







仅供自己参考学习使用,如果有问题或者觉得内容不错,请去原文作者处点赞和讨论,谢谢。
原文地址:https://zhuanlan.zhihu.com/p/89058164
github:https://github.com/PaddlePaddle/PARL/blob/develop/papers/archive.md
整体介绍
这篇文章主要介绍经典的model-free 算法。对刚接触强化学习,然后又想深入了解RL的同学来说,是一个很好的论文合集。文章涵盖了首次用神经网络结合强化学习的DQN算法,以及基于DQN算法做的一系列改进,涉及到网络结构,replay memory,建模方式,探索方式的改进。
Playing Atari with Deep Reinforcement Learning
NIPS Deep Learning Workshop 2013. paper
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller

简述:这是首篇结合神经网络以及强化学习的文章。文章采用了CNN网络结构,直接输入游戏图像,然后输出每个action的Q值预估方式,实现端到端的强化学习算法。文章采用了90年代提出的经验回放机制来增加模型训练的稳定性,整体实验效果其实一般,只是评估了5个环境,效果也没有和人类打平,这可能是这篇文章没有引起大轰动的原因。
Human-level control through deep reinforcement learning
Nature 2015. paper
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg & Demis Hassabis
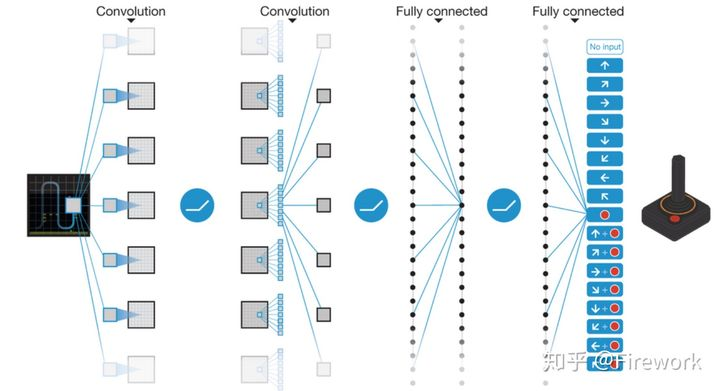
简述:这是发表在Nature上的为数不多的CS文章,加上谷歌家的PR,在15年引起了相当大的轰动。相对上文来说主要是引进了 target 网络的更新机制来进一步提升DQN的效果,改进虽然不大,但是在效果上提升还是很大的,在30多个atari 游戏上都达到了人类级别的水准。本质上来说DQN算法的核心思想还是90年代的Q-learning,作者通过experience replay 以及target network两个trick来增加了网络收敛的稳定性,从而实现了端到端的控制算法。
