






原文链接: dqn 打砖块 单网络
上一篇: python flask 简单遥控器
下一篇: js Buckets 库 链表
安装
pip install gym
pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
打砖块的主要问题在于反馈有延迟,并不是当前决策就能立刻获得反馈,所以训练难度比平衡车大很多
打砖块的观察状态是图片的形式,所以需要使用卷积网络先处理。
为了降低复杂度,先使用图形学方法转化为灰度形式,并减小图像大小
# 处理游戏画面
# 输入 210x160x3 0--255
# 返回 105x80x1 -1,1
def process(img):
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.pyrDown(img)
# img = img[:, :, np.newaxis]
img = np.expand_dims(img, 3)
img = img.astype(np.float32)
img /= 128.
img -= 1.
return img
由于奖励记忆极其难以获得,所以初始化时只限制一部分,其他记忆在训练中进行补充
由于不能进行并行记忆获取,会出现,在训练网络的时候后台进程在执行网络获取动作预测值,所以只能采用阻塞的形式获取记忆
记忆保存使用双端队列,这样可以减少维护的麻烦,但其实也可以做持久化处理,但考虑到开始时的记忆重复率太高还是在训练的过程中对记忆库进行更新比较合适
每次刷新记忆后,将普通记忆,奖励记忆,惩罚记忆合并后缓存起来,在获取批次时就不用再次进行记忆的合并了
在进行记忆采样的时候,使用random模块的sample函数进行采样
测试在随机情况下,一局游戏可以获得大约1.5分,平均一局花费250步
import gym
env = gym.make('Breakout-v4')
game_epoch = 100
score = 0
step = 0
for i in range(game_epoch):
env.reset()
while True:
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
score += reward
step += 1
if done:
break
# 249.65 1.37
# 249.81 1.4
print(step / game_epoch, score / game_epoch)
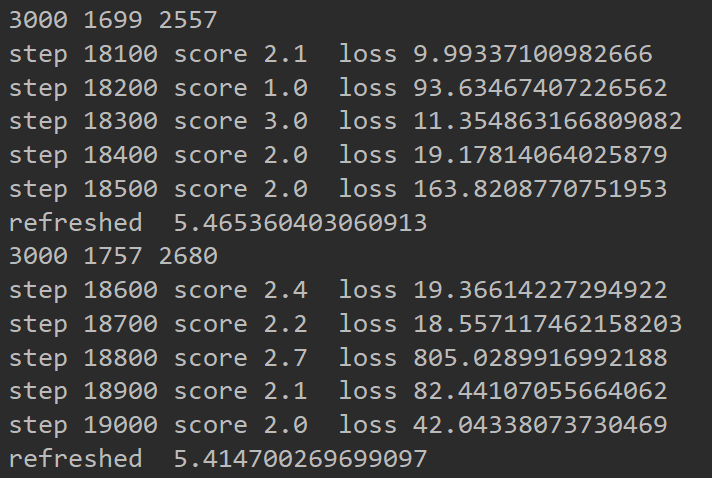
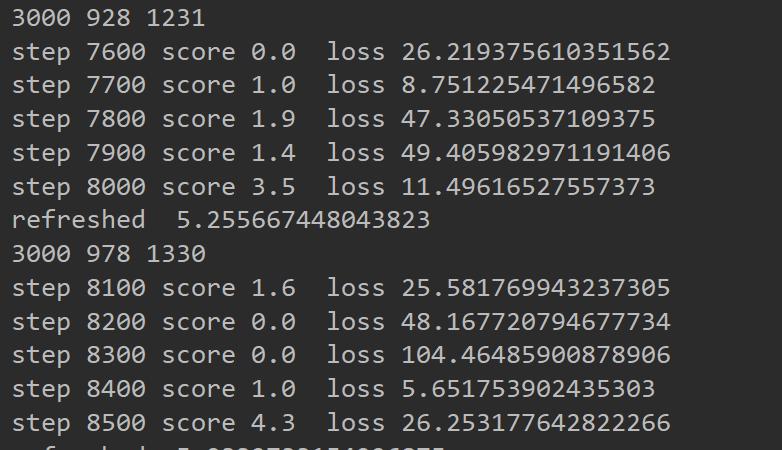
单网络的稳定性不是很强,效果有时候效果很好,有时候很差
完整代码
import tensorflow as tf
import numpy as np
import gym
import tensorflow.contrib.slim as slim
import matplotlib.pyplot as plt
import cv2 as cv
import time
from collections import deque
from itertools import chain
from random import sample
# 处理游戏画面
# 输入 210x160x3 0--255
# 返回 105x80x1 -1,1
def process(img):
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.pyrDown(img)
# img = img[:, :, np.newaxis]
img = np.expand_dims(img, 3)
img = img.astype(np.float32)
img /= 128.
