









传统的向量空间模型(Vector Space Model)中,文档被表示成由特征词出现频率(或概率)组成的多维向量,然后计算向量间的相似度。向量空间模型依旧是现在很多文本分析模型的基础,但向量空间模型无法处理一词多义和一义多词问题。Scott Deerwester,Susan T. Dumais等人在1990年提出了LSA(Latent Semantic Analysis,潜在语义分析)又称LSI(Latent Semantic Indexing),是一种非常有效的文本建模方法,正如名称所指示,该方法意在分析文本语料所包含的潜在语义,然后将单词和文档映射到该语义空间。
LSA以矩阵奇异值分解(SVD)为基础,在了解LSA之前,需要先对奇异值分解进行简单介绍。
奇异值分解
我们都知道,一个矩阵其实代表了一个线性变换(旋转,拉伸),可以将一个线性变换过程分解多个子过程,矩阵奇异值分解就是将矩阵分解成若干个秩一矩阵的和。
A
=
σ
1
u
1
v
1
T
+
σ
2
u
2
v
2
T
+
⋯
+
σ
n
u
n
v
n
T
A=\sigma_1u_1v_1^T+\sigma_2u_2v_2^T+\cdots+\sigma_nu_nv_n^T
A=σ1u1v1T+σ2u2v2T+⋯+σnunvnT
其中
σ
i
\sigma_i
σi是奇异值,
u
i
v
i
T
u_iv_i^T
uiviT是秩为1的矩阵,表示一个线性变换子过程。奇异值
σ
i
\sigma_i
σi反映了该子过程
u
i
v
i
T
u_iv_i^T
uiviT在该线性变换
A
A
A中的重要程度。对上面式子进行整理,我们可以将奇异值分解过程写成如下:
A
=
U
S
V
T
A=USV^T
A=USVT
其中, U U U是左奇异向量构成的矩阵,两两相互正交, S S S是奇异值构成的对角矩阵, V T V^T VT是右奇异向量构成的矩阵,两两相互正交。
奇异值分解数学性质
奇异值分解具有如下数学性质:
- 一个 m ∗ n m*n m∗n的矩阵至多有 p = m i n ( m , n ) p=min(m,n) p=min(m,n)个不同的奇异值。
- 矩阵的信息往往集中在较大的几个奇异值中。
LSA正是利用了奇异值分解的这两个性质,实现将原始的单词-文档矩阵映射到语义空间。
LSA
在LSA中,我们不再将矩阵理解成变换,而是看作文本数据的集合。文本语料中所有的单词构成了矩阵的行,每一列表示一篇文档(词袋模型表示)。假设
A
A
A是一个
m
∗
n
m*n
m∗n的文本数据矩阵(
n
<
<
m
n<<m
n<<m),表示该语料包含
m
m
m个单词,
n
n
n篇文档。这
m
m
m个单词中肯定存在同义词等,这样一篇文档用
m
m
m维特征表示就显得冗余,不利于计算。利用矩阵奇异值分解:
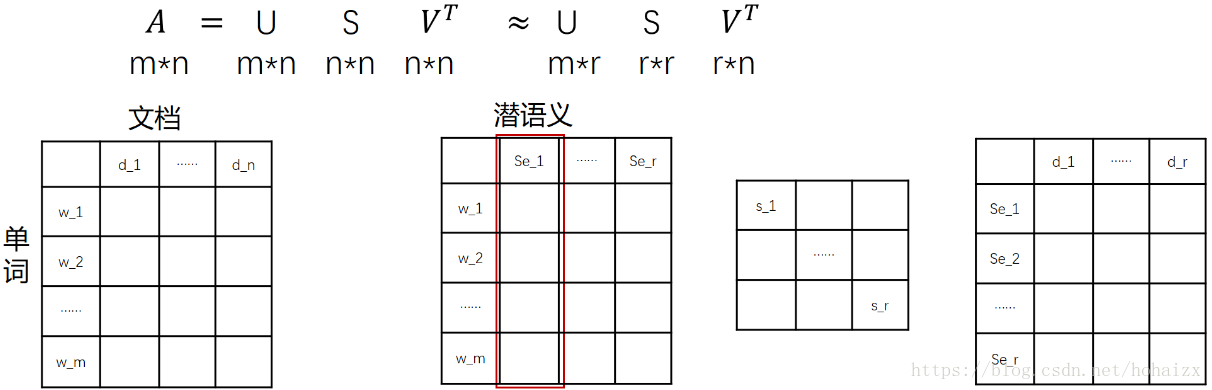
依据奇异值分解的性质1,矩阵
A
A
A可以分解出n个特征值,然后依据性质2,我们选取其中较大的r个并排序,这样
U
S
V
T
USV^T
USVT就可以近似表示矩阵
A
A
A。对于矩阵
U
U
U,每一列代表一个潜语义,这个潜语义的意义由m个单词按不同权重组合而成。因为
U
U
U中每一列相互独立,所以r个潜语义构成了一个语义空间。
S
S
S中每一个奇异值指示了该潜语义的重要度。
V
T
V^T
VT中每一列仍然是一篇文档,但此时文档被映射了语义空间。
V
T
V^T
VT的大小远小于
A
A
A。
有了
V
T
V^T
VT,我们就相当于有了矩阵
A
A
A的另外一种表示,之后我们就可以使用
V
T
V^T
VT代替
A
A
A进行之后的工作。
Example
借用LSA Tutorial上的例子,此时我们有单词文档矩阵如下:

这个矩阵的一行表示一个单词在哪些title中出现了(一行就是之前说的一维特征),一列表示一个title中包含哪些词,对这个矩阵进行奇异值分解,并选取奇异值最大的三项,得到下面矩阵:

表示我们将文档映射到了一个3维语义空间中,其中第一维潜语义可以表示为:
t
o
p
i
c
1
:
0.15
∗
b
o
o
k
+
0.24
∗
d
a
d
s
+
0.13
∗
d
u
m
m
i
e
s
+
⋯
+
0.25
∗
s
t
o
c
k
+
0.12
∗
v
a
l
u
e
topic 1:0.15*book+0.24*dads+0.13*dummies+\cdots+0.25*stock+0.12*value
topic1:0.15∗book+0.24∗dads+0.13∗dummies+⋯+0.25∗stock+0.12∗value
同时单词book在该语义空间中的向量表示为
(
0.15
,
−
0.27
,
0.04
)
(0.15,-0.27,0.04)
(0.15,−0.27,0.04)。此时title1在该语义空间中的向量表示是
(
0.35
,
−
0.32
,
−
0.41
)
(0.35,-0.32,-0.41)
(0.35,−0.32,−0.41)。然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:
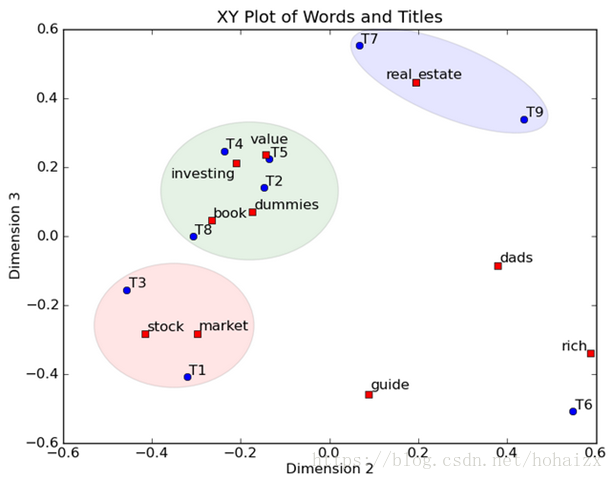
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一个title,这样我们可以对这些词和title进行聚类,比如stock和market可以放在一类,这也符合他们经常出现在一起的直觉,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。对于title,T1和T3可以聚成一类,T2、T4、T5和T8可以聚成一类,所以T1和T3比较相似,T2、T4、T5和T8比较相似。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
使用gensim工具包
Gensim工具包提供了一系列发现文档语义结构的工具,给定一篇文档,Gensim可以产生一些列与该文档相似的文档集合,这也是作者将其命名为Gensim(gensim = “generate similar”)原因。models.lsimodel提供了LSA实现。
from gensim.test.utils import common_corpus, common_dictionary, get_tmpfile
from gensim.models import LsiModel
# 构建LSA模型
model = LsiModel(common_corpus[:3], id2word=common_dictionary) # train model
# 将文档映射到语义空间
vector = model[common_corpus[4]] # apply model to BoW document
# 更新模型
model.add_documents(common_corpus[4:]) # update model with new documents
tmp_fname = get_tmpfile("lsi.model")
model.save(tmp_fname) # save model
loaded_model = LsiModel.load(tmp_fname) # load model
其中的关键是构建LSA模型
class gensim.models.lsimodel.LsiModel(corpus=None, num_topics=200, id2word=None, chunksize=20000, decay=1.0, distributed=False, onepass=True, power_iters=2, extra_samples=100, dtype=<type 'numpy.float64'>)
关键参数:
corpus:文本语料
num_topic:保留的语义维数
id2word:ID到单词映射
该对象包括如下方法:
LsiModel.projection.u,获得左奇异向量;
LsiModel.projection.s,获得奇异值;
add_documents(),用新的语料更新模型;
get_topics(),获取所有潜语义的向量表示;
save(),保存模型到本地;
load(),从本地加载模型;
print_topic(topicno, topn=10),以string的形式输出第topicno个潜在语义的前topn个单词表示;
print_topics(num_topics=20, num_words=10),以string形式输出前num_topics个潜在语义,每个语义用num_words个单词表示;
show_topic(topicno, topn=10),获取定义第topicno个潜在语义的单词及其贡献;















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