Deep Reinforcement Learning with Double Q-learning
AAAI 16. paper
Hado van Hasselt, Arthur Guez, David Silver
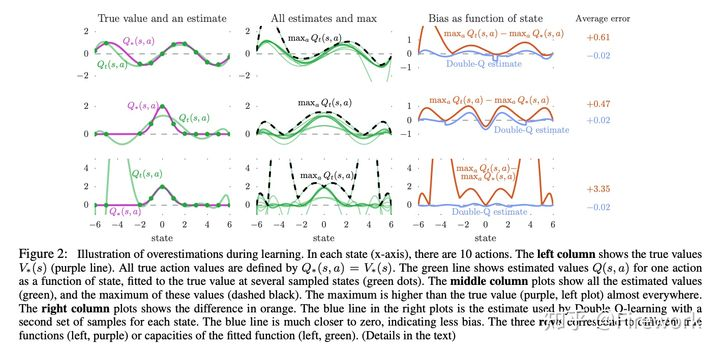
简述:文章指出,由于在拟合Q网络的过程中会不可避免地存在一些预估误差,使得Q-learning这个算法在采用bellman 方式更新的过程中把这些误差包含进来,从而导致过预估(overestimation)的问题。针对这个问题,作者提出了引入另一个Q网络来进行决策,也就是说,之前的Q网络既用于决策,又用于预估Q值,在double DQN里面采用两个网络来分别完成这两个事情。
Dueling Network Architectures for Deep Reinforcement Learning
ICML16.paper
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, Nando de Freitas
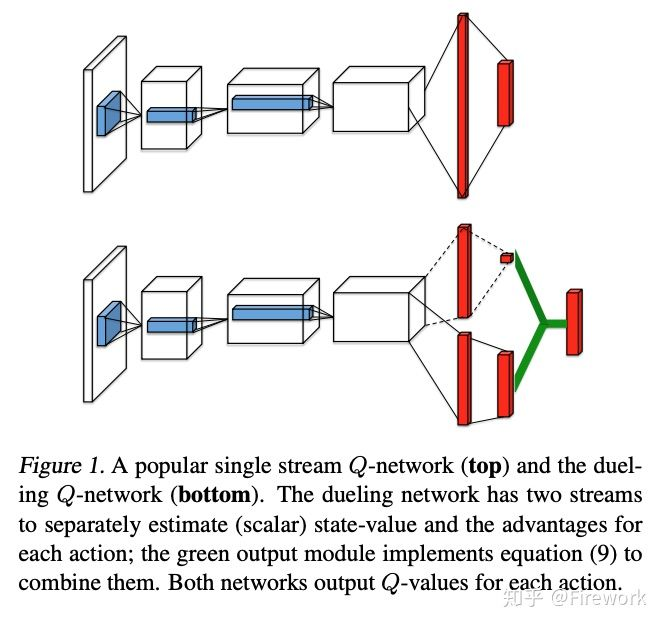
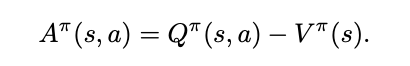
简述:作者根据优势值(A)与值函数(V),Q函数的关系,将Q网络的建模拆分成了两个数据流,最后通过两个数据流的合并整合称最终的Q函数。根据最后的实验分析来看,V函数更加注重整体的环境情况,A函数更注重agent附近的情况。这个网络的改进是可以结合上面提到的Double DQN的。
Deep Recurrent Q-Learning for Partially Observable MDPs
AAA15.paper
Matthew Hausknecht, Peter Stone
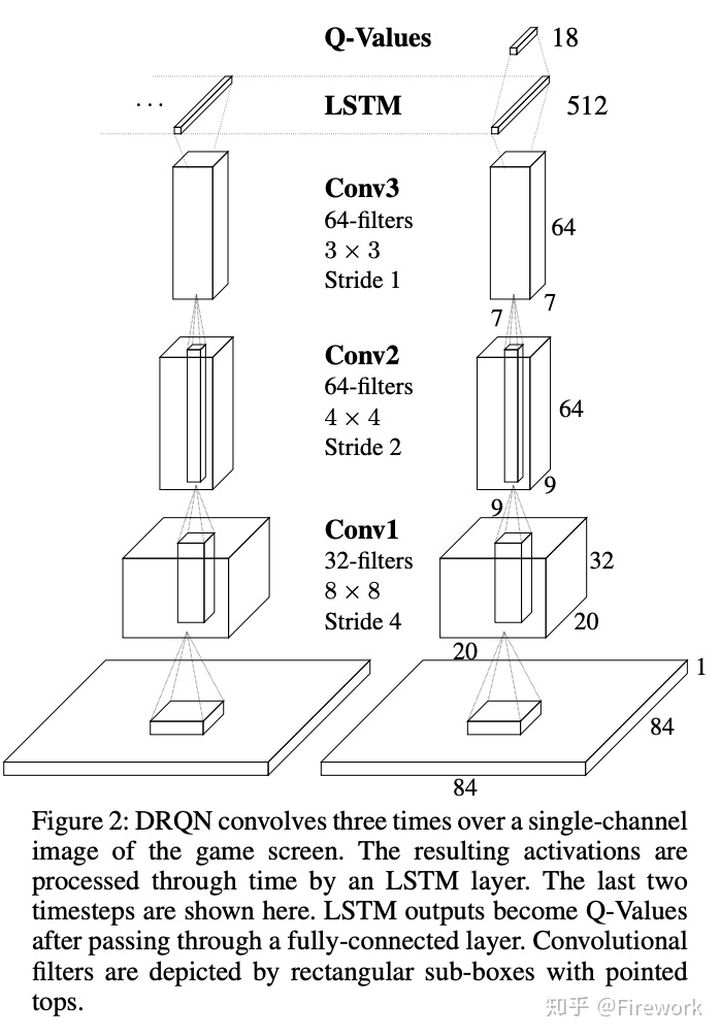
