







最近看到model-based强化学习方法,在这里做一个笔记
【废话】
我是控制专业做强化学习,在我看来强化学习最大的优势是model-free,也是最麻烦的地方,目前强化学习的改进就是从两方面下手:如何学的更好or学的更快。毕竟现实生活中不是都像游戏一样可以无成本等你学习。当时还没有学强化学习基本概念的时候,我就想为什么不把模型信息添加进去呢?
目前控制方面,实用性最大的肯定还是PID(PID万岁~),只要有输出(这点和RL相似),调参数就可以,现在找一个会调PID参数的工程师很容易。现代控制理论最让人诟病的是需要模型,但事实上模型除了一些顶尖领域不管你怎么建,一定有误差(有学者说,能用数学表达式表示的模型一定是有问题的)。既然如此为什么不结合一下,RL+能确定的那部分模型信息,这样学习应该会加快。
【MPC控制】
我没做过MPC控制,先去查了一下MPC怎么做的。
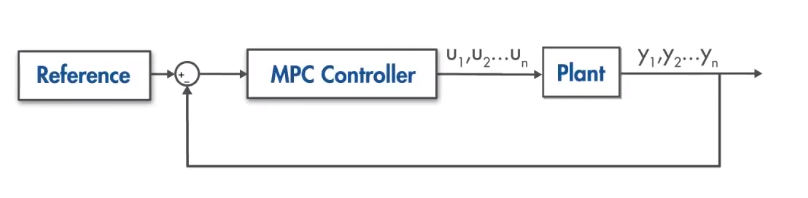
首先基本框图,很明显首先MPC优势1,不同于PID单通道设计,MPC是个多变量控制器。优势2,我理解它是最优控制的一种,是个最优化问题,满足限制指标。
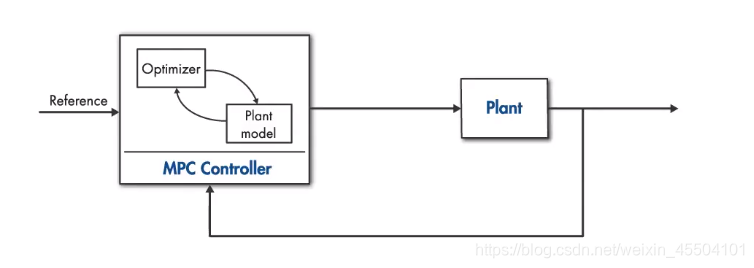
如图,MPC Controller包含两部分,预测+优化。预测模型未来的几步输出,当成一个优化问题输入到优化器,优化器得到的最优解就是控制器的输出。感觉和LQR一样更像个数学优化问题。
MATLAB官方有一个MPC的课程讲的挺好,具体想研究的可以去看。
【model-based rl】
普通的RL,是通过收集过去的数据,并从中学习到最好的策略。所以一开始的数据收集探索阶段很重要,如果你收集的数据很少/不全,你自然是学不到好的策略。所以model-free的缺点就是数据利用效率不高,你学习一个复杂点的环境可能要很久。所以当你知道模型信息的时候,可以更加高效的利用数据。
那么第一个问题:如何建模?
对于游戏等一些环境,确实有点麻烦(我也不知道行不行)。但是对于控制问题来说,是可以的,毕竟控制的第一步都在建模,运动学/动力学模型肯定是可以建出来的。
我们希望的是,当已知( s t , a t s_{t},a_t st,at
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









