







 本文介绍了如何创建数据集,包括标准数据集的使用、Transforms数据预处理、Dataloader数据加载以及Tensorboard数据可视化。通过实例演示了CIFAR-10数据集的处理和Ants Bee数据集的定制,展示了数据集组织与变换的重要性和Tensorboard在训练监控中的作用。
本文介绍了如何创建数据集,包括标准数据集的使用、Transforms数据预处理、Dataloader数据加载以及Tensorboard数据可视化。通过实例演示了CIFAR-10数据集的处理和Ants Bee数据集的定制,展示了数据集组织与变换的重要性和Tensorboard在训练监控中的作用。
参考视频
本博客参考b站up主“我是土堆”的视频:https://www.bilibili.com/video/BV1hE411t7RN?p=7
Dataset
训练神经网络肯定离不开数据集,数据集肯定都是我们准备好的。这里着重介绍下如何使用数据集。
数据集由两部分组成:数据和label
数据就是图片,label就是标签。比如我们的数据是一些蚂蚁的照片,那么label就是ants。lable主要取决于你的任务,你也可以label设置为红蚂蚁、黑蚂蚁等等类别。
实际代码中,我们为数据集写一个抽象类,可以方便的获取数据集里面的数据以及相关信息
假如我们现在已经下载好了数据集。目录如下:ants文件夹里面是蚂蚁的照片数据
Dataset:提供一种方式去获取数据及其label
- 初始化
__init__ - 获取每一个数据及其label
__getitem__ - 获得数据的总数(数据量)
__len__
ps:注意,在这个例子当中,数据就是ants文件夹下的图片,而label就是文件夹的名称。
from torch.utils.data import Dataset
import os
from PIL import Image
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir #根目录
# 这里单独列出来一个标签目录 其实是因为我们这里直接把文件夹目录设置为了label 这个放蚂蚁照片的文件夹名字就叫ants
self.label_dir = label_dir #把这个目录存下来 既是目录 也是我们训练当中的label
self.path = os.path.join(self.root_dir,self.label_dir) # 路径与目录拼接,得到数据路径
self.img_path = os.listdir(self.path) # 生成由该路径下所有文件的文件名组成的数组
def __getitem__(self, idx):
img_name = self.img_path[idx] # 获取第idx个文件的名字
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)# 与文件的路径拼接起来
img = Image.open(img_item_path) # 打开该图片
# label就是训练时候的标签,因为这里我们是直接把文件夹名字命名为了标签 这个文件夹叫ants 他的标签就是ants
label = self.label_dir