img -= 1.
return img
def get_block(in_x, scope, out_num=32):
with tf.variable_scope(scope):
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.leaky_relu,
):
net1 = slim.conv2d(in_x, out_num, 1)
net3 = slim.conv2d(in_x, out_num, 3)
net5 = slim.conv2d(in_x, out_num, 5)
# net7 = slim.conv2d(in_x, out_num, 7)
block = tf.concat([in_x, net1, net3, net5], axis=3)
# block = slim.conv2d(block, out_num, 3)
block = slim.max_pool2d(block, 3, padding="SAME", stride=2)
block = slim.conv2d(block, out_num, 1)
return block
def get_net(in_x, n_actions):
with tf.variable_scope('new_net'):
with slim.arg_scope(
[slim.fully_connected],
activation_fn=tf.nn.leaky_relu,
):
net = get_block(in_x, 'block1')
print(net.shape)
net = get_block(net, 'block2')
print(net.shape)
net = get_block(net, 'block3')
# print(net.shape)
# net = get_block(net, 'block4')
print(net.shape)
net = slim.flatten(net)
print(net.shape)
net = slim.fully_connected(net, 512)
print(net.shape)
net = slim.fully_connected(net, 128)
print(net.shape)
net = slim.fully_connected(net, n_actions)
print(net.shape)
return net
class DQN:
env = gym.make('Breakout-v4')
n_actions = 4
lr = .001
epsilon = .9
epsilon_decay_step = 500
show_step = 100
train_step = 100000
memory_size = 3000
min_memory_size = 500
refresh_memory_step = 500
batch_size = 32
reword_decay = .7
# 由于很难获取到正奖励,所以将所有正奖励记忆保存起来
reward_memory = deque(maxlen=memory_size)
memory = deque(maxlen=memory_size)
done_memory = deque(maxlen=memory_size)
all_memory = None
def __init__(self):
# build net
# new_net 用于计算预测值
self.s_new = tf.placeholder(tf.float32, (None, 105, 80, 1))
self.q_new_in = tf.placeholder(tf.float32, (None, self.n_actions))
self.q_new_out = get_net(self.s_new, n_actions=self.n_actions)
with tf.variable_scope("loss"):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_new_in, self.q_new_out))
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
def refresh_memory(self):
self.memory.clear()
st = time.time()
observation = self.env.reset()
observation = process(observation)
# 每一局游戏采用同样的随机采样概率
# 在游戏重置时,重新修改该值
random = np.random.rand()
while len(self.memory) < self.memory_size \
or len(self.done_memory) < self.min_memory_size \
or len(self.reward_memory) < self.min_memory_size:
# 使用线程 同步刷新记忆
action = self.choose_action(observation, random)
observation_new, reword, done, info = self.env.step(action)
observation_new = process(observation_new)
if reword > 0 and not done:
reword *= 10
self.reward_memory.append(
(observation, action, reword, observation_new)
)
observation = observation_new
elif done:
reword = -100
self.done_memory.append(
(observation, action, reword, observation_new)
)
observation = self.env.reset()
observation = process(observation)
random = np.random.rand()
else:
self.memory.append(
(observation, action, reword, observation_new)
)
observation = observation_new
ed = time.time()
print('refreshed ', ed - st)
print(len(self.memory), len(self.done_memory), len(self.reward_memory))
# 由于开始时, 样本分布不均, 保证均等抽样
# 刷新记忆后,将记忆缓存起来,这样可以避免每次在获取batch时进行的列表转换操作
# reward_scale = self.memory_size // len(self.reward_memory)
# done_scale = self.memory_size // len(self.done_memory)
# self.all_memory = list(chain(self.memory, self.reward_memory * reward_scale, self.done_memory * done_scale))
self.all_memory = list(chain(self.memory, self.reward_memory, self.done_memory))