简述:传统的DQN是采用最近4帧的图像进行建模,这篇文章是采用单帧图像结合RNN进行建模,算法的效果与DQN是相近的。
Prioritized Experience Replay
ICLR 2016. paper
Tom Schaul, John Quan, Ioannis Antonoglou, David Silver
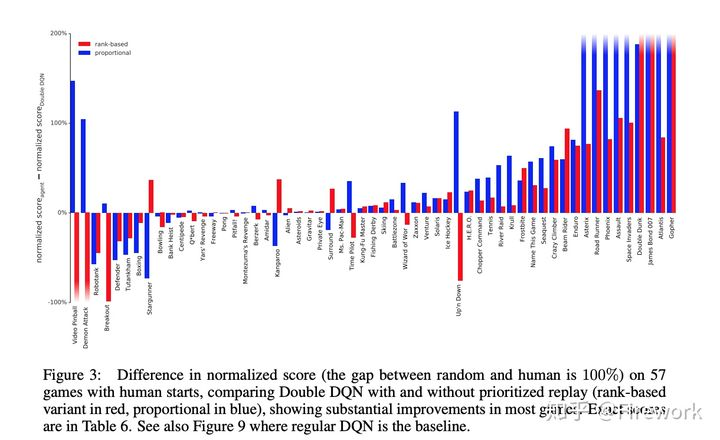
简述:在采用experience replay这种机制存储训练数据的时候,一般的做法是通过均匀分布来采样训练数据的。作者提出通过计算TD-error的方式给每个样本进行优先级排序,优先训练TD-error较大的数据。
Asynchronous Methods for Deep Reinforcement Learning
ICML2016. paper
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, Koray Kavukcuoglu
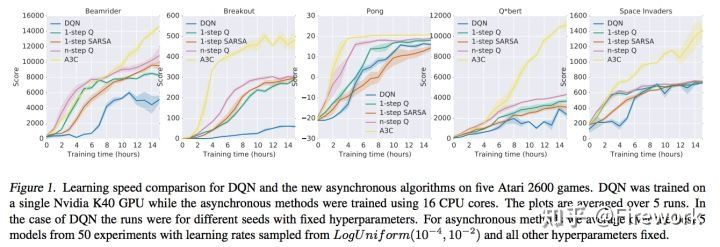
简述:这篇是RL领域最为经典的并行工作。作者通过多线程的方式来实现并行:每个线程有一份独立的policy参数以及一个游戏环境,这个policy会和环境交互产生数据来计算梯度。在跑每个episode之前,这个policy都会从parameter server上拉取最新的模型参数,然后在跑完每个episode之后计算梯度后把梯度刷到parameter server上。在当时看来,这个算法不仅能极大提升训练速度,而且效果也比当时的单机DQN版本好很多。作者在分析中提到由于每个线程的policy探索了不同的状态空间,从而提升了算法效果。
A Distributional Perspective on Reinforcement Learning
ICML2017. paper
Marc G. Bellemare, Will Dabney, Rémi Munos
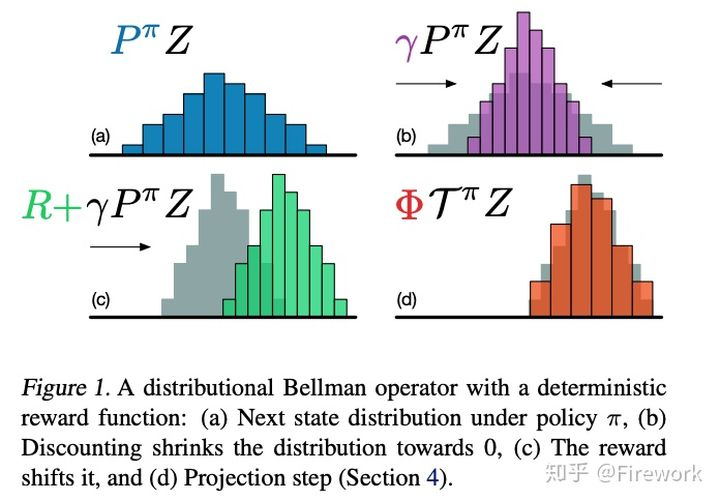