return img,label # 接收index索引 返回该图片和label
def __len__(self):
return len(self.img_path)# 列表的长度就是数据集的长度
root_dir = "hymenoptera_data/train"
# 创建蚂蚁数据集
ants_label_dir = "ants"
ants_dataset = MyData(root_dir,ants_label_dir)
# 创建蜜蜂数据集
bees_label_dir = "bees"
bees_dataset = MyData(root_dir,ants_label_dir)
# 还可以把两个数据集合成一个大的数据集
# 合成之后是按顺序的 蚂蚁数据集在前面蜜蜂数据集在后边 [0-123]是蚂蚁 [124-244]是蜜蜂
train_dataset = ants_dataset + bees_dataset
print(len(train_dataset)) # 输出长度为245
最后这里我们写好的数据集,如果想访问其中的第一个元素。那就
img,label = train_dataset[0]
img.show() #展示第一个图片
上面展示了数据集的一种形式。ants文件夹里面是蚂蚁,而文件夹名字就是label
此处举了一个简单的例子,展示了如何创建数据集。这里的label我们是通过直接获取文件夹名字来得到的。
而实际我们训练过程中,有可能label比较复杂,需要我们去设置,不能简单的把label当作文件夹名字了,就不能采用这种形式了
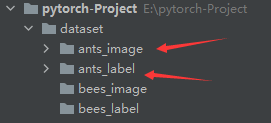
制作数据集:
我们把蚂蚁的图片存放到ants_image里面
然后在ants_label中用一个txt文件为每一个图片写label
如:图片文件夹里面是数据
label文件夹:里面是为每一个图片写的对应的label
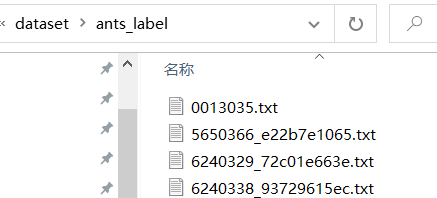
txt文件里面标记了每一个图的label
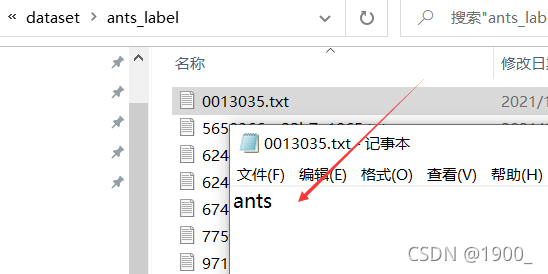
这个图像文件我们提前准备好,txt文件我们用代码生成:
代码如下
import os
root_dir = "dataset" # 拿到根目录
target_dir = "ants_image" # 拿到存放图片的目录
img_path = os.listdir(os.path.join(root_dir,target_dir)) # 拼接成路径 并拿到此路径下所有图片的名称 组成一个数组
label = target_dir.split('_')[0] # 从目录中拿出label 这里我们也可以自己设置label
out_dir = "ants_label" # 输出目录
for i in img_path: #遍历这些图片
file_name = i.split('.jpg')[0] #拿到图像名称 去掉“.jpg”
with open(os.path.join(root_dir,out_dir,"{}.txt".format(file_name)),'w') as f:
f.write(label) # 写入label
