







Abstract:近两年, DeepLearning(DL) 在国内逐渐活跃起来。 DeepLearning 主要应用于图像识别,目标检测等图像处理方面。很多研究机构、企业已经把它运用于文本、语音,甚至金融、电子等行业。我相信 DL 在未来几年将会在更多的行业中得到应用。在 DL 中参数调节的算法尤为重要,大部分参数调节的算法均采用 BP 反馈算法,了解其原理对我们学习原理或者工程运用都非常有用。本文旨在介绍 BP 反馈的原理,让读者更加了解深度网络的学习过程。
1. 深度网络
下面是一个简单的神经网络的结构图。
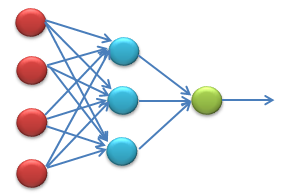
对于深度网络,就是加入深度网络,在输入的时候可能加入了卷积(一维卷积可以处理一维的波形,二维卷积一般处理图像,三维卷积一般可以处理视频图像)或者多层隐含层,更或者适合自己领域的一些带参数的处理,这个视情况而定。
- 一维的深度网络:
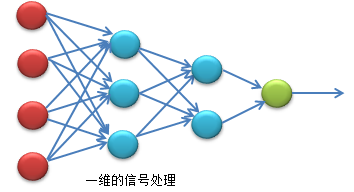
一维信号的深度网络,我们也可以看成一种卷积过程,如果学过信号处理,我们可以把这个网络看做一个一维傅里叶变换的形成,提取不同成分的特征(傅里叶是提取不同的频率成分)。对于语音或者其他的电信号的波可以在网络的前面加入蝶形算法形成深度网络,应用于语音识别或者波形识别。对于文本也可以加入带参数预处理方式加入网络的前端。当然对于不同的应用领域的处理方式就不太一样了。
二维深度网络
、
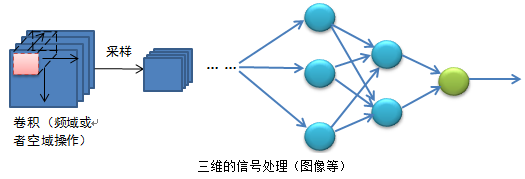
二维的深度网络代表就是卷积神经网络,是先通过卷积再采样,与一维卷积不一样,我理解为一种有限的卷积,而两个完整的信号卷积,如一维信号X和一维信号Y的卷积,是整个序列进行卷积。而二维图像,也可以展开为一个一维信号X,卷积核也可以展开为一个序列Y,这时卷积就是有限长的X信号的与整个Y信号进行卷积。但是卷积的本质不会改变,可以理解为对某一段信号求取不同的成分,对于信号的傅里叶变换,就是求取某一段序列的频率成分。二维深度网络大多运用图像。三维深度网络
三维的深度网络主要用于视频方面或者二维信号的时间序列。
2.BP反馈算法
下面将讲解BP反馈算法在深度网络中的原理。
一维网络:
假如一个4层的深层网络。输入层为3,第一层隐含层为3,第二层隐含层为2,输出层为1(输出层为1一般用于回归,
≥
2一般用于分类)。
那么第一层三个神经元的三个输出分别为
a(2)2=f(W(1)21x1+W(2)22x1+W(3)23x1)
a(2)3=f(W(1)31x1+W(2)32x1+W(3)33x1)
上述网络加了
f(⋅)
为激活函数
预期输出值:
hW,b(x)=f(W211a(2)1+W(2)12a(2)2+W(2)13a(2)3)
这样我们就可以写出损失函数:
J(W,b;x,y)=12∥hW,b(x)−y∥2
但是这个函数中有些点不可导或者不连续或者不是严格个凸函数,这样在后面求取梯度的时候会造成错误。那么我们需要加入
L2
正则。那么此时损失函数可以写为:
J(W,b)=12∥hW,b(x)−y∥2+λ2∑nl−1l=1∑sli=1∑sl−1i=1(W(l)ji)2
这样损失函数就保证了严格凸连续,是一个强凸二次函数。
下面可以就可以采用很多策略来优化这些参数。比如:最速下降法,拟牛顿法,牛顿法,有限内存的拟牛顿法等。通常采用是最速下降法
(SD)
和有限内存的拟牛顿法
(L−BFGS)
,因为这两个方法不需要求取海森矩阵
(Hessian)
,大大节约了计算的效率和计算机的内存。而牛顿法和拟牛顿法需要求取
Hessian
矩阵,对于小数据的计算不会造成影响,但是对大数据,尤其是图像,视频这些信息量比较大的数据,那么代价就大了,所以通常采用这两方法进行参数优化。
SD
和
LBFGS
比较的话,
SD
计算量更小些,因为
LBFGS
是用损失函数的梯度近似代替
Hessian
矩阵。最速下降法的更新公式如下:
W(l)ij:=W(l)ij−α∂∂b(l)iJ(W,b)
那么对于含有激活函数的深度网络,输出神经元(当然可以是多个)的梯度。对于每一个的输出神经元我们可以得到。假设一共有
nl
层网络,那么输出层为
nl
,那么每一个神经元我们设定如下:
δ(nl)i=∂∂z(nl)i∥y−hW,b(x)∥2=−(yi−a(nl)i)⋅f′(z(nl)i)
每层
l=nl−1,nl−2,...,2
都有如下关系:
δ(l)i=(∑sl+1j=1W(l)jiδ(l+1)j)⋅f′(z(l)i)
下面具体以图例解释下这个公式:
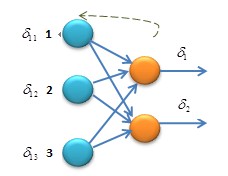
假设有两个输出神经元,每个神经输出的损失值分别
δ1
和
δ2
,输入神经元有三个,分别标号为
1,2,3
,输入神经元
1
号与输出神经元连接的权值分别为
这个公式可以看做是误差的分配,前一层的多个神经元连接到一个神经元上,这个神经元的损失值求出,然后根据前馈连线的权值算出前一层每一个神经元的损失值,如果输出层有多个神经元,传回前一层就相叠加就可以求出神经元的损失,依次类推到更多的神经元以及更深层的网络层。
这是每一层
W
的梯度可以由下式得到:
每一层
W
的梯度公式如上式子,加上学习率

怀柔风光















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