简述:Q值一般代表的是agent在未来沿着当前policy执行下去的reward期望值,作者在文章中直接对Q值的分布进行建模,达到了比DQN更好的效果。这个文章的建模方式相当有趣,直观的做法是采用高斯分布对Q值建模,但是这里作者采用的是类别分布(Categorical Distribution)。
Noisy Networks for Exploration
ICLR2018. paper
Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, Shane Legg
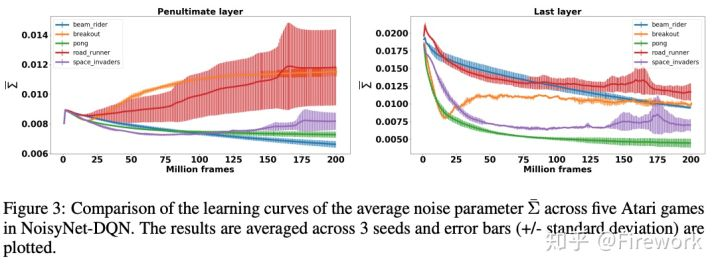
简述:一般RL在做训练的时候,都是通过在动作空间(action space)添加噪声的,比如DQN里面用到的e-greedy以及DDPG里面用到的白噪声。OpenAI的作者通过在参数层面添加噪声的方式进行explore,效果在DQN/DDPG/PPO算法上都有所提升。
Rainbow: Combining Improvements in Deep Reinforcement Learning
AAAI2018.paper
Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, David Silver
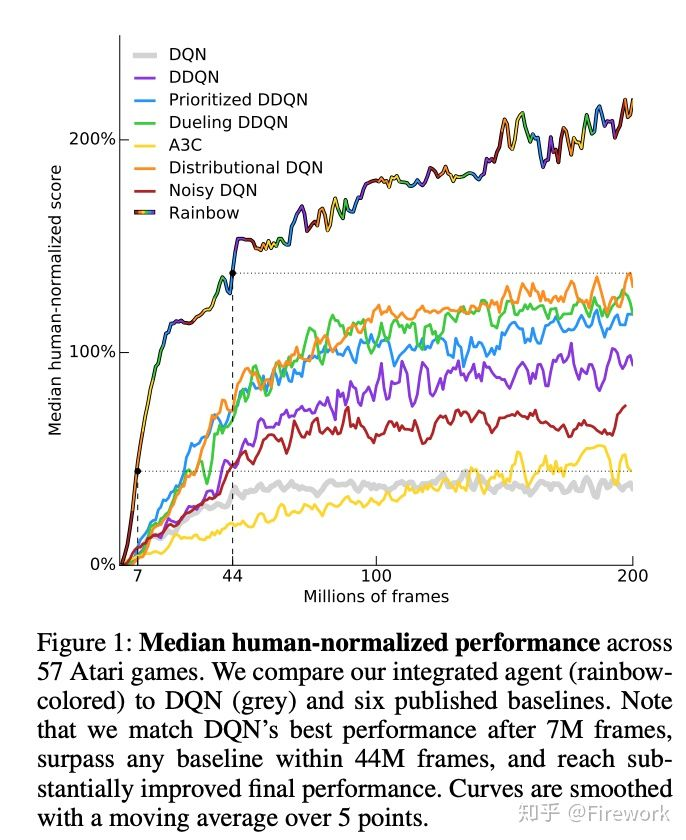
简述:曾经的Atari游戏上的SOTA算法。作者集合了各种DQN的改进算法,包含前面提到的A3C/ Noisy Network/ Double DQN/ Dueling DQN/ Distributional DQN/ Prioritized RPM等方法,算法的提升也是蛮大的。截止到目前,最好的Atari指标是R2D2,感兴趣的读者可以了解下这个发表在ICLR19年的工作。
本文讨论到的相关论文连接放在了github(点我)上,后续会一直更新。
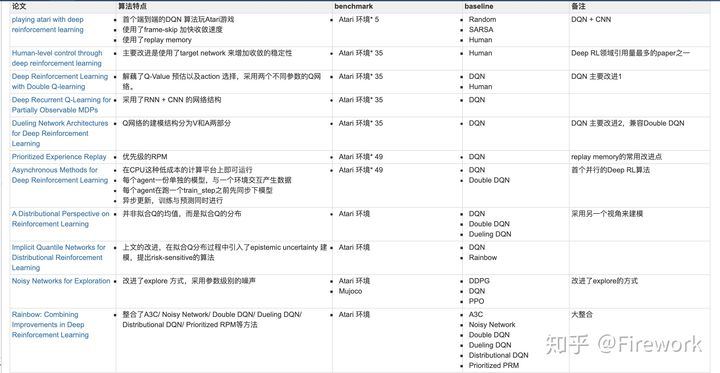
最后,例行来一个表格总结。

















 4299
4299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