# 最后两行代码
# 里面是拼接路径的 把根目录 以及输出结果的目录 还有 文件名.txt 拼接到一起
# with open('dataset.txt','w') as f 打开文件进行写操作
注意:这个代码展示了如何自动生成对应的label文件,我们这里只是简单举了一个例子,所以每张图片的label我们还是通过获取文件夹的名字,分割字符串得到的ants。但是实际中,label那一行代码你可以自己设置。
标准数据集
可以打开官网,torchvision里面为我们提供了很多标准数据集。

我们可以直接使用这些标准数据集,同样的,用一个dataset来获取数据。
以CIFAR数据集为例子。
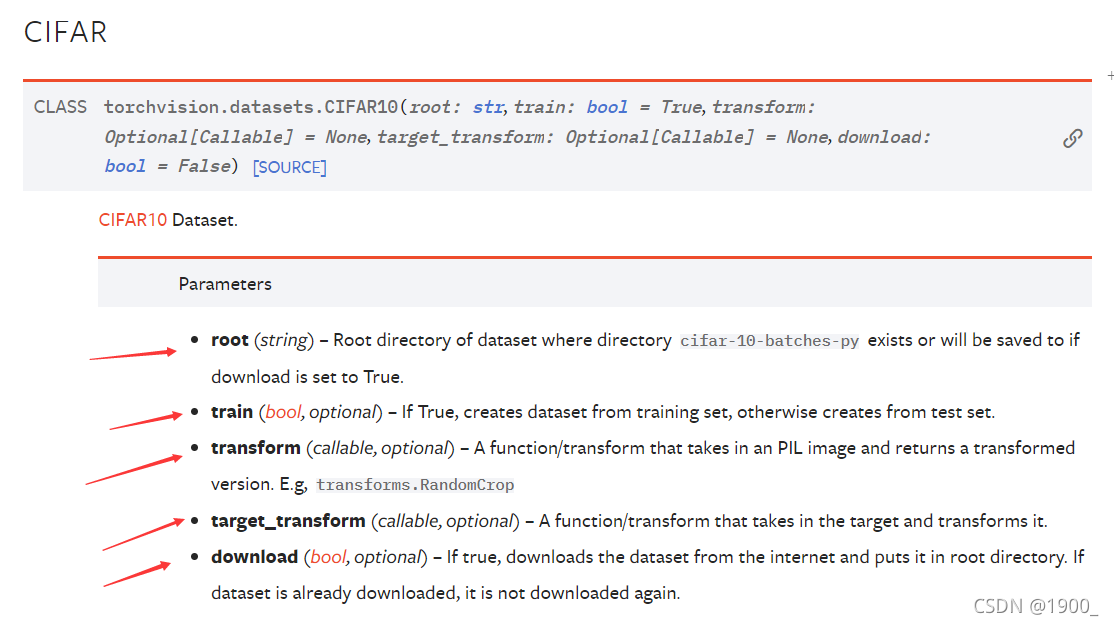
可以看到,官网文档定义了一些dataset的参数。
- root就是一个目录,指明我们的数据集要放在哪
- train 如果是True 就创建一个训练数据集,False就创建一个测试数据集
- transform 对数据集做一些transform,可以写在这里(transform后面会说,就是对数据做一些变化)
- target_transform 对target做一些transform
- download 为True就会从网上下载数据集,为False就不下载,那就需要提前准备好,放在root。注意:设置为True,如果你已经有了,按他也不会给你下载,所以建议一般写就设置为True即可
创建一个试试:
transform还没学,那我们暂时就不写,不对它进行任何变换
import torchvision
dataset = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,download=False)
# 看一下第一个数据
print(dataset[0])
输出结果:
(<PIL.Image.Image image mode=RGB size=32x32 at 0x1B486F06F88>, 3)
可以看到,输出了两项。第一个是一个图片img,后面还有一个3。
其实我们前面写dataset的时候,我们__getitem__也是返回两个值,一个是img,一个是label
那么这里其实也是一样的,3代表的就是label
我们可以打个断点看一下:
这个dataset被创建好了之后,里面有一项classes,里面有很多类别,飞机、狗、马之类的
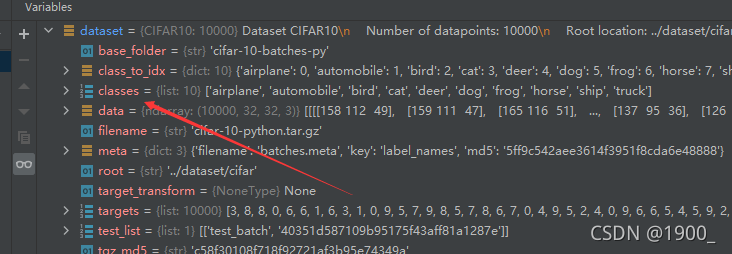
而这个3其实就是对应类别的下标。可以看到,第三个是cat,也就是这张图片是一只猫
我们可以验证下:
import torchvision
dataset = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,download=False)
img,target = dataset[0]
print(dataset.classes[target])
img.show()
输出:cat
并且展示了第一张图片(这可能看不清,因为这个数据集里面是32x32的小图片)

这个数据集里面包含了60000张32x32的图片,一共十个类别。可以看介绍:https://www.cs.toronto.edu/~kriz/cifar.html