# 输入 hwc 返回 一个数字表示执行的动作 random 表示采用随机行为的概率大小
def choose_action(self, observation, random=0.):
# 由于刚开始 如果使用网络计算出的行为 很容易造成静止操作
# 比如采取静止不动,则画面也不动,陷入死循环,并且很难获取正值奖励
# 所以随机动作概率开始很大,越往后面越小,但不会小于最小值
if np.random.rand() < random:
return np.random.randint(0, self.n_actions)
observation = observation[np.newaxis, :]
action_value = self.sess.run(
self.q_new_out, {
self.s_new: observation
}
)
return np.argmax(action_value)
def get_batch(self, batch_size=batch_size):
batch = sample(self.all_memory, batch_size)
batch = np.array(batch)
# print(memory.shape)
images_old = np.stack(batch[:, 0]).astype(np.float32)
images_new = np.stack(batch[:, 3]).astype(np.float32)
actions = np.stack(batch[:, 1]).astype(np.int32)
rewords = np.stack(batch[:, 2]).astype(np.float32)
# print(images_old.shape, images_new.shape, actions.shape, rewords.shape)
return images_old, actions, rewords, images_new
# 选择记忆库中的记忆进行学习
def learn(self):
images_old, actions, rewords, images_new = self.get_batch()
q_old_val = self.sess.run(
self.q_new_out, {
self.s_new: images_new
}
)
q_new_val = self.sess.run(
self.q_new_out, {
self.s_new: images_old
}
)
batch_index = np.arange(self.batch_size, dtype=np.int32)
action_index = actions.astype(np.int32)
selected_q_next = np.max(q_old_val, axis=1)
q_new_val[batch_index, action_index] = rewords + self.reword_decay * selected_q_next
_, loss = self.sess.run(
[self.train_op, self.loss], {
self.s_new: images_old,
self.q_new_in: q_new_val
}
)
return loss
# 为了扩充数据集,将test中的数据也加入进去
# 只加入reward和done
# 一般随机概率的话,一次完整游戏的得分均分为1.5
def test(self, render=False):
observation = self.env.reset()
observation = process(observation)
score = 0
for i in range(1000):
if render:
self.env.render()
time.sleep(.01)
# 不采用随机行为
action = self.choose_action(observation, 0)
# print('test action ', action)
# print(action)
observation_new, reword, done, info = self.env.step(action)
observation_new = process(observation_new)
score += reword
if reword > 0 and not done:
reword *= 10
self.reward_memory.append(
(observation, action, reword, observation_new)
)
observation = observation_new
elif done:
reword = -100
self.done_memory.append(
(observation, action, reword, observation_new)
)
break
else:
observation = observation_new
return score
# 开始训练
def train(self):
loss_list = []
score_list = []
for i in range(1, self.train_step + 1):
loss = self.learn()
if i % self.show_step == 0:
score = 0
cnt = 10
for j in range(cnt):
score += self.test()
score = score / cnt
score_list.append(score)
loss_list.append(loss)
print(f'step {i} score {score} loss {loss} ')
# if score >= 20:
# self.test(True)
if not i % self.epsilon_decay_step:
self.epsilon = max(.01, self.epsilon * .8)
if not i % self.refresh_memory_step:
self.refresh_memory()
return loss_list, score_list
def main():
dqn = DQN()
# print('start')
# dqn.start()
print('refresh')
dqn.refresh_memory()
print('train')
loss, score = dqn.train()
plt.plot(range(len(loss)), loss)
plt.show()
plt.plot(range(len(score)), score)
plt.show()
dqn.test(True)
if __name__ == '__main__':
main()















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









