 展示完整的df
print(df)
print(df.info())5)调整输出所需字幕信息
df = df.drop(columns=[" Layer", " Name", " MarginL", " MarginR", " MarginV", " Effect"]) # 筛去不需要的列
print(df)
print(df.info())
# 输出df信息为txt
df.to_csv("output.txt", "\t", index=False) # 制表符分割
df.to_csv("output.xlsx", "\t", index=False) # 不需要索引完整代码如下:
import pandas as pd
# # import the ass_subtitle_file
# file_path = "D://pycharm//practice//Shirokuma Cafe.ass"
# df = pd.read_csv(file_path, delimiter=",",encoding="utf-8", nrows=19)
# print(df.head()) # 无法利用pd.read_csv正确解析ass文件
# import the ass_subtitle_file
# ctrl+alt+l格式化
file_path = "D://pycharm//practice//Shirokuma Cafe.ass"
with open(file_path, "r", encoding="utf-8") as file:
# 或使用"utf-8-sig"编码,它会自动处理编码中的BOM,并且适用于大多数ass文件
i = 0
j = 1 # 打印行计数
for line_number, line in enumerate(file, 0): # 调用enumerate函数返回索引和值的元组
# if line_number % 100 == 0:
line = line.strip() # str.strip()去除字符串两端空白字符(空格、制表符、换行符等)
if line_number == 32: # 选择需要的字幕
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df_column = line.split(":")[1].split(",") # 分割
# df = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]], columns=df_column) # data要用双[]
df = pd.DataFrame(columns=df_column) # 只有列名的空df
if 80 < line_number < 185:
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df.loc[i] = line.split(": ")[1].split(",")
i += 2
if 489 <= line_number <= 592:
print(f"Line{line_number}:{line}") # f"string" # 把日中字幕对应在一块显示
df.loc[j] = line.split(": ")[1].split(",")
j += 2
df = df.sort_index()
pd.set_option("display.max_columns", None) # 展示完整的df
print(df)
print(df.info())
# print(df.columns)
df = df.drop(columns=[" Layer", " Name", " MarginL", " MarginR", " MarginV", " Effect"]) # 筛去不需要的列
print(df)
print(df.info())
# 输出df信息为txt
df.to_csv("output.txt", "\t", index=False) # 制表符分割
df.to_csv("output.xlsx", "\t", index=False) # 不需要索引















 2713
2713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