Transforms
前面说dataset的时候,其实也提到过transforms。
transforms其实就是对图像做一些变换。
我们用dataset获取到的数据,想要输入神经网络中训练,一般还要做一些处理,用的就是transforms。
from torchvision import transforms
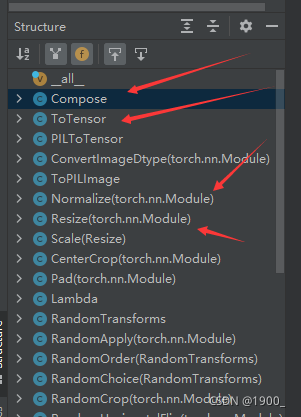
我们可以查看transforms.py的源码,就可以看到,里面写了很多类。
一个小技巧:点击左边的structure可以看到这个模块的结构(有点隐蔽)
我们可以看到这里面的类,我们对图像进行不同的处理,其实就是使用不同的类。
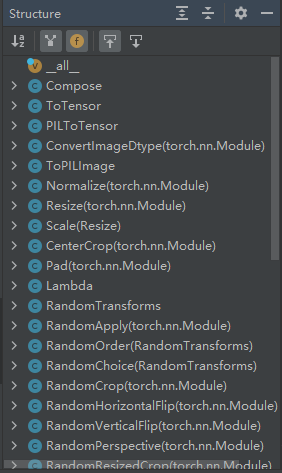
介绍几个我们常用的类:
ToTensor
你可以看,这些类的用法和注释都写得比较清楚
Compose
就是把多个处理操作合并到一起
比如:对图像先中心裁剪,在转化为Tensor类型。compose里面还可以写多个操作。
# Example:
transforms.Compose([
transforms.CenterCrop(10) # 中心裁剪
transforms.ToTensor() # 转换为Tensor类型
])
然后,这些常用的就是那几个。然后可以点进代码里面,里面写的有注释和使用样例。再不行了可以百度。这里就不说了,后面用到什么就查就完了。
Dataloader
Dataloader:为网络提供不同的数据形式(对数据打包)
dataloader的作用就是把数据加载到神经网络中,通过设置一些参数,可以设置每次从dataset中取数据,每次取多少,怎么取之类的。
一些参数: (摘自官网)
 可以看到,DataLoader需要传一些参数:
可以看到,DataLoader需要传一些参数:
- dataset: 传一个实例化的dataset
- batch_size:就是每次拿多少。DataLoader的作用就是为神经网络输入图像。batch_size=64,意思就是每次输入64张
- shuffle:这个的意思,举个例子,假如一共128张图片,batch_size=64,也就是说每次拿64个,两次就输入完了。那么实际我们训练当中,数据集不止训练一次,可能还会再输入一次。如果shuffle为False,那么第二次输入图片的顺序和第一次是一样的。如果是True,那就说明第二次取的顺序与第一次不一样。
- num_works 是说加载数据时使用的进程个数。默认是0,也就是主进程加载。多进程快一点
- drop_last:假如有10个图片,每次取3张,最后一次就只剩下一张了,drop_last等于True,就舍去后面的一张,不输入。若等于False,就最后一次只输入一张
写代码试试:
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,transform=torchvision.transforms.ToTensor(),download=False)
# 这里我们设置了一些我们上面讲过的参数
test_loader = DataLoader(dataset=dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
前面我们学dataset的时候知道,我们访问dataset中的第一个数据,会给我们返回两个值,一个是img,一个是target,也就是label
那么这里,数据到了dataloader里面,由于我们设置了batch_size=4。所以,会把四张图片打包,图片打包为imgs,标签打包为targets
写代码试试:
我们在代码里加点东西,把dataset第一张图片的类别输出一下看一下
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,transform=torchvision.transforms.ToTensor(),download=False)
test_loader = DataLoader(dataset=dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
img,target = dataset[0]
print("第一张图片类别"+str(target))
# 遍历 读取test_loader
for data in test_loader:
imgs, targets = data
print(imgs.shape) # 读取imgs大小
print(targets) # 读取targets
输出结果:
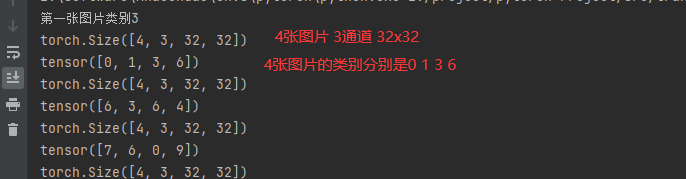
看结果可以发现,确实是把四张打包了。图片和target分别打包了
但是有个问题,可以看到dataset中第一个图片的类别是3,但是dataloader里面打包完了,第一个图片的类别是0.他们不一样。
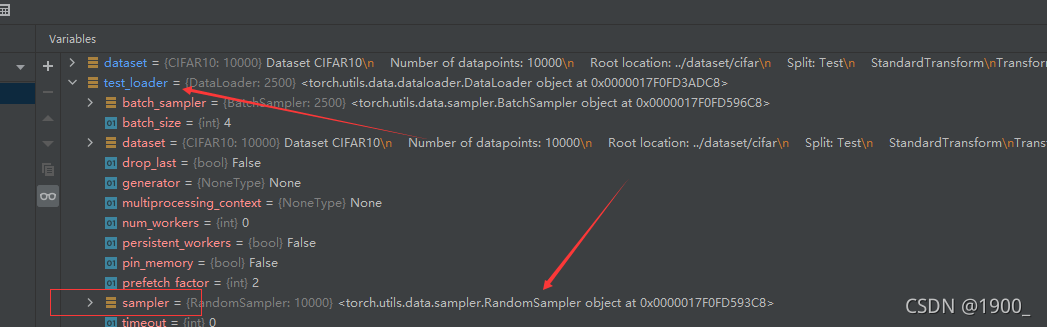
这是因为我们没有设置sampler
我们可以打个断点看下test_loader。可以看到,他有一个属性是sampler 采样器。默认使用的是随机采样 RandomSampler
所以并不是按顺序的,而是从数据集中随机拿四张
tensorboard
tensorboard是一个数据可视化的工具,可以用来方便的展示我们训练过程中的数据变化
导入库,初始化
from torch.utils.tensorboard import SummaryWriter
# 初始化
writer = SummaryWriter("logs") # 存储对应的事件文件
这个地方首先要pip安装tensorboard。如果安装完了,导入时候遇到报错:
from torch.utils.tensorboard import SummaryWriter导入不成功。
那么参考博客:https://blog.csdn.net/qq_28666313/article/details/106343611
我这里就遇到了这个问题,所以我安装了tensorboardX
我导入的包是
from tensorboardX import SummaryWriter
接下来说功能
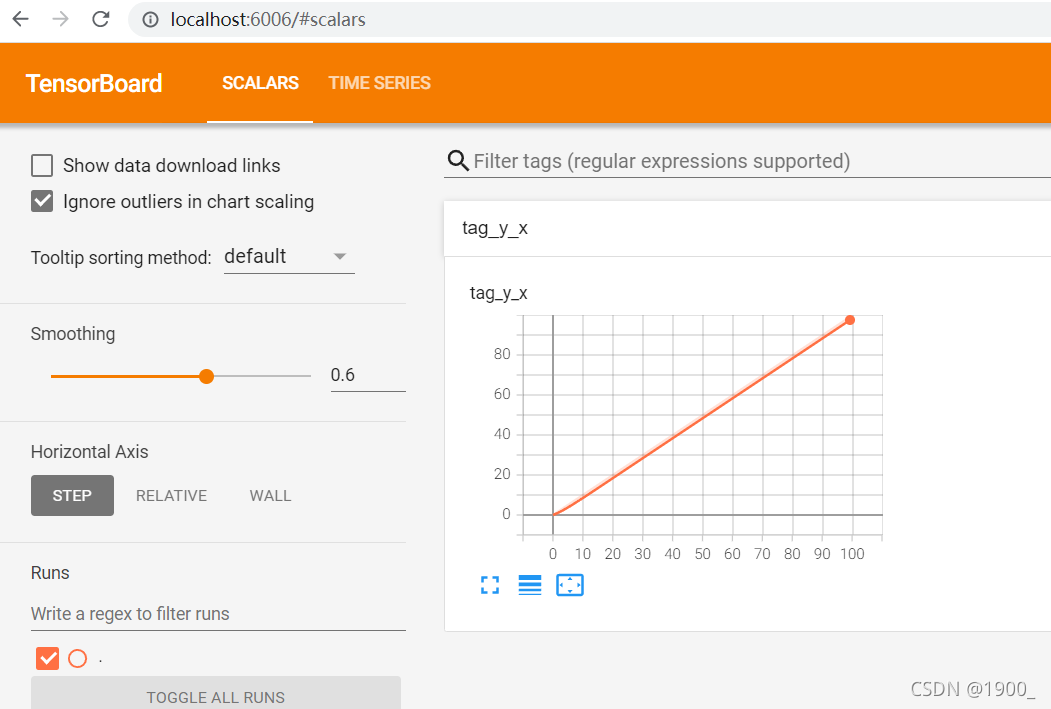
绘制数值图像我们使用add_scalar
可以看下这个函数的源码
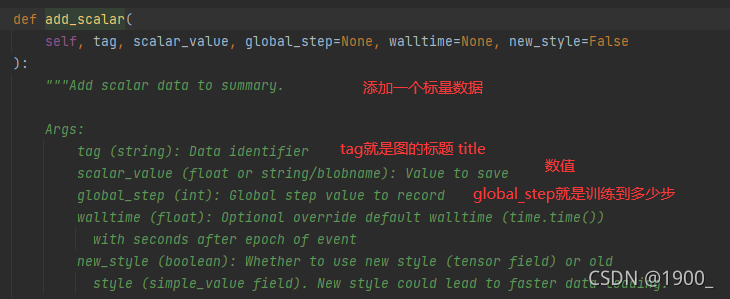
这个scalar_value其实相当于y轴
global_step其实相当于x轴
试一下:
from tensorboardX import SummaryWriter
# 初始化
writer = SummaryWriter("logs") # 存储对应的事件文件
# 展示数值
for i in range(100):
writer.add_scalar("tag:y=x",i,i)
writer.close() # 关闭
运行这段代码之后,会在你设定的文件夹logs下面生成事件文件。
注意这个文件夹位置,我的代码在src里面,所以我写代码的时候,给的路径是../logs
然后,在终端运行(要在log同级文件夹下)
tensorboard --logdir=logs
会出现这样的提示:

把这个链接复制到浏览器打开,即可看到
为了防止端口冲突,你也可以指定端口
tensorboard --logdir=logs --port=6007
这是绘制数值图像,当然我们也可以查看图像。
from tensorboardX import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("../logs") # 存储对应的事件文件
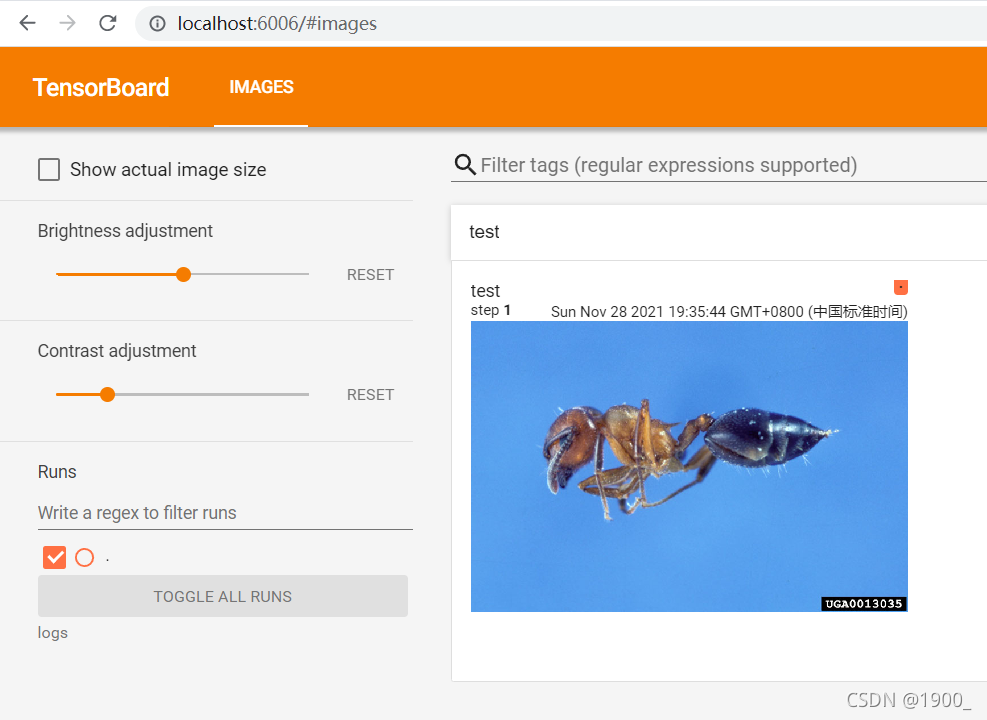
# 需要先把图像转成numpy.array类型
image_path = "../dataset/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
# 接收的图像只能是这几种类型 : torch.Tensor, numpy.array, or string/blobname
# 后面加参数是因为 需要指定shape格式 必须是HWC 具体可以点进这个函数去看 写的有注释
# global_step 设置为1
writer.add_image("test",img_array,1,dataformats='HWC')
writer.close()
刷新页面可以看到图片
(注意:有的时候刷新看不到,或者还是之前的图。
解决办法:
1、把logs文件夹里面的删除了,再进行别的图片的显示
2、显示别的图片的时候,新建个文件夹
3、终端重新执行一下tensorboard --logdir=logs
官方推荐的是不同的文件放在不同的文件夹下)
那么我们会了tensorboard的基础操作
我们尝试结合前面学的dataloader
我们把每一步取的数据展示出来
import torchvision
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
# 准备好数据集 并且全部转化为Tensor类型
test_data = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,transform=torchvision.transforms.ToTensor(),download=False)
# 设置好dataloader
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
writer = SummaryWriter("../logs")
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("test_data",img_tensor=imgs,global_step=step)
step =step + 1 # 每次取64个 每次步骤加1
writer.close()
终端输入:
tensorboard --logdir=logs
我们打开那个地址

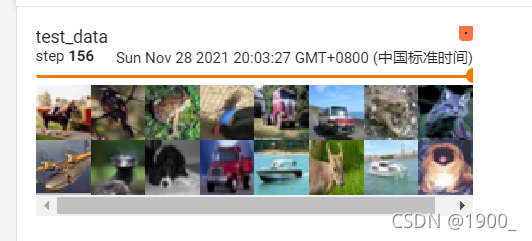
可以看到每一步都是64张图片,鼠标可以拉,查看每一步
我们可以看到最后一步,这个比较特殊,因为剩下的不够64张了,所以只取了这么点
前面我们讲过,如果把drop_last设置为True。那么最后不够64就会舍去,不取了
我们设置一下试试
我们可以看到,第一次进行了156步,第二次只有155 步,并且最后一步取了64张图片
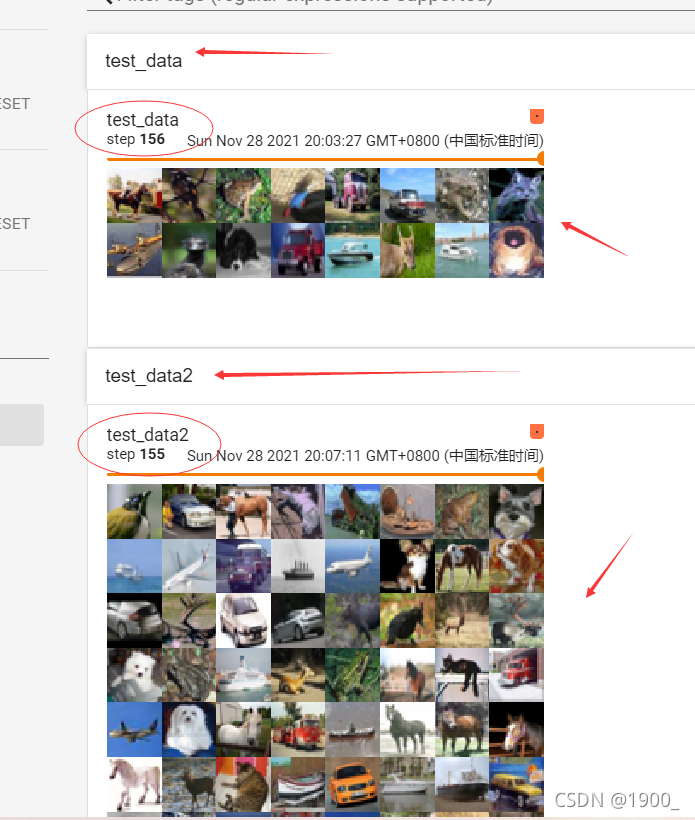
最后再说一下dataloader里面的那个shuffle
之前我们说过,shuffle为False,那么第二次取图片的顺序和第一次是一样的。若为true,就不一样
我们来改下代码,验证一下
import torchvision
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
# 准备好数据集 并且全部转化为Tensor类型
test_data = torchvision.datasets.CIFAR10("../dataset/cifar",train=False,transform=torchvision.transforms.ToTensor(),download=False)
# 设置好dataloader
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=True)
writer = SummaryWriter("../logs")
for epoch in range(2): # 取两轮图片
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("Epoch:{}".format(epoch),img_tensor=imgs,global_step=step)
step =step + 1 # 每次取64个 每次步骤加1
writer.close()
首先当shuffle=False的时候
可以看到,epoch0和epoch1是一模一样的

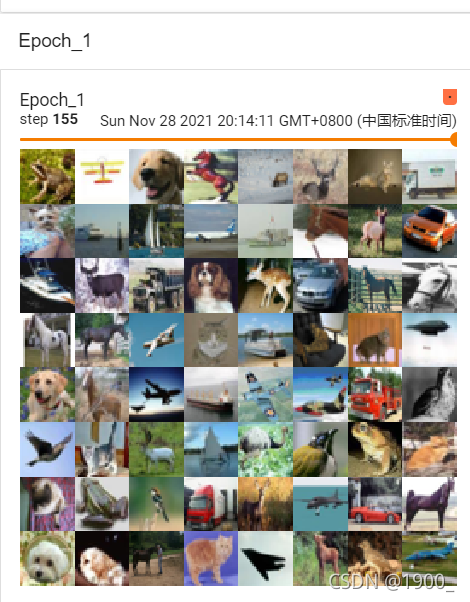
我们把shuffle改为True试试(直接改True,add_images里面的参数不变,也就是还是epoch0和epoch1,他就会覆盖咱们上面运行的那个)
可以看到,都是第155step,图片确是不一样的




















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











